
GDPR compliance testing means your test environments must never contain unmasked personal data from real users. Under GDPR Articles 5 and 25 (data minimisation and privacy by design), personal data should only be processed for the purpose it was collected. Using a live production snapshot in staging or CI violates that principle. The practical fix is a masking pipeline: strip or transform PII before it reaches any non-production environment. What you can use in tests: masked copies of production data, synthetic data, or anonymized exports. What you cannot use: raw production exports, live production database connections, or any dataset where real individuals could be re-identified.
Enterprise security reviews have gotten longer. What used to be a two-page questionnaire is now a 90-question spreadsheet, and somewhere around row 47 there is a question about what GDPR test data lives in your non-production environments. CTOs who answer "a masked copy of production" move on. CTOs who answer "usually a prod snapshot, but we restrict access" get a follow-up call with the customer's security team.
That follow-up call is where deals slow down. Not because the customer is being unreasonable, but because GDPR compliance testing hygiene is now a basic expectation at any company with a security team, and a vague answer signals that you have not built the controls yet.
This is the practical problem the rest of this article solves. Not the theoretical GDPR exposure, which is real but abstract. The immediate problem is a sales motion that stalls because you cannot demonstrate that your test data pipeline is clean.
Why Test Environments Are the Highest-Risk GDPR Surface
Production is where you think the risk lives. It isn't. Production usually has access controls, audit logs, and at least some attention from whoever manages infrastructure security. Staging and CI environments are where the exposure actually accumulates, quietly, over years.
The pattern is almost universal at Series A companies. One engineer needed realistic data to debug a payment edge case. They took a prod snapshot. It worked. The snapshot stayed in the staging database. Other engineers started relying on it. New CI pipelines got seeded from the same source. The data got stale but nobody deleted it. Six months later, your staging database has the emails, phone numbers, and transaction records of your first thousand customers, and nobody in your organization has a clear picture of how much PII is in there or how long it has been sitting there.
GDPR Article 5 requires that personal data is "adequate, relevant and limited to what is necessary." Article 25 requires privacy by design: you should be engineering data minimization into your systems from the start, not treating it as an audit-time concern. Article 32 reinforces this by requiring "appropriate technical and organisational measures" for security of processing, explicitly naming pseudonymisation as one such measure. Using live customer data in test environments fails all three principles.
The DPA fines are significant: up to 4% of annual global turnover or 20 million euros, whichever is higher. But for startups approaching GDPR compliance testing for the first time, the more immediate risk is what happens during enterprise sales. Security reviews now routinely ask about non-production data handling. A CTO who can answer "our test environments use masked data only, and here is the pipeline that generates it" is in a very different position than one who says "we usually use a production copy."
What Counts as Personal Data in Your Test Environments
Before you can mask anything, you need to know what you are protecting. The obvious fields are names, email addresses, phone numbers, physical addresses, and dates of birth. These appear in almost every user table, and they are the easy ones to catch.
The harder ones are fields that aren't obviously PII but become PII in context. IP addresses are personal data under GDPR. User-agent strings combined with timestamps can be used to identify individuals. Free-text fields (support tickets, notes, comments) frequently contain PII typed in by users or your own team. Financial data (card last four digits, bank account numbers, transaction histories) is both personal data and often covered by additional regulations. Health or demographic data entered in forms is special category data under Article 9, which carries stricter handling requirements.
For a typical SaaS startup, the highest-risk tables are: users and accounts (core PII), payment records (financial data), activity logs (behavioral data linked to identifiable users), and any table that stores user-generated content. A useful exercise is to run a column-level audit: for every table that gets copied into your test environment, tag each column as PII, derived PII, or safe. This takes a few hours and gives you a clear scope for your masking pipeline.
The Three GDPR Test Data Approaches, and When to Use Each
There are three practical ways to handle GDPR test data. They are not equally good for all situations, and most teams end up using a combination.
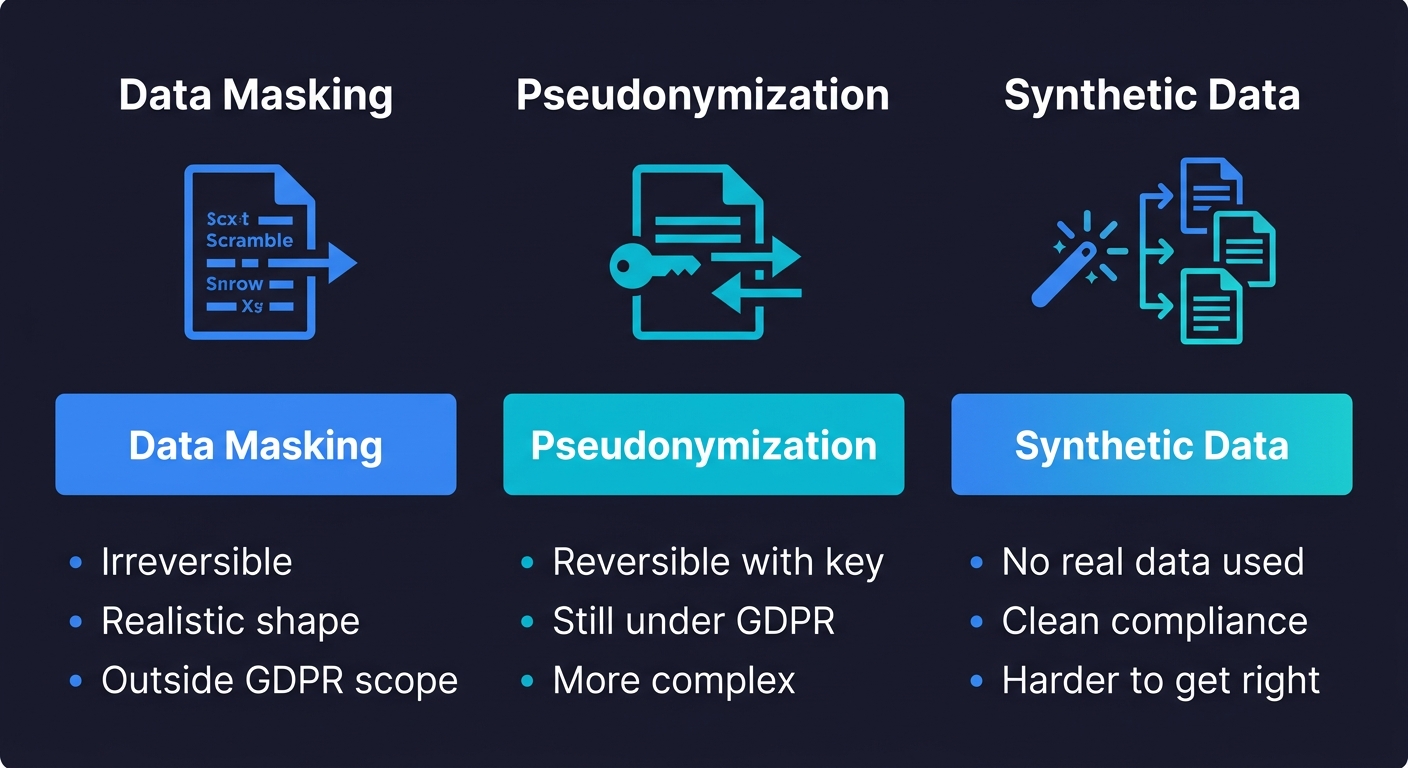
Masking replaces real values with fake-but-realistic ones. An email like alice@example.com becomes user_4829@testdomain.com. A phone number becomes a randomly generated string that passes format validation. Masking preserves structural integrity: referential constraints still hold, record counts are the same, edge cases and distribution are preserved. This is the right choice when you need realistic data volume and shape for testing complex business logic.
Pseudonymization replaces identifiers with reversible tokens. The real value is stored separately, encrypted, and can be recovered if you have the key. This adds operational complexity, and most startups don't need it for test environments; masking is sufficient.
The critical legal distinction here: truly anonymized data falls entirely outside GDPR scope under Recital 26, meaning no GDPR obligations apply to it at all. Pseudonymized data, by contrast, remains personal data under GDPR because re-identification is possible if the key is compromised. For test environments, this means that a properly masked dataset where the original values cannot be recovered gives you the cleanest compliance position.
Synthetic data generation skips production data entirely and creates realistic fake records from scratch. This is the cleanest option from a compliance perspective because no real user data ever leaves production. The tradeoff is that synthetic data is harder to get right: you need realistic distributions, edge cases, and referential integrity, none of which come for free. Synthetic data works well for new feature development against clean schemas, but it is less reliable when you need to reproduce a production bug that only occurs with real data patterns.
One more distinction worth knowing: data masking for testing comes in two forms. Static data masking creates a permanently altered copy of production data, which is what the pipeline in this article produces. Dynamic data masking obscures data in real-time based on who is querying it, which is useful in production for limiting what support staff can see but is not what you need for test environments. For test data pipelines, static masking is the right approach because it guarantees that PII never exists in the test environment at all, rather than relying on query-time filters that could be bypassed.
For most startups, the practical answer is: mask production data for integration and regression testing environments, and supplement with synthetic data for unit tests and new feature development. Our data anonymization guide covers the tools for each approach in depth.
Building the Data Masking Pipeline for Test Environments
A test data masking pipeline has four stages. Each is straightforward individually; the challenge is wiring them together into something that runs automatically.
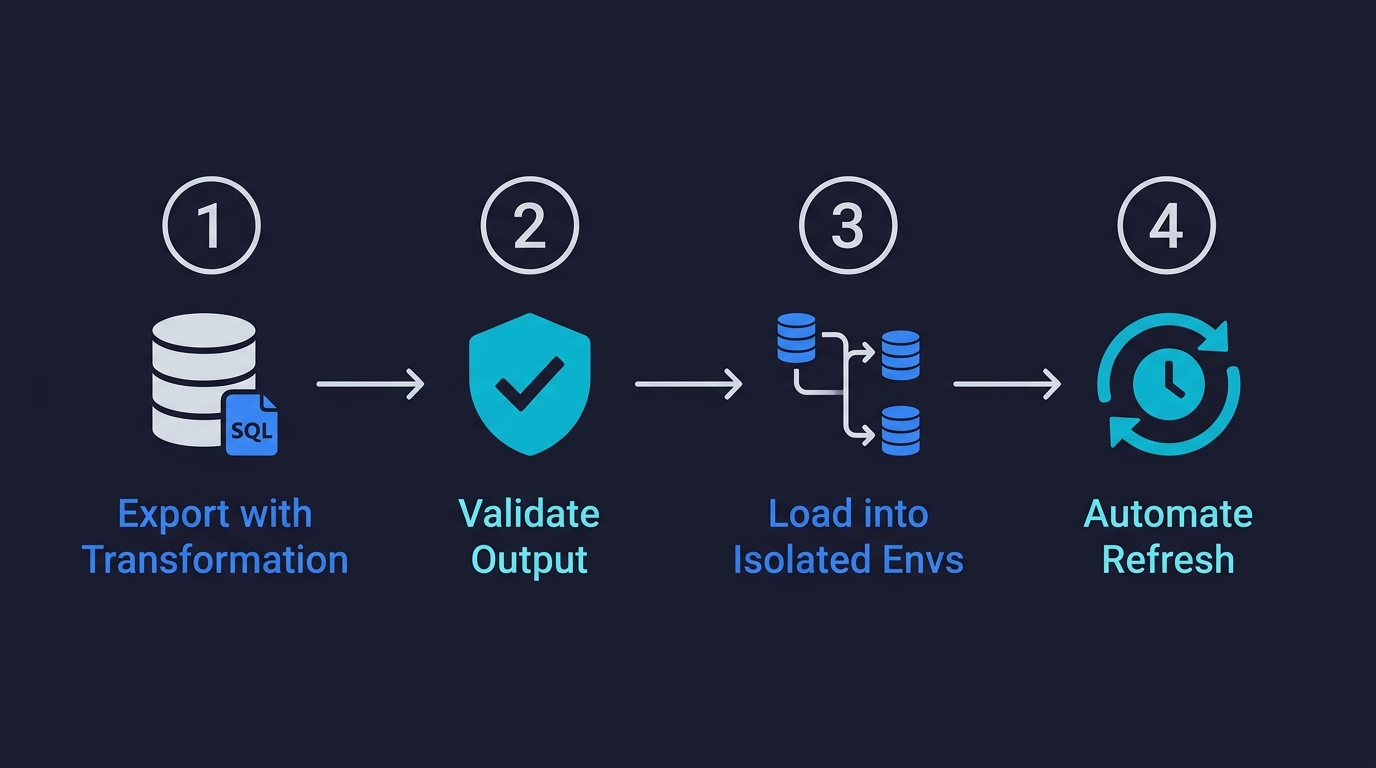
Stage 1: Export with a transformation query. The cleanest approach is to never dump raw production data at all. Instead, write an export query that applies transformations at the database level during the export. For Postgres, this looks like a COPY command with a SELECT that calls masking functions inline:
COPY (
SELECT
id,
md5(email::text) || '@testdomain.com' AS email,
'User ' || id AS name,
regexp_replace(phone, '[0-9]', '5', 'g') AS phone,
created_at,
subscription_tier,
'cus_' || left(md5(stripe_customer_id::text), 14) AS stripe_customer_id,
plan_id
FROM users
) TO '/tmp/masked_users.csv' CSV HEADER;This means the PII never exists in an unmasked state outside of production. The export file is safe from the moment it is created.
Stage 2: Validate the output. Before the masked export reaches any test environment, run a validation pass. At minimum, check that no column that should be masked still contains real email patterns (@yourdomain.com), real phone formats, or real names from a known-names dictionary. This catches bugs in your masking logic, and it gives you an audit trail proving the validation happened.
Stage 3: Load into isolated test environments. This is where database branching becomes valuable. Rather than a single shared staging database that gets refreshed periodically, you can use a branching tool like Neon or PlanetScale to create isolated per-environment copies from the masked export. Each branch is independent: a migration on one branch doesn't affect others, test data doesn't bleed between runs, and you can tear down and recreate environments cheaply. Our database branching guide walks through the Copy-on-Write mechanics that make this fast.
Stage 4: Automate the refresh cadence. A masked snapshot that is six months old is not a compliance problem, but it is a test quality problem. Schema drift accumulates. New edge cases that exist in production don't exist in your test data. Automating a weekly or bi-weekly refresh of the masked export keeps your test environments representative without requiring manual work. The pipeline runs in CI, validates the output, and loads the result into your branched test environments.
For the actual masking tools, the open-source options worth evaluating are postgresql-anonymizer (for Postgres, applies masking rules via a declarative rules file), Faker-based scripts (for flexible programmatic masking in Python or Node), and Presidio from Microsoft (for detecting and masking PII in free-text fields). Our data anonymization guide includes a full comparison of these tools.
GDPR Test Data Compliance Checklist
This is the checklist to work through before your next enterprise security review or compliance audit. It maps to actual GDPR testing requirements rather than generic security advice.
| Requirement | What to Check | Status Signal |
|---|---|---|
| Data minimisation (Art. 5) | No raw production PII in any test environment | Masking pipeline exists and runs automatically |
| Purpose limitation (Art. 5) | Test data used only for testing, not analytics or demos | Separate data stores per environment purpose |
| Privacy by design (Art. 25) | Masking enforced at export, not applied manually per engineer | Automated pipeline, not a manual step in runbooks |
| Data retention (Art. 5) | Test environments don't retain old masked exports indefinitely | Refresh cadence defined; old snapshots deleted on rotation |
| Special category data (Art. 9) | Health, biometric, political, and religious data fields identified and excluded from test envs | Column audit completed; special category fields restricted |
| Processor agreements (Art. 28) | Third-party CI and test tools have Data Processing Agreements in place | DPAs signed with GitHub Actions, test infra vendors, etc. |
| Cross-border transfers (Art. 46) | US-based CI tools processing EU data have Standard Contractual Clauses in place | SCCs included in vendor DPAs; data flow diagram shows transfer paths |
| Accountability (Art. 5(2)) | Records of what data sits where and what pipeline produces it | Data flow diagram exists and is current |
The last row is worth calling out specifically. Article 5(2) requires accountability: you have to be able to demonstrate compliance, not just achieve it. A masking pipeline that runs silently and leaves no trace is better than nothing, but a masking pipeline that produces logs, validation reports, and a data flow diagram you can hand to an auditor is what actually closes the enterprise deal.
GDPR Testing Shortcuts That Create Real Risk at Startups
A few patterns are extremely common at pre-seed and Series A companies. They seem harmless but create genuine GDPR exposure.
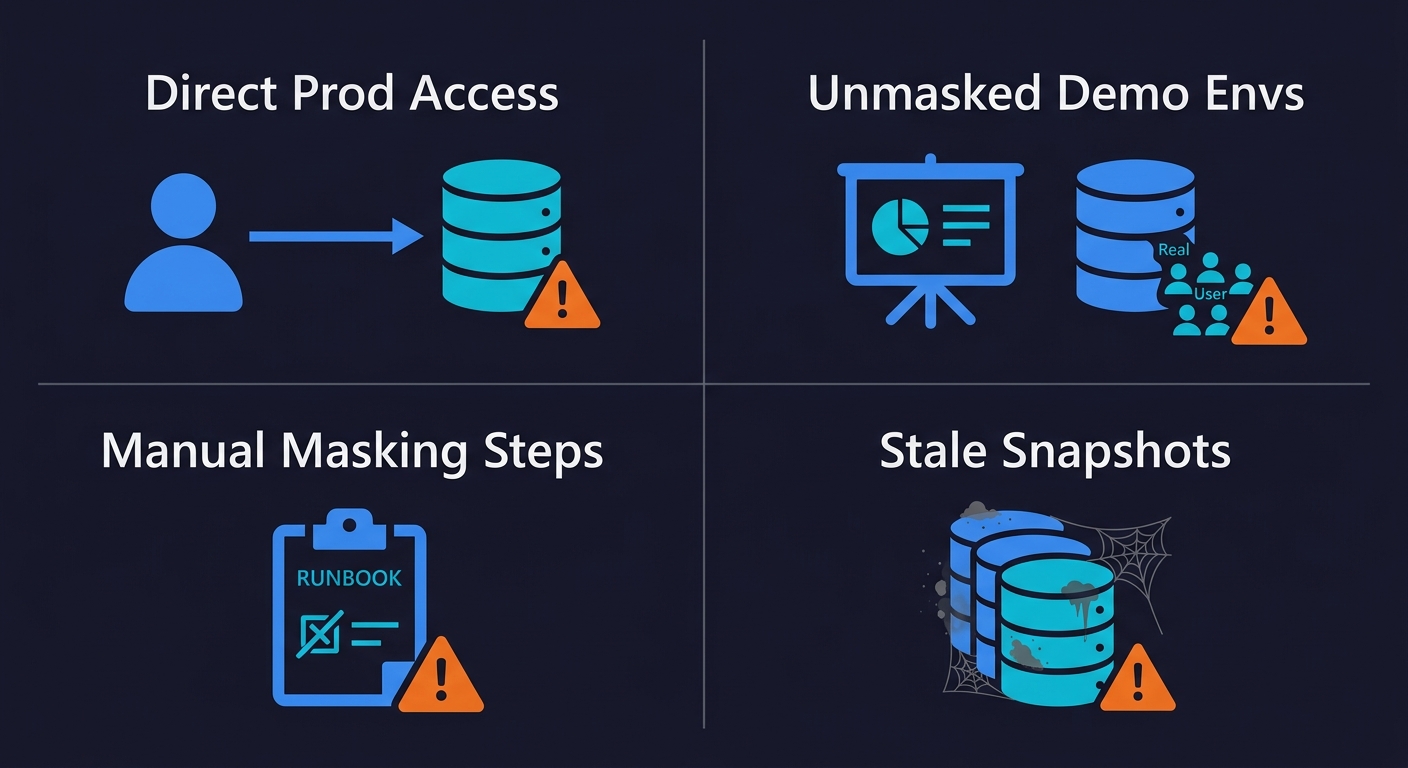
Giving engineers direct production read access for debugging is done for speed. The risk is that any data extracted for local debugging becomes uncontrolled. The better pattern: give engineers access to a masked copy of the relevant records, not direct production access. Some teams set up a "debug snapshot" workflow where a masked subset can be requested on demand via an internal tool.
Using production data in demo environments is another common gap. Demo environments get shown to prospects, shared with partners, and sometimes left running with no access controls. All of that real user data is now uncontrolled.
Manual masking in runbooks is not a compliance process. "Before copying the database, remember to run the masking script" is a reminder that will be skipped under pressure. Masking needs to be enforced at the infrastructure level, not relied on as a manual step.
Keeping old snapshots around is the quietest risk. Disk space is cheap, so old production snapshots accumulate. A snapshot from 18 months ago contains data that may include users who have since exercised their right to erasure, and it is probably not covered by whatever masking process you added later. Automated rotation that deletes old snapshots on a defined cadence is the fix.
Connecting GDPR Compliance Testing to Your Infrastructure
Building GDPR compliant test environments is not just a legal checkbox. It is part of a broader test data management practice that determines how fast your team can ship safely.
The masking pipeline is the foundation. Once it exists and runs automatically, you can layer database branching on top to give every PR its own isolated copy of that masked data. You can generate synthetic edge cases to complement it. And when an enterprise prospect asks about your data handling practices, you have a real answer backed by infrastructure rather than a promise.
The two things that matter most here are automation and documentation. Automation because compliance that relies on engineers remembering to do things correctly will fail. Documentation because GDPR requires you to demonstrate accountability, and a data flow diagram plus pipeline logs are what that looks like in practice.
Tools like Autonoma generate and execute tests automatically from your codebase, which means they need realistic test data to work with. A clean masking pipeline feeding isolated environments is what makes that possible without the compliance risk.
Not directly. GDPR requires that personal data is only processed for the purpose it was collected (purpose limitation, Article 5) and that you implement privacy by design (Article 25). Using raw production data in test environments violates both principles. You can use production data as a source, but it must be masked, anonymized, or pseudonymized before it reaches any non-production environment. Tools like Autonoma, postgresql-anonymizer, and Faker-based scripts make this practical to automate.
GDPR compliance testing is the practice of ensuring your software test environments, processes, and pipelines meet GDPR requirements. The core requirement is that non-production environments (staging, CI, development) must not contain unmasked personal data from real users. It involves implementing a data masking pipeline, auditing your test data sources, ensuring data processing agreements are in place with test tooling vendors, and documenting your data flows to satisfy GDPR's accountability principle.
The best data masking tools for GDPR compliance testing include: postgresql-anonymizer (declarative masking rules for Postgres, applied at the database level), Faker libraries in Python or Node (for programmatic masking in custom export scripts), Microsoft Presidio (for detecting and masking PII in free-text fields), and Neosync (a newer open-source option with a UI for defining masking rules). The right choice depends on your database type and whether you need to handle unstructured text. Our full comparison is available in the data masking tools guide.
A weekly or bi-weekly refresh is a practical cadence for most startups. More frequent than that and you are adding pipeline overhead without significant quality benefit. Less frequent than monthly and your test data drifts too far from production schema and data distribution to catch real bugs. The more important thing is that the refresh is automated, not manual, and that old snapshots are deleted on rotation to avoid retaining stale PII copies longer than necessary.
Yes. GDPR applies to any environment where personal data from EU residents is processed, regardless of whether that environment is production, staging, CI, or a local developer machine. The key question is whether the data can identify a real individual. If the answer is yes, GDPR applies and you need a legal basis for processing. For test environments, the cleanest approach is to ensure the data never meets that threshold, which masking and synthetic data generation both achieve.
The risks are both regulatory and commercial. On the regulatory side, using unmasked production data in staging without a valid legal basis and appropriate safeguards can result in fines from your local Data Protection Authority (up to 4% of annual global turnover or 20 million euros, whichever is higher). On the commercial side, enterprise prospects now routinely ask about non-production data handling in security reviews. A startup that cannot explain its test data practices will lose deals to competitors who can.



