
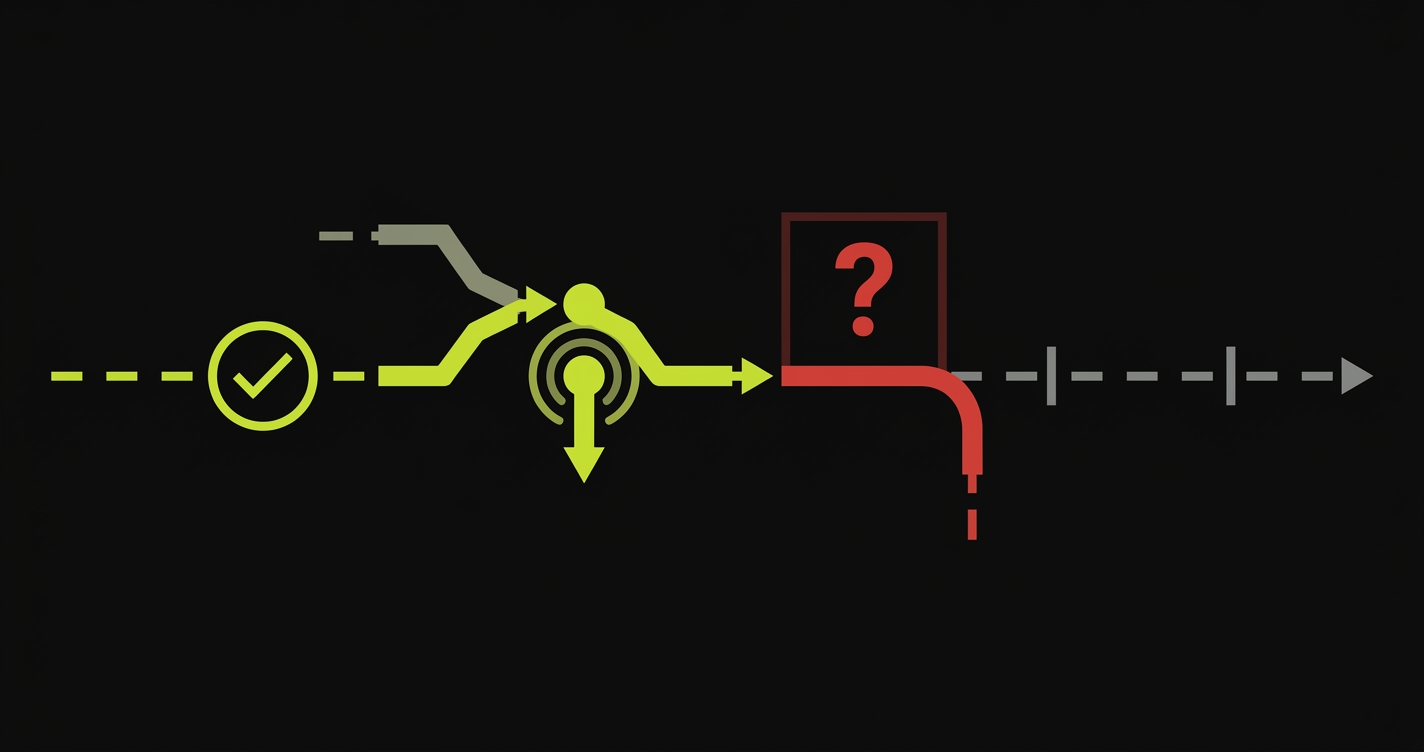
AI subagent merge conflicts occur when multiple AI coding agents (Claude subagents, Codex workers, or similar) run in parallel on the same repository, each producing a pull request, and those PRs modify overlapping code paths. When the merge happens, the resolving agent picks a winner, but it has no semantic understanding of what the losing agent intended to build. Features disappear. Bugs appear. And because no human wrote the conflicting code, no human instinctively notices what's missing.
Teams running 5 or more parallel AI subagents are experiencing delivery delays they can't explain. The sprint looked clean. The PRs all passed CI. And then the demo revealed a checkout flow that no longer worked, a permission model that had reverted, or an API endpoint that silently accepted requests it should have rejected. Nobody introduced a bug intentionally. The subagents just didn't know about each other.
Why Parallel Subagents Create More Merges Than Humans Ever Did
The promise of AI-pilled development is real: spin up 10 subagents, parallelize everything, and compress a two-week sprint into two days. And it does compress: the code generation rate increases dramatically. But the merge rate increases at exactly the same ratio, and the quality of merge reasoning does not.
A human engineer who wrote a feature knows the intent behind it. When they hit a merge conflict, they resolve it by understanding both sides. They know whether the incoming change is compatible with theirs. They can call the other engineer and ask.
A subagent resolving a conflict knows neither side's intent. It sees the diff and it picks the version that looks more recent, more complete, or more syntactically coherent. The feature the other agent built is not "deleted" in any observable way. It simply stops existing. No error. No test failure. No log entry. The code merges cleanly, the pipeline goes green, and the missing behavior waits to be discovered by a customer.
Consider a realistic scenario: you have five subagents working in parallel on a SaaS product. Agent A is adding role-based access to the settings page. Agent B is refactoring the permissions service to improve performance. Agent C is adding audit logging that hooks into the same permissions service. All three are working from the same main branch snapshot, taken before any of them pushed a line.
When Agent B finishes and merges first, the permissions service changes are now in main. When Agent A's PR merges second, its changes to the settings page are based on the old permissions service API. The merge either breaks the settings page or silently reverts parts of Agent B's refactor. Agent C's PR, meanwhile, has audit logging hooks that reference a method that Agent B renamed. The hooks compile but call a no-op. Audit logging appears to work. It records nothing.
Three agents, three clean PRs, three green CI runs. One broken product that took two days to debug.
The Failure Mode Nobody Is Talking About
The engineering community has spent considerable energy discussing whether AI-generated code is correct in isolation. That's the wrong frame. The output of a single subagent is usually fine. The problem is emergent and relational: it lives in the spaces between agents, not inside any one of them.
Traditional merge conflict tools were designed for human-speed development. When engineers are merging daily, they intuitively understand the shared context of their team's work. They review each other's PRs. They overhear conversations. They notice when something that was there yesterday is gone today.
Subagents don't attend standups. They don't review each other's code. They operate from a frozen snapshot of the repository and have zero awareness of what any parallel agent is building. Their PRs can be syntactically compatible and semantically broken at the same time.
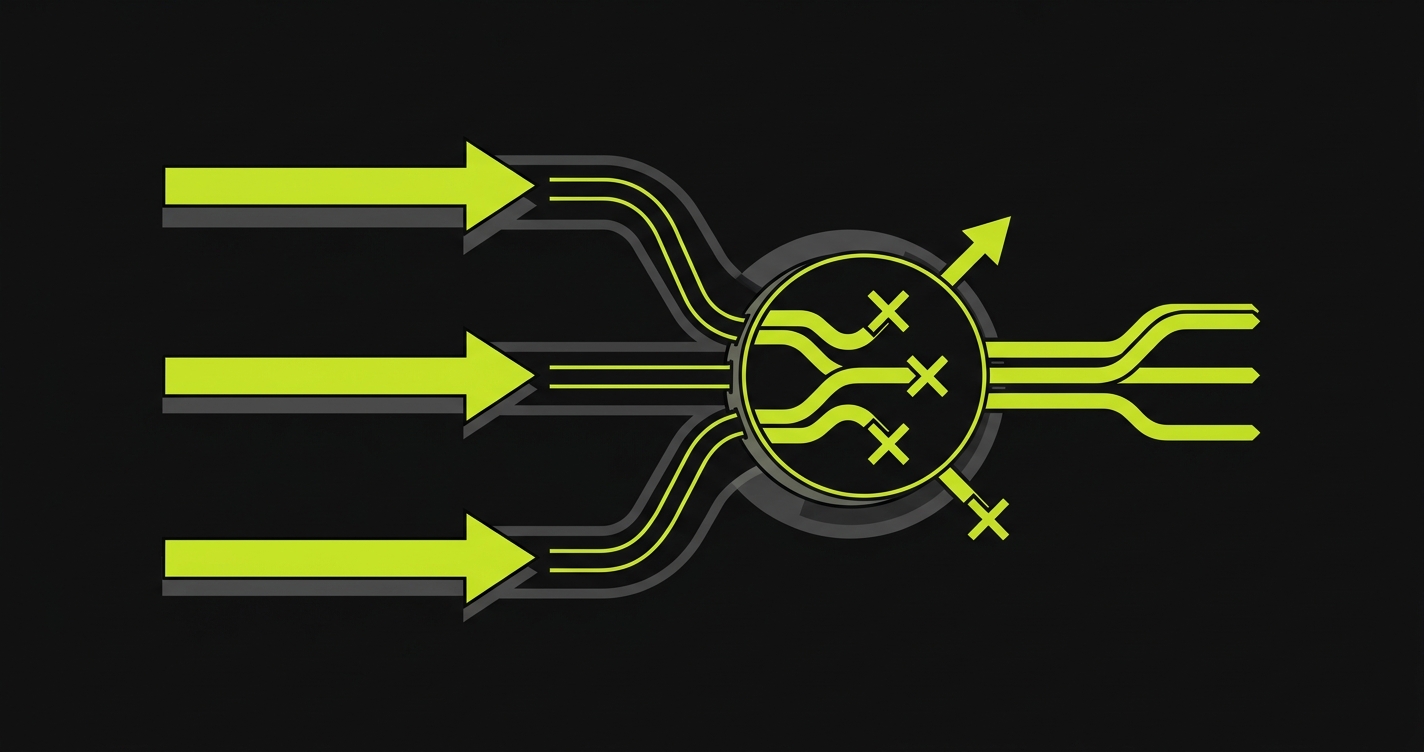
There's also the sequencing problem. In human development, the order of merges is somewhat random but the intent is visible. When Agent A merges before Agent B, the subsequent merge resolution has to decide what "correct" looks like without any context about what was intentional. The agent doing the resolution will make the safest textual choice, not the correct semantic one. And the safest textual choice frequently discards the newer feature in favor of the more established one.
Teams that have moved fastest to AI-first development are the ones most exposed to this. The faster you parallelize, the more your subagents are working from stale snapshots, and the more merges are resolving conflicts with zero domain knowledge.
What the Bugs Look Like in Practice
The bugs that come out of subagent merge conflicts are particularly hard to triage because they don't look like bugs. They look like features that were never built.
Your PM opens a ticket: "The export button doesn't filter by date range anymore." No stack trace. No error in Sentry. The button works, the export completes, but the filtering is gone. You check git blame on the export service. It was last touched by a subagent merge three days ago. You check the PR. Clean. Approved. Green.
The date range filtering was implemented by one subagent and silently overwrote by another that also modified the export service for an unrelated reason. Neither agent knew the other existed.
This is why the delivery delay accumulates in a way that's hard to forecast. Individual tasks complete on time. The integration phase is where the time disappears. You're not debugging code that's wrong. You're reconstructing behavior that was right once and is now inexplicably absent.
| Traditional merge bugs | Subagent merge bugs |
|---|---|
| Compile error or test failure surfaces immediately | Code compiles, tests pass, behavior is silently wrong |
| Git blame traces to a specific human decision | Git blame traces to a merge commit, with no human intent visible |
| Developer remembers writing the conflicting code | No developer wrote either side, no institutional memory |
| Conflict is visible in the PR diff | Conflict was resolved before the PR was created |
| Post-merge review catches most regressions | No reviewer knows what "correct" looked like before the merge |
How Autonoma Catches What Subagents Miss
The resolution to this problem is verification that operates at the behavioral layer, not the code layer. Static analysis and unit tests validate individual functions in isolation. They cannot validate that the interaction between two independently-built features produces the right behavior end-to-end.
Autonoma runs automated end-to-end tests against every preview deployment, triggered by every PR merge. It doesn't need to know which subagent wrote what. It validates the deployed behavior against what the application is supposed to do. When Agent A's permissions work and Agent B's settings page break them, Autonoma catches the integration failure before it reaches production.
The key difference is that Autonoma tests behavior in the deployed environment, not in the source code. By the time a subagent merge has happened, the code-level evidence of what was lost is often unrecoverable. But the behavioral failure (the export button that stopped filtering, the permission check that stopped firing, the audit log that went silent) is immediately observable in a running application.
For teams running parallel subagent workflows, this means every PR merge triggers a verification pass against the full application behavior. Not just the changed files. Not just the feature the PR was supposed to add. The whole deployed product.
The Right Mental Model for AI-Pilled Development
If you're running 5-10 parallel subagents, you're not running a development team anymore. You're running a code generation pipeline. And like any pipeline, the value of what comes out depends entirely on the quality gate at the end.
Human development teams evolved PR review, pairing, and standups as coordination mechanisms. They worked because humans had shared context and could communicate intent. Subagents have none of those properties. The coordination mechanism for subagent workflows has to be automated, behavioral, and post-merge, not conversational and pre-merge.
The teams that are getting this right are the ones who treat verification infrastructure as a prerequisite to subagent parallelism, not as an afterthought. They don't ask "did this agent produce correct code?" They ask "does this deployed application do what we committed to the customer?"
That's the question Autonoma is built to answer, at the speed subagent development requires.
What to Do Right Now
If you're running parallel AI subagents today and you don't have automated behavioral testing on every merge, you have a gap. The gap grows proportionally with the number of parallel agents you're running.
Practically, this means: before you scale to 10 parallel subagents, make sure you have a verification layer that tests the deployed application after every merge. Not synthetic tests. Not unit tests. End-to-end behavioral tests running against a real preview environment.
Second: treat your merge queue as a serialization point. Parallel generation is fine. Parallel merging is where the problems compound. Merge sequentially, test after each merge, and let the verification results determine whether the next merge is safe.
Third: when a behavioral regression is found, don't ask the subagent to fix it without first understanding which merge introduced it. The subagent that caused the problem had correct code. The problem is the interaction, and fixing the interaction requires a human decision about which behavior was intended.
Autonoma integrates into your CI and makes automated behavioral verification on every merge something you can add in an afternoon. The rest is about building the discipline to act on what it tells you.
When multiple AI coding agents (like parallel Claude subagents or Codex workers) work on the same repository simultaneously, each produces a pull request based on an older snapshot of the codebase. When these PRs merge, the resolving agent picks between conflicting changes without understanding what either agent intended to build. Features disappear, bugs appear, and the code compiles cleanly.
Unlike human engineers, subagents have no awareness of what parallel agents are building. When two agents modify overlapping code and one merges first, the second agent's changes are resolved against the new state without semantic understanding. The merge tool picks the 'winner' textually, not semantically, and the losing agent's feature stops existing without any error.
Traditional merge conflicts surface as compilation errors or test failures that a human resolves with context. Subagent merge conflicts are often invisible: the code compiles, CI passes, and the missing behavior is only discovered when a customer notices the feature is gone. There's no human institutional memory of what 'correct' looked like before the merge.
Autonoma integrates into your CI and runs end-to-end behavioral tests per PR in an isolated preview environment, either one Autonoma provides or your own. It validates the full deployed application behavior, not just the changed files. When a subagent merge silently drops a feature or breaks an integration, Autonoma catches it before it reaches production, without needing to understand which agent wrote what.
No, parallel subagents are genuinely powerful and the speed gains are real. The answer is to add a behavioral verification layer that keeps pace with the merge rate. Treat verification infrastructure as a prerequisite to subagent parallelism, not an afterthought. The more agents you run, the more important it is to test the deployed application after every merge.



