
The preview environment lifecycle is the sequence of infrastructure operations that automatically provisions a full, isolated copy of your application when a pull request opens and tears it down when it closes: six stages spanning trigger detection, image build, service replication, routing and secrets, URL exposure with access control, and teardown, each with distinct operations work, failure modes, and cost surfaces.
Every time a developer opens a pull request against your main branch, something has to provision a complete, isolated copy of your running application. Not a static preview of the frontend. The actual running application: API, database, queues, workers, cache layers, the whole stack. It has to be reachable at a unique URL, populated with the right secrets, protected so random internet traffic doesn't hit it, and destroyed cleanly when the PR closes.
That sequence doesn't happen by itself. Someone has to build it, wire it up to your CI pipeline, and keep it running. This article maps the full preview environment lifecycle as an operations problem, stage by stage, so you know exactly what your team is taking on.
The Provisioning Lifecycle as an Operations Problem
The per-PR orchestration sequence is typically described as a feature: "every PR gets its own environment." That description obscures what it actually costs to run.
What you are really running is ephemeral infrastructure lifecycle management. Each PR triggers a creation event. Each merge or close triggers a destruction event. Between those two events, your platform keeps a full application stack alive, routed, and accessible. Multiply that by the number of open PRs at any given time and you have a fleet of short-lived environments with overlapping lifecycles, each at a different stage.
The complexity is not in any single stage. It is in managing the full lifecycle reliably, at scale, without someone babysitting it.
There are six stages. Each has defined inputs and outputs. Each has specific failure modes that block the stages downstream. Each drives cost in a different way.
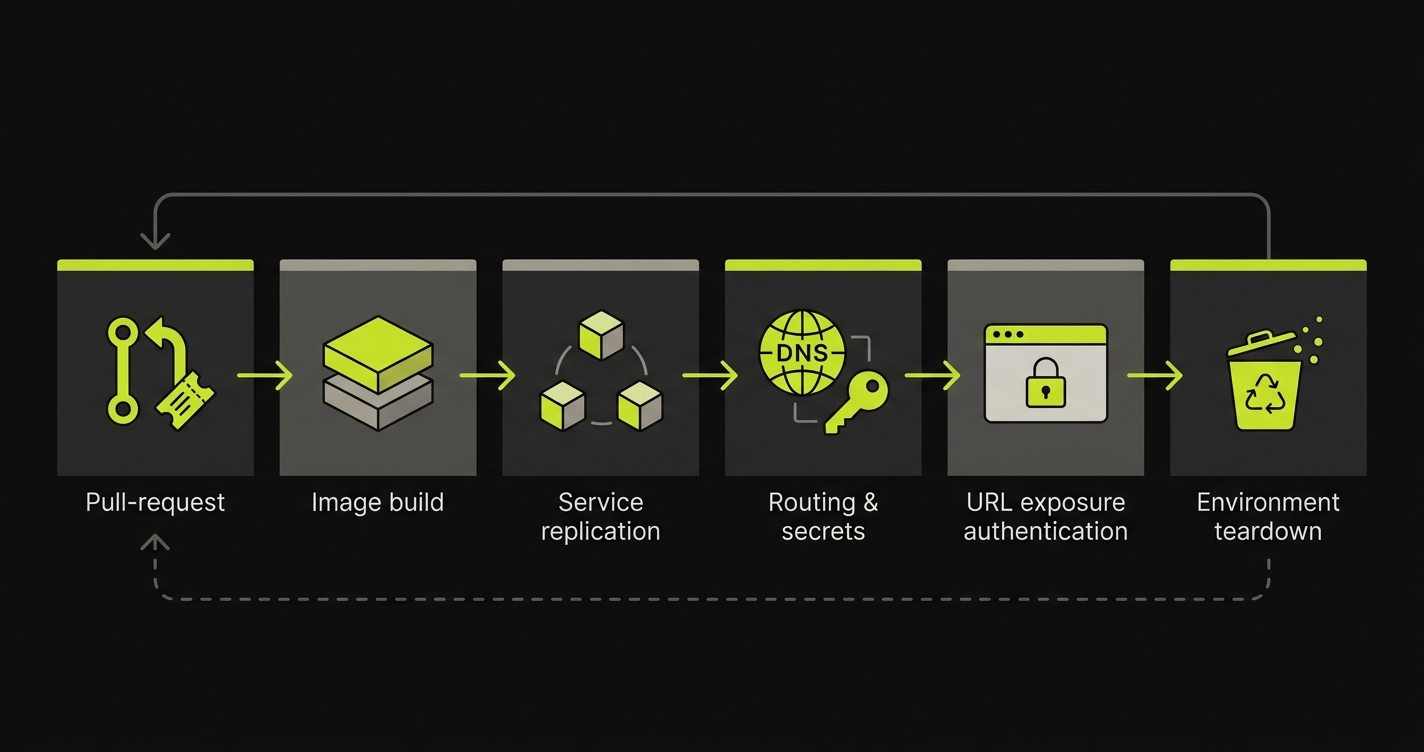
Stage 1: PR Open Detection and Trigger
The lifecycle begins the moment a PR is opened. Your CI/CD system needs to detect that event and register a trigger that kicks off the provisioning sequence.
In practice, this is a webhook from GitHub, GitLab, or Bitbucket to your orchestration layer. The orchestration layer might be GitHub Actions, a custom controller in your cluster, or a platform service. The trigger needs to carry enough context: the branch name, the commit SHA, the PR number, and ideally the set of services that changed.
The operations work here is straightforward in theory. Register the webhook. Write the handler. Map the PR event to a provisioning job. In practice, the failure modes stack up quickly. Webhook delivery is not guaranteed. If your handler is down or slow when the PR opens, the event is lost. Most platforms retry on failure, but retry windows vary. Race conditions occur when a PR opens and immediately receives a force-push before provisioning completes. Your trigger logic needs to handle that.
Teams building this in-house typically hit the concurrency problem first. A developer opens ten PRs in a morning. The orchestration layer queues ten provisioning jobs. If those jobs share infrastructure (a shared build cache, a shared Kubernetes namespace, a shared database server), they interfere with each other. Isolating them properly requires more upfront architecture work than the webhook integration itself.
The cost driver at this stage is job queue capacity: compute reserved for the orchestration layer and the burst headroom needed to handle concurrent provisioning events without backlog.
Ownership usually sits with the platform team. Development teams rarely touch this layer.
Stage 2: Image Build or Pull
Once the trigger fires, your orchestration layer needs to produce runnable container images for every service in the application. This is where preview environment provisioning first becomes expensive.
The two paths are build and pull. Build means running a full Docker build for the current commit. Pull means fetching a pre-built image from a registry if one exists for this commit or branch. Cache hit rate is the core variable. A warm cache hits the registry and skips the build entirely, reducing this stage to a registry pull (seconds). A cold cache runs the full build (minutes).
The DIY pitfall here is layer cache invalidation. Teams configure build caching incorrectly, invalidating the cache on every commit even when only application code changed and the dependency layer is identical. The result: every PR triggers a full build, build queues back up, and developers wait. By the time anyone notices the pattern, dozens of PRs have been delayed.
Multi-service stacks compound the problem. If your application has a frontend, a backend API, a background worker, and an admin service, you are building four images per PR. If your cache strategy is wrong, you are building four images from scratch per PR. At ten active PRs, that is forty concurrent builds on cold cache.
The failure mode that stalls everything downstream: a build fails because a transient dependency resolution error (network blip, registry rate limit, upstream package yanked). Your orchestration layer needs retry logic with exponential backoff, and it needs to surface the failure clearly so developers know their environment is not coming up.
Cost driver: compute for builds, registry storage, and egress on image pulls. Registry egress is frequently underestimated on large image layers.
Ownership: typically split. Platform owns the registry configuration and build infrastructure. The build pipeline files live in individual service repos, owned by service teams.
Stage 3: Service Replication Across the Stack
With images ready, the orchestration layer brings up the full service stack. This is where running a preview environment for every pull request gets architecturally expensive.
"Full stack" means different things to different teams. At minimum: frontend and backend. More commonly: frontend, backend API, one or more databases, a message queue, cache layer, and background workers. Some teams also need third-party service stubs (payment processors, email providers, identity providers) or internal service dependencies.
The operations work is service replication: spinning up isolated instances of every service for this PR's environment, wiring them together, and ensuring they talk to each other rather than to production or staging. The networking problem here is real. Services need to discover each other within the environment. A frontend needs to know the URL of its backend. A backend needs to know the address of its database. In Kubernetes, this is namespace-scoped service discovery. On raw compute, you are configuring it yourself.
Database initialization is the most common point of failure at this stage. A service replica starts up, tries to connect to its database, and fails because the database isn't ready yet, the schema hasn't been applied, or the seed data isn't loaded. Orchestration needs to handle startup ordering: wait for dependency readiness before starting dependent services. Naive implementations skip this and rely on application retry logic, which works until it doesn't.
The replication of services like frontend, backend, database, and queues adds another dimension: data isolation. Two PR environments sharing a database server need to be on separate schemas or separate databases, not just separate connection strings. Teams that share a database server without schema isolation end up with PR environments corrupting each other's test data. This is almost always discovered in production when someone merges a PR that ran against another PR's data.
Cost driver: this is the largest cost stage. You are running full replicas of every service for every open PR. Reserved compute, database storage, queue infrastructure. Cost scales linearly with open PR count. If you're already running into Stage 3 cost as a budget conversation, schedule a call with our founder to compare your fleet's per-PR cost against managed pricing.
Ownership: platform team, with service teams responsible for Helm charts or compose files that define the service's resource requirements.
Stage 4: Routing and Secrets/Config Propagation
Services are running. They need to be reachable and properly configured. Stage 4 is environment routing setup combined with secrets and config propagation. These are often treated as separate concerns. In practice, they are tightly coupled: misconfigured routing causes secrets to be sent to the wrong endpoint; missing secrets cause services to start in a degraded state that routing cannot fix.
Routing means assigning a unique URL to each environment and wiring it through your reverse proxy or ingress controller. The most common pattern: a subdomain per PR number or branch slug (for example, pr-123.preview.your-domain.com). This requires DNS wildcard records, TLS certificate provisioning (either wildcard or per-environment via ACME), and ingress rule creation per environment.
TLS is where teams get stuck. Wildcard certificates are simpler to manage but require DNS control at the CA validation step. Per-environment ACME certificates (Let's Encrypt) work without DNS control but add 30-90 seconds per environment for certificate issuance and hit rate limits at scale. Teams with more than 50 concurrent preview environments routinely hit Let's Encrypt's certificate issuance limits.
Secrets and config propagation means injecting the right environment variables, API keys, OAuth tokens, database connection strings, and feature flag overrides into each service replica. The operations work: maintain a secrets store (Vault, AWS Secrets Manager, environment-specific Kubernetes secrets), define how each service maps secret names to environment variables, and execute the injection at startup.
The failure mode that is hardest to diagnose: a secret propagates correctly at startup but rotates in production mid-PR-lifecycle. The preview environment continues running with a stale credential. Services that rely on short-lived tokens (OAuth, JWT-based service auth) expire silently. The symptom looks like a service crash or an integration bug in the PR code. It's actually a lifecycle management problem.
Cost driver: mostly operational overhead (KV store reads, TLS cert storage, ingress controller compute) rather than raw compute cost. But misconfigured secrets that force environment restarts multiply compute costs.
How Autonoma Operates the Lifecycle Out of the Box
If you are evaluating whether to build this lifecycle in-house or delegate it, the comparison point is what a managed preview environments alternative actually handles versus what you still own.
Autonoma operates the full six-stage lifecycle as a managed platform. One-click setup connects your repository. No infra configuration, no orchestration code, no custom webhook handlers. The platform handles every stage: webhook registration and trigger processing, image build and registry management with warmed layer caching, full-stack service replication with startup ordering and DB initialization, wildcard routing with TLS, secrets and config propagation, access control with testing bypass headers, and TTL-based teardown with full resource reclamation.
The per-stage breakdown, in operations terms:
Stage 1: Autonoma registers the webhook with your SCM provider during setup. PR events flow to Autonoma's orchestration layer. No event is lost; the platform handles retry and idempotency.
Stage 2: Builds run on Autonoma's infrastructure against a warmed layer cache. Multi-service stacks build in parallel. Registry management is handled; you do not maintain a registry.
Stage 3: Autonoma replicates your full stack per PR, including databases with schema init, queues, workers, and any configured third-party stubs. Service discovery is wired automatically. There are no tech-stack limitations on what services can be replicated.
Stage 4: DNS, TLS, ingress rules, and secrets injection are handled by the platform. Secrets come from your existing store (environment variables, Vault, or a connected secrets manager). Stale credential rotation is managed automatically.
Stage 5: Access control is on by default. Bypass headers for the natively integrated testing suite are configured automatically. PR comments with the preview URL post on environment ready.
Stage 6: Teardown fires on PR close or merge. All resources are reclaimed: compute, database volumes, DNS records, TLS certificates, secrets entries. TTL teardown is configurable and runs as a backstop. No reconciliation loop needed on your side.
Teams that have hit the long-term maintenance burden of self-built preview environments typically underestimated stages 3, 4, and 6. Those three stages account for most of the ongoing operational load.
If you're weighing build vs buy on preview environment infrastructure, talk to a founder before you commit a quarter of platform-engineer time to it. Grab 20 min with a founder
Below is a stage-by-stage summary of the full lifecycle across the key operational dimensions.
| Stage | Operations Work | DIY Pitfall | Failure Mode | Cost Driver |
|---|---|---|---|---|
| 1. PR Detection | Webhook handler, PR-to-job mapping | No retry on missed webhook | Lost events, force-push races | Orchestration compute |
| 2. Image Build | Registry, build pipeline, cache | Cache invalidates on every commit | Build queue saturation | Build compute, registry egress |
| 3. Service Replication | Stack spin-up, DB init, networking | Shared DB without schema isolation | Cross-PR data corruption | Largest stage: full stack per PR |
| 4. Routing & Secrets | DNS, TLS, ingress, secret injection | ACME rate limits at scale | Stale credentials, wrong env vars | Ingress compute, TLS storage |
| 5. URL Exposure | Auth layer, share links, bypass | Auth blocks testing tools | Open internet exposure | Auth proxy compute |
| 6. Teardown | Close handler, resource reclaim | No TTL fallback for stale PRs | Orphaned compute and storage | Zombie resources accumulate |
Stage 5: Preview URL Exposure with Access Control
The environment is running and routed. Stage 5 makes it accessible to the right people, while keeping it inaccessible to everyone else.
The access control problem has two sides. On one side: the environment should not be reachable by the open internet. Preview environments often contain real credentials, internal tooling, work-in-progress features, or pre-release data. An unauthenticated, publicly accessible preview environment is a security problem. On the other side: the environment needs to be accessible to the people and tools that have to review it. That includes: the PR author, reviewers, product managers doing acceptance review, and any automated testing or monitoring tools pointed at the URL.
The standard approach is an auth layer in front of the environment: OAuth-backed single sign-on, a shared password, or IP allowlisting. Each creates a tradeoff.
OAuth SSO is the most secure but creates friction for external reviewers or contractors who do not have an SSO account. Shared passwords are frictionless but leak. IP allowlisting works for office-based teams but breaks for remote engineers, mobile testing, and anyone working from a different network.
The friction-for-testing problem is the most operationally painful. When you put an auth wall in front of a preview environment, you also block your automated testing tools. Playwright, Cypress, or an E2E agent cannot authenticate through an OAuth login page. The DIY fix: generate bypass headers or tokens that testing tools can send to skip the auth layer. This requires custom auth middleware, careful token rotation, and making sure the bypass mechanism doesn't become a security hole wider than just removing auth entirely.
Sharing is a practical concern that gets underweighted. The PR author wants to send the preview URL to a designer or stakeholder. That person needs access but doesn't have SSO. Teams end up building share-link functionality: time-limited, single-use links that grant temporary access without full SSO. This is useful but adds another surface to maintain.
Finally: the preview URL needs to appear somewhere discoverable. The standard is a PR comment, automatically posted by the CI system when the environment is ready. This requires your orchestration layer to have GitHub/GitLab API access and to handle the case where the comment post fails (retries) or the PR was closed before the environment came up (no-op).
Cost driver: auth proxy compute is modest. The main cost is operational: maintaining the bypass mechanism, rotating tokens, and handling edge cases.
Stage 6: Environment Teardown
The environment lifecycle ends when the PR merges, closes without merging, or exceeds its TTL. Teardown is the most underengineered stage in self-built preview environment systems.
The trigger is a PR close or merge event from the same webhook system as Stage 1. The operations work: detect the event, identify all resources belonging to this environment (compute, database volumes, DNS records, TLS certificates, secrets entries, build artifacts), and reclaim them in the correct order.
Order matters. If you delete the database volume before the application server receives SIGTERM and exits cleanly, you get noisy crash logs. If you delete the DNS record before the TLS certificate is revoked, you accumulate orphaned certificates. If your orchestration layer deletes the Kubernetes namespace before PersistentVolumeClaims are cleanly released, volume reclamation fails silently.
The most common failure mode: orphaned resources on missed close events. If the PR closes while your webhook handler is down, the close event is never processed. The environment stays running. The database keeps storing. The compute keeps billing. Without a reconciliation loop that periodically audits running environments against open PRs, these orphans accumulate. Teams that run preview environments for six months without a reconciliation loop typically find dozens of zombie environments when they audit.
TTL teardown is the safety net. Any environment that has been running for more than N hours (typically 24-72) gets torn down automatically, regardless of PR state. This catches the orphans. It also catches the long-running PR that a developer forgot to close. TTL configuration is a cost-saving knob that teams frequently overlook.
State cleanup requires explicit attention. The environment may have written data: database rows, uploaded files in object storage, queue messages. Teardown needs to clean this up, not just delete the compute. Teams that delete the container but leave the S3 bucket or RDS instance running have only done half the job. Storage cost from preview environment state is frequently a surprise line item.
Cost driver: orphaned resources. Every hour a zombie environment runs is billed compute. Every day a zombie database volume persists is billed storage. This is the stage where cost overruns accumulate silently.
The six-stage lifecycle is the work. Owning it in-house means a platform engineer carrying webhook reliability, build cache strategy, full-stack replication, ingress and TLS, auth bypass for testing, and reconciliation-loop teardown. All of it at scale, without dropouts. Schedule a call with our founder to talk through your stack, your constraints, and whether managed preview infrastructure is the right call for your team.
Frequently Asked Questions
The preview environment lifecycle is the sequence of infrastructure operations that automatically provisions a full, isolated copy of your application when a pull request opens and tears it down when the PR merges or closes. It covers six stages: trigger detection, image build or pull, service replication, routing and secrets propagation, URL exposure with access control, and teardown. Each stage has distinct operations work, failure modes, and cost surfaces.
Preview environment provisioning is the process of allocating and configuring all the infrastructure resources needed to run an isolated application environment for a specific pull request. It includes building or pulling container images, spinning up services, initializing databases, configuring networking and DNS, injecting secrets, and exposing a unique URL. Provisioning happens automatically on PR open and is complete when the environment is reachable.
The most common failure modes cluster around three stages. In image build: cache invalidation misconfiguration causes full rebuilds on every commit, backing up the build queue. In service replication: missing startup ordering causes services to crash on boot when dependencies are not ready; shared databases without schema isolation cause cross-PR data corruption. In teardown: missed close events create orphaned environments that continue billing indefinitely. A reconciliation loop and TTL teardown are essential safeguards. Managed platforms like Autonoma run both by default: the platform reconciles running environments against open PR state on a continuous loop and enforces configurable TTL teardown so orphaned resources are reclaimed without manual intervention.
Adding an auth wall to a preview environment (via OAuth SSO, shared passwords, or IP allowlisting) blocks automated testing tools from reaching the environment. Testing agents cannot authenticate through an SSO login page. The standard fix is a bypass mechanism: a header or token that testing tools send to skip the auth layer. This requires custom auth middleware, careful token rotation, and security review to ensure the bypass does not become a wider vulnerability than removing auth entirely. Autonoma handles this at the platform level: bypass headers for its natively integrated testing layer (Planner, Automator, and Maintainer agents) are configured automatically, so the auth wall stays in place while the testing agents can still reach the environment without custom middleware on your side.
Cost is driven primarily by Stage 3 (service replication): full replicas of every service run for every open PR, and the total compute and storage cost scales linearly with open PR count. The secondary cost driver is orphaned resources from missed teardown events: zombie environments that keep billing compute and accumulating storage. Registry egress from large image layers is frequently underestimated. Build compute on cold cache is a spike cost that appears during periods of high PR volume.
These terms are often used interchangeably. Ephemeral environment lifecycle refers broadly to any short-lived environment that is created on demand and destroyed when no longer needed. Per-PR environment lifecycle is a specific implementation pattern where each open pull request receives its own isolated environment, and the lifecycle is tied directly to PR state: created on open, available while the PR is active, and destroyed on merge or close. The per-PR pattern is the dominant form of ephemeral infrastructure in modern CI/CD pipelines.



