
The Demo Day customer problem: YC founders need signed customers, or at minimum deep pilots in progress, before Demo Day to show traction to investors. That means shipping features fast enough to win deals while also making sure bugs don't surface during the evaluations that investors will ask about. The teams that solve this don't slow down to do QA. They get surgical: protect the path the customer walks during the pilot, ship everything else at full speed, and use automated coverage to catch the bugs that cost deals before the customer does.
The YC playbook on customers is unambiguous: get them before Demo Day. Real revenue, or at minimum real pilots with real companies, changes the investor conversation from "this sounds promising" to "here's the evidence." The difference between raising at a $10M valuation and a $25M valuation is often just one or two signed customers who can confirm that the product works and they're paying for it.
The playbook is also silent on a problem that shows up consistently in the six weeks before Demo Day: founders who are shipping fast enough to win deals but who then lose them to bugs that surface during the evaluation.
Therefore: the question worth answering is not how to ship faster. It's how to ship fast and make sure that the features you're shipping to win deals don't break the deals you've already got running.
The Demo Day Math That Nobody Does Explicitly
Let's be specific about the timeline, because it shapes everything.
YC batches run roughly 12 weeks. Demo Day is at the end. The investor conversation window, where your traction numbers, actually change your valuation and term sheet, starts about two weeks before Demo Day, when the partner group starts doing initial diligence on companies in the batch.
Working backward: to have a signed customer for Demo Day, you need to close by week 10. To close by week 10, you need a pilot that started by week 7 and resolved cleanly. To start a meaningful pilot by week 7, you need to be running sales conversations by weeks 4-5. And to run sales conversations in weeks 4-5, you need a product that is stable enough to demo by week 3.
That's the real timeline. Week 3 is when the product needs to be demo-stable. The batch starts in January or June. Week 3 is three weeks in. For most YC companies, week 3 is when they're still figuring out what they're building.
This is why the Demo Day customer problem is hard. It's not a sales problem. It's a sequencing problem where you're shipping new features in weeks 5-10 to win the pilot customers you need, and every feature you ship is a potential bug that surfaces in one of the evaluations you're running simultaneously.
How Shipping Fast Creates a Specific Bug Pattern
The relationship between shipping velocity and bugs is not linear. Teams that ship slowly have fewer bugs because they have time to catch them before they reach production. Teams that ship fast have more bugs, but they catch them faster too because the feedback loop is tighter. That's the standard trade-off, and it's largely manageable.
What is less well understood is that shipping fast during active customer pilots creates a specific failure mode that doesn't exist in the normal product development cycle.
Here's how it plays out. You're running two pilots. Pilot A started three weeks ago and is going well. Pilot B just started this week. You're in the middle of building a feature that Pilot C's prospect specifically asked for, the feature that might convert them from interested to pilot. You ship the feature on Thursday night.
On Friday morning, Pilot A's champion logs in and discovers that their saved report configurations are gone. Not a new feature. Not something you touched intentionally. A side effect of the database migration you ran to support the new feature.
You fix it by Friday afternoon. But the champion already spent 45 minutes re-configuring everything manually and sent you a slightly concerned Slack message. You're now two weeks from Demo Day, your most advanced pilot just had an incident, and you need this person's company to be a customer you can reference with investors.
This is not bad luck. It is the predictable consequence of shipping features to win new customers while running active pilots with existing ones. The same urgency that creates the opportunity also creates the risk.
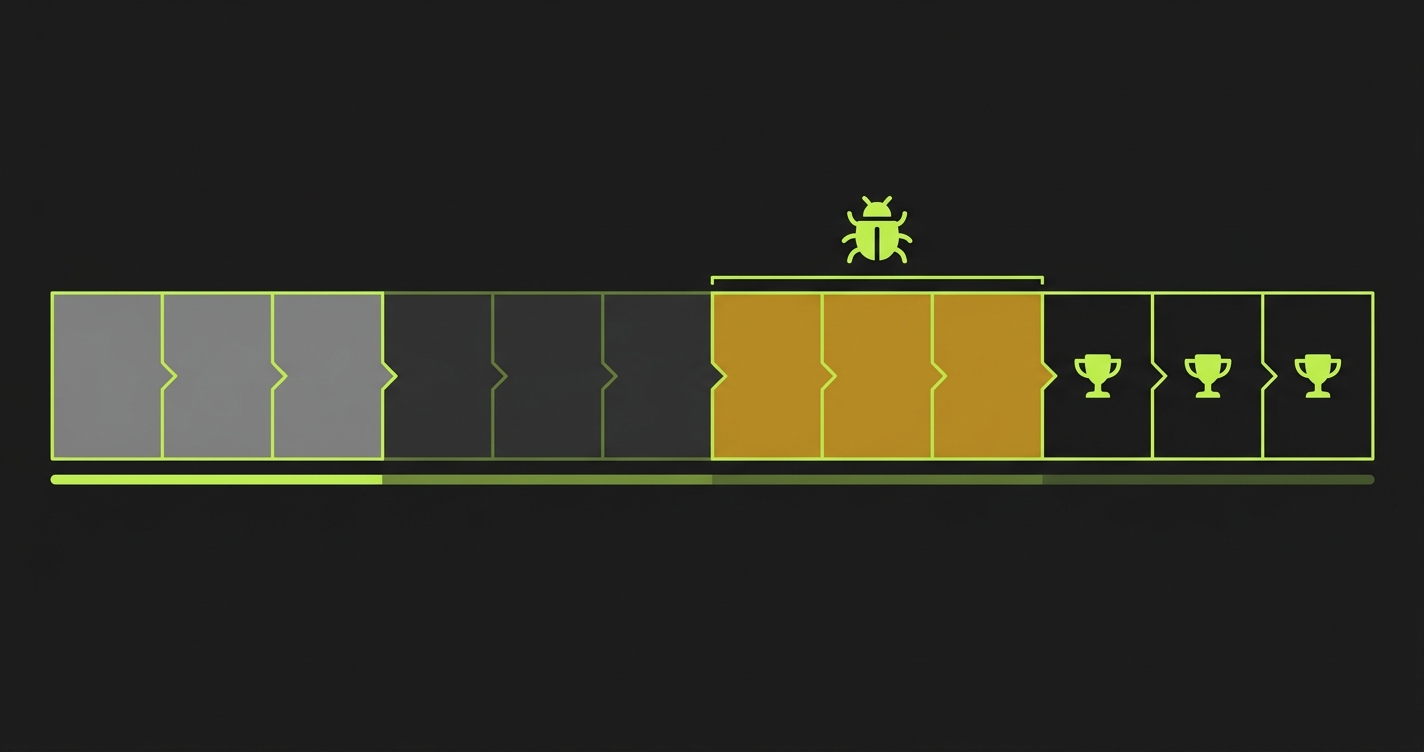
The "Protect the Deal" Framework
The founders who consistently close customers before Demo Day have solved this problem with a specific mental model: separate what you're shipping from what your pilot customers experience.
This sounds obvious. In practice, most teams don't do it.
The default mode is: we ship to production, pilots see it immediately, we fix issues as they come up. Fast, simple, and fine when you have one pilot and a close relationship with the champion. Not fine when you have three pilots in progress, one of them at a company where your champion's job is at stake, and another at a company where the decision-maker specifically mentioned reliability as a concern during the intro call.
The alternative: before any deployment reaches a pilot customer's environment, run a focused set of automated checks on the paths those customers actually walk. Not a full regression suite. Not comprehensive QA. A targeted check on three to five flows that, if broken, directly affect the evaluations in progress.
The check is small. The impact is large. You ship the Friday night feature, the check runs, and one of your assertions fails: the saved configurations test is broken. You see it at 11 PM. You roll back or hotfix before your pilot customer's Monday morning session. The incident never happens.
What to Automate in the 8-Week Pre-Demo Day Sprint
The framing of "build a test suite" is wrong for the Demo Day context. You don't have time to build a test suite. You have time to write the four tests that protect the four pilots you're running.
Think of it as one test per active pilot relationship, covering the specific path that customer takes. Not the same generic test for everyone. The specific flow they're evaluating.
For a pilot evaluating your core workflow: one test that logs in as a user in their account configuration, runs the primary workflow, and asserts the output is correct and present.
For a pilot using a specific integration: one test that verifies the integration is connected, data is flowing, and the relevant output reflects the current data state.
For a pilot that's specifically evaluating reliability (because they told you that during the sales call): one test that runs the core workflow multiple times and checks for consistency across runs.
For all pilots: one test that verifies authentication works across the entry paths you've told them to use. If you told them to log in via Google, the test uses Google. If you set up SSO for their domain, the test hits SSO.
// Example: Pre-deploy protection suite for a YC company with 3 active pilots
// Run these before every deployment that reaches production
// Core workflow protection (all pilots)
test('core workflow: process and output intact', async ({ page, request }) => {
await page.goto('/login')
await page.fill('[data-testid="email"]', process.env.TEST_PILOT_EMAIL!)
await page.fill('[data-testid="password"]', process.env.TEST_PILOT_PASSWORD!)
await page.click('[data-testid="login-submit"]')
await page.waitForURL('/dashboard')
// Core workflow
await page.click('[data-testid="new-run"]')
await page.waitForSelector('[data-testid="run-complete"]', { timeout: 45000 })
const result = await page.locator('[data-testid="run-summary"]').textContent()
expect(result).not.toMatch(/error/i)
expect(result).toMatch(/complete/i)
})
// Saved state protection (critical for pilots with configured environments)
test('pilot state: saved configurations persist across deploys', async ({ request }) => {
const response = await request.get('/api/user/configurations', {
headers: { Authorization: `Bearer ${process.env.TEST_PILOT_TOKEN}` }
})
const data = await response.json()
expect(response.status()).toBe(200)
expect(data.configurations).toBeInstanceOf(Array)
expect(data.configurations.length).toBeGreaterThan(0) // Saved configs must persist
})
// Integration health (for pilots using specific integrations)
test('integration: data source connected and flowing', async ({ request }) => {
const response = await request.get('/api/integrations/status', {
headers: { Authorization: `Bearer ${process.env.TEST_PILOT_TOKEN}` }
})
const status = await response.json()
expect(status.connected).toBe(true)
expect(status.last_sync_error).toBeNull()
expect(new Date(status.last_sync_at).getTime()).toBeGreaterThan(
Date.now() - 24 * 60 * 60 * 1000 // Synced within last 24 hours
)
})These tests run in under two minutes. They run on every pull request. They catch the class of bugs, broken workflows, lost state, disconnected integrations: these surface during pilot sessions and cost deals.
For teams that want this protection without writing and maintaining Playwright tests while also shipping features, Autonoma generates and maintains critical path coverage from your codebase automatically. You define which flows matter for your pilots; Autonoma covers them before every deploy.
How to Structure Pilot Timing Around Your Shipping Velocity
Beyond testing, there is a sequencing strategy that reduces the collision between new feature shipping and active pilot risk.
The key insight: the most dangerous deployment is the one that happens when you have a pilot customer who has not yet completed their first independent session. That first session is when impressions form, when the champion decides whether to invest more time in the evaluation, and when they form the story they'll tell internally about the product. A bug during that session has an outsized effect relative to a bug in week three of a pilot.
This suggests a deliberate staging strategy: when you onboard a pilot customer, identify the first 48-72 hours as a stability window and avoid deploying during it unless you have a critical fix. After the first session is complete and the customer has had a positive initial experience, your failure modes are less catastrophic. They've seen the product work. A subsequent bug is an incident in an ongoing relationship, not a first impression.
The stability window does not mean you stop shipping. It means you time your deploys. Ship before the onboarding call. Then hold for 48 hours. Resume shipping normally after the champion has completed their first solo session.
This costs you almost nothing. A 48-hour window in a fast-shipping team is one sprint cycle. Shipping a breaking change four hours before a pilot customer's first solo session because you're pushing to close another deal, is how pilots fail.
The Investor Conversation Your Customers Will Have
Here's a frame that is useful for thinking about this entire problem. When investors talk to your pilot customers as part of diligence, and they will, for the good ones, ask one question more than any other: how has the product worked in practice?
The answer to that question is shaped almost entirely by whether something broke during the evaluation and how the team handled it. An investor talking to a reference customer who says "there was a rough patch in week two, but they caught it fast and were proactive about it" is hearing a story about a team that runs a tight ship. An investor talking to a reference customer who says "it was pretty buggy during our pilot, took them a while to figure it out" is hearing a story about a team they should think twice about backing.
The product does not need to be perfect. Reference customers understand that early-stage products have rough edges. What they evaluate, and what investors are actually asking about when they call references, is whether the team operates in a way that is trustworthy at scale. A team that catches bugs before customers do signals operational maturity. A team where customers are the bug detection system signals the opposite.
Your pilot coverage strategy, in other words, is not just a product quality decision. It is an investor relations decision that plays out through your customers.
The Operations Stack for Running Pilots at Demo Day Velocity
The full picture of what makes pre-Demo Day pilots survivable is not just automated tests. It is a thin stack of operational practices that fit together.
Pre-deploy critical path tests. As described above. The gate that catches deal-breaking bugs before they reach production. Required baseline.
Error monitoring on the critical path. When your tests pass but something goes wrong in production, and it will, because tests don't cover everything, you need to know before your pilot customer does. Tools like Sentry or Datadog, configured to alert on errors specifically in the flows your pilot customers use, give you the early warning needed to fix and communicate before a complaint arrives.
Pilot status tracking. A simple document or Notion page that lists each active pilot, their current stage, their champion's name, and the last time you had a signal from them. Updated after every customer interaction. This is not CRM: it's operational awareness. It tells you which pilots are in the 48-hour stability window, which are at decision points, and which have gone quiet and need a nudge.
A weekly pilot review. Every Monday, ten minutes, review each active pilot. What happened last week? What's planned for their next session? Any deployments scheduled that touch their critical path? This review is where you catch sequencing problems before they become incidents.
None of this is heavy process. It is the minimum operational infrastructure for running multiple customer evaluations in parallel without losing track of who is where and what they're experiencing.
What "Signed Before Demo Day" Actually Requires
The goal of all of this is signed contracts that you can show investors. Not pilots still in progress. Not positive conversations. Signed contracts.
Getting a pilot to a signature in the Demo Day timeline requires a pilot that starts clean, progresses without major incidents, reaches a decision moment, and then closes. Pilots that have incidents in the middle can still close, but they close slower and with more work from you, which is time you don't have.
The math on time matters here. A pilot that should close in four weeks closes in six if there is a mid-pilot incident that requires relationship recovery. Six weeks is outside your Demo Day window if you started the pilot in week 7. The same pilot that closes perfectly closes in four weeks, which puts you at week 11: right in time.
The difference between "we almost closed before Demo Day" and "we closed three customers before Demo Day" is often not the quality of the product or the strength of the sales motion. It is whether incidents happened during pilots that slowed the close cycle. Protecting your pilots from bugs is not a nice-to-have engineering practice. It is the operational practice that determines whether your Demo Day story is "we're working on closing our first customers" or "we closed three customers and here's what they said."
Investors know the difference. So do their LPs.
Getting Started This Week
If Demo Day is in the next eight weeks and you have pilots running or about to start, here is the minimum viable version of what to do this week.
Map the critical path for each active pilot: the exact steps that customer takes from login to their primary value moment. Write one automated test per pilot covering that path. Get those tests running in CI on your main branch.
This takes a day of engineering time. Less, if you use Autonoma to generate the coverage from your codebase. The alternative is discovering, in week nine, that a week-seven deployment broke a pilot you needed to close. That discovery costs you Demo Day traction.
One day of investment. Three deals protected. That is the trade-off.
Frequently Asked Questions
The Demo Day customer timeline runs backward from the investor conversation window: to have a signed customer at Demo Day (week 12), you need to close by week 10, start a meaningful pilot by week 7, and run sales conversations by weeks 4-5. The constraint is not sales motion, it's pilot quality. Pilots that have incidents close slow. Pilots that run cleanly close fast. Getting automated coverage on the specific paths your pilot customers walk is the operational practice that prevents the incidents that add weeks to your close cycle. Every week lost to a pilot incident is a week you don't have in the Demo Day timeline.
The outcome depends entirely on whether you found it or the customer found it. If you find it first via automated monitoring or pre-deploy tests, you fix it and communicate proactively: 'We noticed an issue and deployed a fix, let us know if you're seeing anything.' That reads as operational maturity. If the customer finds it first, you're in relationship recovery mode, which takes days you don't have. The practical answer: instrument your critical path with automated tests and error monitoring so you are always first to know when something breaks in a pilot.
Protect the path, not the product. Your pilot customer walks a narrow path through your product during their evaluation: login, setup, core action, output. Automated tests covering that specific path run before every deployment and catch breaks before they reach production. Everything else in your product, secondary features, admin panels, edge case flows: these ship at full velocity without the gate. The gate is surgical, not comprehensive. You do not slow down. You protect the part of the product that decides the deal.
Not in the traditional sense. Traditional QA (comprehensive test suites, dedicated QA engineers, full regression before every release) is inappropriate for a team of four trying to ship features fast enough to win Demo Day customers. What is appropriate is targeted critical path coverage: automated tests on the three to five flows your pilot customers actually walk, running before every deployment. This is a fraction of the investment of traditional QA and directly protects the outcomes that matter. Write three tests, run them in CI, protect your deals. Comprehensive QA comes later.
Three things make multiple simultaneous pilots survivable: automated critical path coverage for each pilot (one test per pilot, covering their specific evaluation path), error monitoring on the flows they use (so you know before they do when something breaks), and a simple pilot status document reviewed weekly (to track which pilots are in stability windows, which are at decision points, which need nudges). Without automated coverage, multiple pilots in flight means you are relying on customers to be your bug detection system, which is how pilots slow down right when you need them to close.
For a startup with no QA team and active customer pilots, the right strategy is automated critical path coverage, not comprehensive testing. Map the path your pilot customer walks (entry, setup, core action, value confirmation). Write one end-to-end test covering that path. Write auth state tests for every login method you've offered. Write output assertions for what your product generates. Run these in CI before every deployment. This covers the bugs that cost deals and skips the testing overhead that slows development. Tools like Autonoma can generate and maintain this coverage from your codebase automatically, removing the test maintenance burden from a team that needs its engineering time for shipping.



