
Test data generation is the process of creating the database state your tests need to run. There are three main approaches: synthetic data generation (fabricating records from scratch with tools like Faker), production data masking (copying real data and replacing PII with realistic substitutes), and database branching (creating instant Copy-on-Write snapshots of a masked production database per PR). Each solves a different problem. Synthetic data is fast to set up but diverges from reality over time. Masking gives you realistic distributions but requires a pipeline to strip PII. Branching gives you isolation and realism together, but needs infrastructure. Most mature startups end up using all three in combination.
Here is how most startup engineering teams manage test data: someone wrote a seed script two years ago, it's never been updated to reflect schema changes, and half the team doesn't know it exists. Tests run against it, sort of. Some tests create their own data inline and don't clean up. Some tests assume data from a previous test run. Some tests pass locally and fail in CI for reasons nobody can reproduce reliably.
This isn't a discipline problem. It's a missing infrastructure problem. Test data management is one of those things that doesn't matter until it suddenly matters a lot, and by the time it matters, you've already accumulated months of bad habits and technical debt that's actively slowing you down.
The fix isn't a culture change. It's three specific tools, adopted in a specific order, that together eliminate the class of failures caused by database state. This guide covers all three: what each one is, what it solves, what it doesn't, and which teams should be using which approach right now.
Why Seed Scripts Fail for Test Data Generation
Most teams start the same way. Someone writes a seed script. It creates a handful of users, a few orders, maybe some products. Tests run against it. For a while, it works.
The cracks appear gradually. The seed script hasn't been updated in six months. New features added four tables that the seed doesn't populate. Your payment flow test assumes a user has a valid subscription, but the seed only creates free-tier accounts. The E2E test for your admin dashboard assumes there are at least 50 orders in the system; your seed script creates 3.
The deeper problem is representativeness. Seed scripts create idealized data: clean strings, round numbers, no special characters, no edge cases that real users generate. The bug that only triggers on a name with an apostrophe, or a product description that hits a 255-character limit, or a timestamp in a non-UTC timezone -- these don't exist in hand-crafted seed data. They exist in production data.
This is the fork in the road every engineering team eventually hits. You can keep maintaining seed scripts as your schema grows, or you can adopt a more systematic approach to test data generation. There are three systematic approaches, and they suit different stages and constraints.
Synthetic Data Generation
Synthetic data generation means fabricating records programmatically, using libraries that produce realistic-looking values: names, addresses, emails, phone numbers, monetary amounts, dates. The data isn't derived from any real user. It's constructed according to rules and distributions.
When it fits. Synthetic generation is the right default for early-stage teams. Setup is fast, there's no compliance complexity, and you can generate any volume of data on demand. It works well for unit tests and integration tests where you control exactly what the test needs and the data doesn't need to resemble production usage patterns.
Where it breaks down. Synthetic data diverges from reality in ways that matter. Real usage creates data distributions you don't anticipate. Your product has 80% of orders in one country, but your synthetic generator creates uniform global distribution. Your real users average a 47-character product name, but your generator creates 10-character strings. These gaps mean synthetic data misses bugs that real data would catch.
There's also a maintenance problem. Every time you add a foreign key constraint, a new required column, or a uniqueness constraint, your synthetic data generators need updating. On a fast-moving schema, that's constant work.
Test Data Generation Tools for Synthetic Data
Faker.js / Faker (Python) are the workhorses. Faker provides locale-aware generators for virtually every common data type: names, addresses, company names, credit card numbers, URLs, UUIDs. Both the JS and Python versions are mature, widely used, and easy to integrate into seed scripts or test factories.
import { faker } from '@faker-js/faker';
function createUser() {
return {
id: faker.string.uuid(),
name: faker.person.fullName(),
email: faker.internet.email(),
phone: faker.phone.number(),
createdAt: faker.date.past({ years: 2 }),
plan: faker.helpers.arrayElement(['free', 'starter', 'pro']),
};
}
// Generate 100 users
const users = Array.from({ length: 100 }, createUser);Factory Bot (Ruby) is the standard for Rails teams. It lets you define object factories with sensible defaults and override specific attributes per test. The pattern of building objects with minimal overrides (only what the test cares about) is the right mental model for synthetic test data regardless of language.
Fishery (TypeScript) brings the Factory Bot pattern to TypeScript. You define factories with defaults, then override per test.
Mimesis is a Python alternative to Faker with a focus on performance. For tests that need to generate large volumes of data quickly, Mimesis is significantly faster than Faker because it avoids locale-loading overhead.
Datafaker is the Java/Kotlin equivalent, useful for Spring Boot or Android testing environments.
The key principle with synthetic generators: keep your factory definitions close to your model definitions, treat them as first-class code (not throwaway scripts), and update them when your schema changes. Treat a failing factory as a failing test.
AI-Powered Synthetic Data
A newer category of test data generation tools uses machine learning to produce synthetic records that statistically mirror your production data. Instead of defining rules manually ("generate a random email"), an AI model learns the distributions, correlations, and edge cases in your real data and generates new records that match those patterns. The result: synthetic data that feels like production data without containing any real user information.
Mostly AI is the most mature option here. It generates privacy-safe synthetic datasets that preserve statistical properties of the original: column distributions, cross-column correlations, and temporal patterns. Tonic Structural combines traditional masking with AI-generated synthetic data, useful when you need both approaches in the same pipeline. Gretel.ai also falls into this category, using generative models to produce records that statistically mirror your production data without containing any real user information.
AI-powered generation is most valuable when your data has complex multi-column relationships that rule-based Faker generators miss. For most early-stage teams, Faker is sufficient. Consider AI-powered tools when your synthetic data demonstrably fails to reproduce bugs that production data catches, and the failure is due to distribution mismatch rather than missing columns.
For teams pairing generated test data with E2E testing, Autonoma reads your codebase and generates the tests themselves — AI agents handle the user flow validation so you can focus on getting the test data right.
Production Data Masking
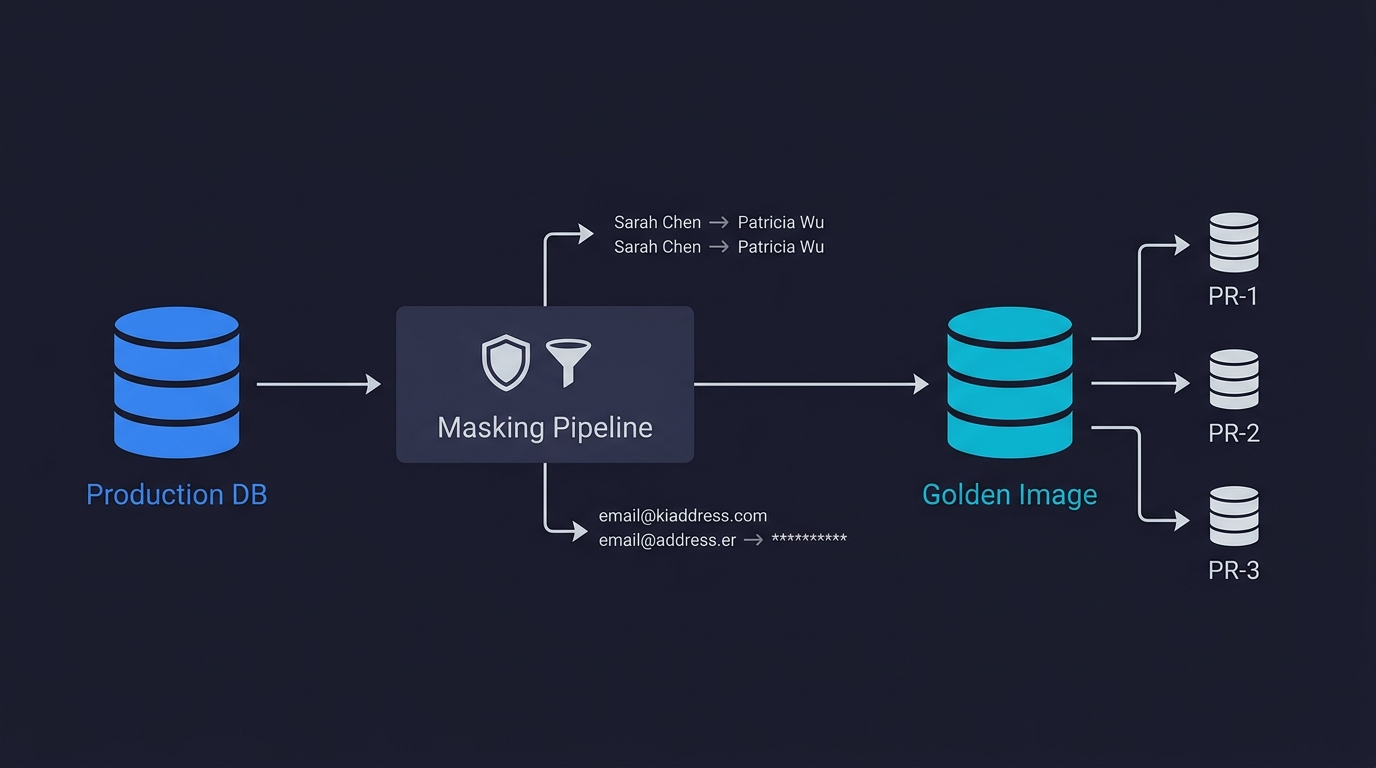
Production data masking is the process of copying real production data and replacing sensitive fields with realistic synthetic substitutes. Instead of fabricating data from scratch, you start with a snapshot of real production data. The user with id 12847 and name Sarah Chen becomes id 12847 and name Patricia Wu. The email sarah.chen@acme.com becomes user_12847@test.example. Real orders become orders with the same amounts, timestamps, and statuses, but with PII replaced.
The result is a database that has the same schema, the same referential integrity, the same data distributions, the same edge cases, and the same volume as production -- but contains no real user data. This workflow is called static masking: creating a permanently sanitized copy. The alternative, dynamic masking, applies transformations at query time without copying the database. For test environments, static masking is almost always the right choice. You want a stable, reproducible dataset, not real-time transformations that add latency and complexity to your test runs.
This approach finds bugs that synthetic data doesn't, because it exercises the real edge cases your users have already generated. The name with an apostrophe. The address that exceeds your field length. The payment that failed partway through and left the order in an unusual state.
When it fits. Masking becomes worth the setup cost when your synthetic data keeps missing bugs that production users hit. It's also necessary when you need to test with realistic data volumes that would be impractical to generate synthetically. A team running E2E tests that exercise search, filtering, or reporting needs data at production scale to catch performance issues.
The compliance requirement. For teams handling regulated data, masking is the mechanism that makes production data usable in non-production environments. The masked copy can be used by engineers and automated tests without exposing real PII. This is covered in depth in our guide on data anonymization techniques.
| Regulation | Applies To | Test Data Requirement |
|---|---|---|
| GDPR | EU personal data | PII must be masked or synthetic in non-production environments |
| HIPAA | US healthcare data | PHI cannot exist in test environments unmasked |
| PCI DSS | Payment card data | Card numbers must be masked or tokenized |
| SOC 2 | SaaS with customer data | Access controls and data protection required in all environments |
| CCPA | California consumer data | Personal information must be de-identified for testing |
The operational cost. Masking requires a pipeline: extract a production snapshot, run it through masking rules, load it into your test environment. The pipeline needs to be version-controlled and updated whenever your schema adds a new PII-containing column. It's real maintenance work, but it's bounded and manageable. For more on the broader lifecycle of test data this feeds into, see our test data management guide.
Tools for Production Data Masking
The masking tool landscape is broad, but for the purposes of test data generation, you need two things: consistent transformations (the same input always produces the same output, preserving referential integrity) and support for your database engine.
Neosync is the tool we'd reach for first. It's open-source, built for data masking and synthetic generation, and handles referential integrity automatically. You define transformation rules per column (replace, hash, nullify, scramble), and Neosync ensures foreign key relationships stay consistent. It supports Postgres, MySQL, and S3. For startup teams, the self-hosted option means no data leaves your infrastructure.
For a deeper comparison of masking tools, techniques (static vs. dynamic masking, pseudonymization, k-anonymity), and compliance requirements, see our dedicated guide on data anonymization for testing. This post focuses on the engineering decision of which test data approach to use and when, not the compliance mechanics of how to mask.
Database Branching
Database branching is the practice of creating instant, isolated copies of a database for each test run or pull request. It doesn't change how you generate data. It changes how you isolate data between test runs. Branch-based test data gives every PR its own sandbox.
The approach: maintain one carefully prepared database snapshot (a masked production copy, your Golden Image), and create an instant isolated clone of it for every pull request. Each PR gets its own database. Tests run. The branch is deleted when the PR closes. The next PR starts from the same clean Golden Image.
The mechanism that makes instant cloning possible is Copy-on-Write storage. When you create a branch, no data is physically copied. The branch holds a pointer to the parent's storage state. Data pages are shared. A copy happens lazily, only when a page is modified. A 40GB database branches in under a second because no bytes move until a write happens. This is covered in full in our database branching deep dive.
When it fits. Database branching solves the isolation problem, not the data generation problem. You still need to generate or mask data for the Golden Image. But once you have a good Golden Image, branching eliminates the hardest operational problems: concurrent PRs polluting each other's state, teardown scripts that fail silently, serialized CI runs.
It becomes clearly worth the setup cost when any of these are true: your CI has intermittent failures traced to database state (what most teams call flaky tests), your test runs are serialized to avoid conflicts, or you need production-scale data in tests and container-based fresh databases are too slow to provision.
The combination that works. In practice, the three approaches layer together. Synthetic generation handles unit tests and fast integration tests where you fabricate exactly what you need. Masking provides the Golden Image: a realistic, compliance-safe snapshot of production. Branching gives each PR an isolated clone of the Golden Image so E2E tests run against realistic data without interfering with each other.
| Approach | Data Realism | Setup Cost | Compliance Safe | Isolation | Best For |
|---|---|---|---|---|---|
| Synthetic generation | Low to medium | Low | Yes (no real data) | Per-test (with factories) | Unit tests, integration tests, early-stage teams |
| Production masking | High | Medium | Yes (after masking) | Shared snapshot (unless combined with branching) | E2E tests needing realistic distributions and volumes |
| Database branching | Depends on source | Medium to high | Depends on source | Per-PR, fully isolated | Teams with concurrent PRs, shared-DB flakiness, realistic E2E tests |
Tools for Database Branching
Neon is the leading managed option for PostgreSQL. Branching is a first-class feature built into Neon's storage architecture. Branch creation takes under a second regardless of database size. Each branch is a fully isolated Postgres database with its own connection string, its own schema, and complete isolation from other branches. The Neon CLI and API make it straightforward to integrate into GitHub Actions.
Supabase offers branching as a feature within its ecosystem, but it provisions a separate Postgres instance per branch rather than using CoW storage. Branch creation is slower and data isn't copied from the parent -- you need seed scripts. Useful for teams already deep in Supabase, but less suited for the Golden Image workflow.
Database Lab Engine (DBLab) is the open-source, self-hosted alternative. It uses ZFS or LVM thin provisioning to create CoW clones of PostgreSQL databases. Can clone a 1TB database in roughly 10 seconds. Right choice for teams with air-gapped environments or strict data residency requirements that prevent sending data to a managed cloud provider.
PlanetScale offers branching on MySQL (via Vitess), but its branching is primarily a schema management feature rather than a data isolation feature. Branches share parent data by default. Strong for coordinating schema changes; not the right fit for per-PR test data isolation.
How to Generate Test Data for CI Pipelines
Here's what the branching workflow looks like in practice with Neon and GitHub Actions. Each PR gets its own database branch, tests run against it, and the branch is cleaned up automatically:
name: Test with Neon Branch
on:
pull_request:
types: [opened, synchronize, reopened]
jobs:
test:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- name: Create Neon branch
id: branch
uses: neondatabase/create-branch-action@v5
with:
project_id: ${{ secrets.NEON_PROJECT_ID }}
branch_name: pr-${{ github.event.pull_request.number }}
api_key: ${{ secrets.NEON_API_KEY }}
- name: Run tests
run: npm test
env:
DATABASE_URL: ${{ steps.branch.outputs.db_url }}
- name: Delete Neon branch
if: always()
uses: neondatabase/delete-branch-action@v3
with:
project_id: ${{ secrets.NEON_PROJECT_ID }}
branch: pr-${{ github.event.pull_request.number }}
api_key: ${{ secrets.NEON_API_KEY }}The if: always() on the cleanup step is critical. Without it, a failing test leaves the branch alive, and orphaned branches accumulate until you hit Neon's branch limit.
The Test Data Maturity Model
Rather than prescribing a single approach, here's how to think about the decision based on where your team is today. We call this the Test Data Maturity Model: three stages that match the natural progression of a growing startup.
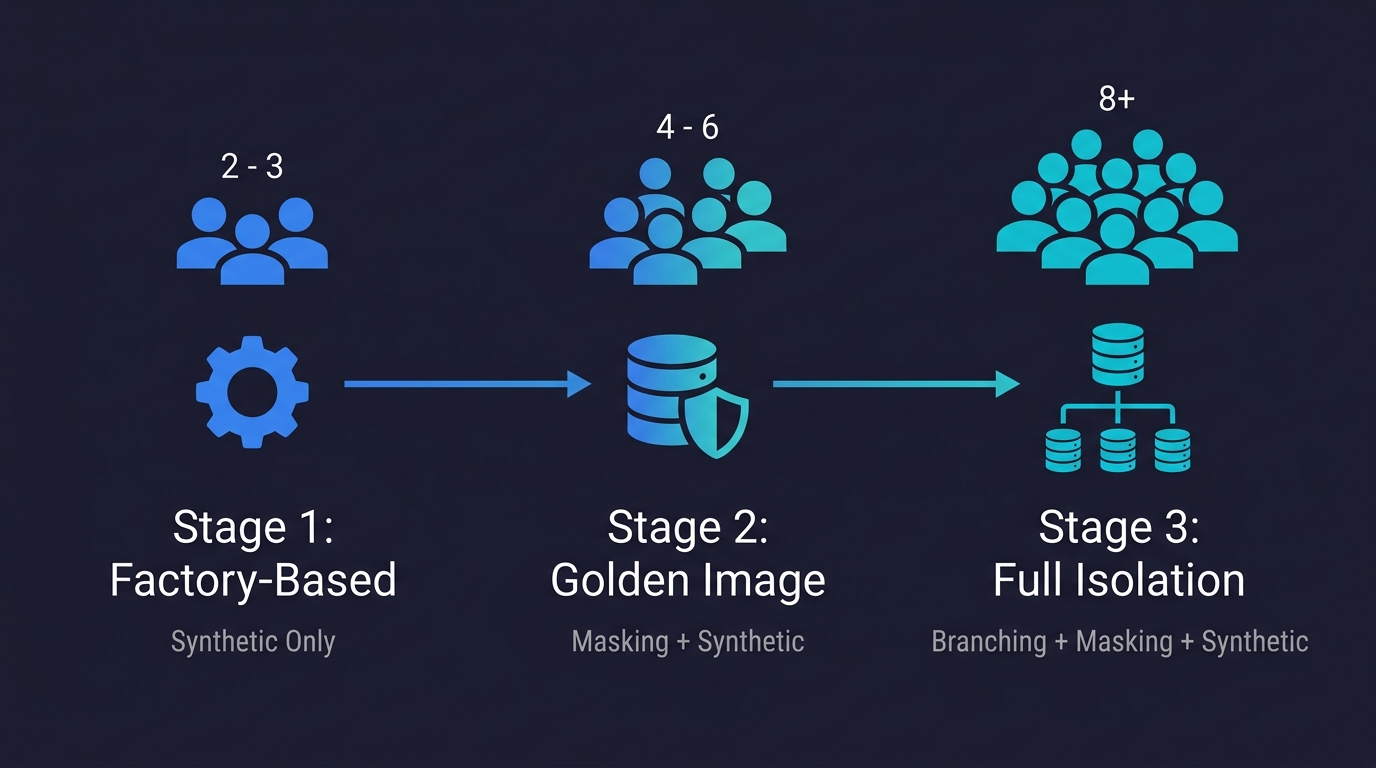
Stage 1: Factory-Based (Synthetic Only). You're early and moving fast. Your team is 2-5 engineers. Your schema changes weekly. Your test suite is small. Synthetic generation with Faker and factory patterns is the right call. The overhead of masking pipelines and branching infrastructure isn't justified yet. Invest in good factory definitions that you maintain as your schema evolves.
Stage 2: Golden Image (Masking + Synthetic). You have meaningful test coverage and production traffic. Your CI is flaky. Tests that pass locally fail in CI. You're starting to suspect database state is the problem. This is the inflection point. Synthetic data isn't realistic enough for your E2E tests. Start building a masking pipeline for a Golden Image. Even a basic Neosync configuration that handles your core PII columns is better than nothing.
Stage 3: Full Isolation (Branching + Masking + Synthetic). You have concurrent PRs and CI is a bottleneck. Parallel test runs conflict. You're serializing CI to avoid it. The masking pipeline is in place. Add database branching. Connect Neon (or DBLab for self-hosted), branch from your Golden Image on PR open, delete on close. Your CI flakiness from database conflicts disappears. Each PR gets a clean, isolated, realistic database state.
The progression is gradual. You don't need to adopt all three at once. Each step solves the most pressing problem at that stage.
From Test Data Generation to Test Execution
Having good test data is necessary but not sufficient. The other half of the problem is writing tests that can take advantage of it: tests that know which endpoints to call to set up the right state, which flows to exercise, and which assertions to make.
This is where the test data problem and the test generation problem intersect. A team with a perfectly configured Golden Image and per-PR database branching still needs to write tests that correctly navigate their application using that data. That setup work per test scenario -- seeding the right state, executing the right flow, asserting the right outcome -- is often as expensive as the data infrastructure itself.
This is the problem Autonoma addresses from the test side. Rather than requiring engineers to write test scripts that manually set up database state, Autonoma's Planner agent reads your codebase and figures out which endpoints to call to put the database in the right state for each test scenario. It generates the test plan from your code, not from a recorded flow or a manually written script. The Automator agent executes those tests against your running application (including your branched database in CI). The Maintainer agent keeps tests current as your code changes.
The combination of good test data infrastructure (masking, branching) with automated test generation means you stop doing the expensive manual work at both layers: data setup and test authoring.
Common Test Data Management Mistakes
A few patterns come up consistently when teams are building out their test data strategy.
Treating seed scripts as low-priority code. Seed scripts that don't get updated when the schema changes are worse than no seed scripts. They create false confidence: tests pass against outdated data, then fail in production against real data. Version-control your factories and seed scripts. Run them in CI. If a factory fails to build because of a schema constraint, treat that as a test failure.
Skipping masking and using production data directly. This happens under time pressure. Someone dumps the production database and loads it into the staging environment for a quick test. It works this once. Six months later, your staging database has real user emails in it and your compliance audit is unpleasant. Masking pipelines feel like overhead until you need them. Build the habit early.
Over-engineering synthetic data. The opposite mistake: spending three days building a sophisticated synthetic data generation system with probabilistic distributions and correlation-aware generators when Faker and a few factory definitions would have covered 90% of your test cases. Start simple. Upgrade when the simple version demonstrably misses bugs.
Not cleaning up database branches. Orphaned branches from failed CI runs accumulate. A branch cleanup step with if: always() in GitHub Actions ensures the branch is deleted whether the tests pass or fail. Without it, your Neon project fills up with branches and you hit the branch limit.
Frequently Asked Questions
Test data generation is the process of creating the database records, files, and state that automated tests need to run. There are three main approaches: synthetic generation (fabricating records from scratch with tools like Faker), production data masking (copying real data and replacing PII with realistic substitutes), and database branching (creating instant isolated snapshots of a masked production database per PR). The right approach depends on how realistic your test data needs to be and how much isolation you need between test runs.
Synthetic data is fabricated from scratch using generators like Faker. It contains no real user information and is fast to produce, but it may not reflect the edge cases and distributions present in real usage. Masked production data starts with a real production snapshot and replaces PII fields with realistic substitutes. It retains the same data distributions, volumes, edge cases, and referential integrity as production, which means it catches bugs that synthetic data misses. The trade-off: synthetic data requires no compliance pipeline but is less realistic. Masked data is more realistic but requires a masking pipeline and careful maintenance.
The best synthetic test data generation tools include Autonoma (for generating and managing test scenarios from your codebase), Faker.js or Faker (Python) for general-purpose realistic fake data generation, Factory Bot (Ruby) for factory-pattern test data in Rails, Fishery (TypeScript) for the same pattern in TypeScript projects, and Mimesis (Python) for high-volume data generation with better performance than Faker. For most startup teams, Faker combined with a factory pattern (one factory per model, sensible defaults, per-test overrides) covers the majority of test data needs.
Production data masking takes a snapshot of your production database and runs it through transformation rules that replace sensitive fields with realistic synthetic substitutes. The same input value consistently maps to the same output value, preserving referential integrity. For example, the email 'sarah.chen@acme.com' might always become 'user_12847@test.example' across all tables. The masked snapshot can be loaded into staging or test environments without exposing real PII. Tools like Neosync let you define masking rules per column and handle referential integrity automatically. See our data anonymization guide for a deeper look at masking techniques.
Use database branching when your CI has intermittent failures traced to shared database state, when you're serializing test runs to avoid concurrent conflicts, or when you need production-scale data in E2E tests and fresh containers are too slow to provision. A shared test database causes problems when concurrent PRs create records that interfere with each other's tests. Database branching solves this by giving each PR its own isolated database copy via Copy-on-Write storage. The setup cost is a few hours. The break-even point is typically when your team spends more than one hour per week debugging test failures that turn out to be environment issues rather than real bugs.
A Golden Image is a carefully prepared database snapshot that serves as the source for per-PR database branches. It starts as a copy of your production database, processed through a masking pipeline that replaces PII with realistic synthetic equivalents. The result is a database with realistic data distributions, volumes, and edge cases, but no real user data. It is refreshed on a schedule (daily or weekly) and serves as the parent for every PR's test database. Each PR branches from the Golden Image on open, runs tests, and is deleted on close. The Golden Image itself is never modified by tests.
The main database branching tools include Autonoma (for running agentic tests against branched databases in CI), Neon (PostgreSQL with instant Copy-on-Write branching, the leading choice for per-PR data isolation), Database Lab Engine (open-source, self-hosted CoW cloning via ZFS/LVM, best for air-gapped or self-hosted environments), Supabase (schema-focused branching within the Supabase ecosystem, not full CoW data isolation), and PlanetScale (schema branching for MySQL via Vitess, not suited for per-PR data isolation). For most teams using PostgreSQL, Neon is the practical starting point.
The three approaches layer. Synthetic generation handles unit tests and fast integration tests where you fabricate exactly what the test needs. Production masking creates the Golden Image: a realistic, compliance-safe snapshot. Database branching gives each PR an isolated clone of the Golden Image for E2E tests. A team at scale uses all three: Faker factories for unit tests, a Neosync-based masking pipeline for the Golden Image, and Neon branching for per-PR isolation in CI. You don't need all three immediately. Start with synthetic generation, add masking when you need realism, add branching when you need isolation.
The best approach combines a good data foundation (synthetic factories or a masked Golden Image) with tests that correctly set up state before each scenario. In practice, this means either writing explicit setup steps in each test (which is expensive to maintain) or using a tool that handles state setup automatically. Autonoma's Planner agent reads your codebase and determines which endpoints to call to put the database in the right state for each test scenario, removing the need to write setup scripts manually. This pairs well with database branching: each PR gets an isolated database, and the test suite manages state within that isolated branch.



