
Data masking tools replace sensitive production data (names, emails, SSNs, payment details) with realistic but fictitious values, so your test environments never contain real user information. The masking happens at the data layer: a tool reads your production database, applies transformation rules to each sensitive field, and outputs a sanitized copy that preserves the data structure and statistical distribution needed for meaningful testing. Whether from enterprise data masking software or an open-source library, the result is a database your team can copy freely into dev and test environments without legal or compliance risk.
The best thing that can happen to your testing workflow is that every engineer on your team can spin up a realistic, production-like database on demand, without waiting for a data team, without hand-crafting synthetic records, and without any legal risk attached to what is inside it. That is what properly implemented data masking gives you.
It also unlocks something less obvious: your test suite actually tests what it is supposed to test. Teams that strip out sensitive fields to avoid compliance problems often discover that their tests start passing vacuously, because the data they depend on is gone. Masking preserves format, referential integrity, and the statistical distribution of values. Your tests stay meaningful. Your environments stay clean.
The tradeoff is choosing the right tool for your stack and stage. That choice is harder than it looks, because the data masking tools market ranges from open-source libraries you can adopt in an afternoon to enterprise platforms with implementation timelines measured in quarters. This post maps the landscape so you can skip straight to the options that actually fit.
Why Data Masking Matters for Testing Specifically
Teams reach for data masking when one of three things happens. A security review flags that production data is being copied to dev environments. A GDPR audit asks which environments contain personal data. Or an engineer realizes that the test environment has a live customer's credit card number in it.
The instinct is to delete the sensitive data. The problem is that deleting data tends to break tests. Your test suite was written against real data shapes: real email formats, real date ranges, real foreign key relationships, real distribution of null values and edge cases. Replace everything with empty strings and your tests either fail or stop testing anything meaningful.
Masking preserves the shape while changing the values. A customer's real email jane.doe@company.com becomes synthetic8472@example.com. The format is valid, the domain is safe, and the tests that depend on email format still pass. A real credit card number becomes a Luhn-valid but completely fictitious number. The payment flow tests still run.
This is the distinction between masking and anonymization: masking preserves format and referential integrity, anonymization may not. For data anonymization techniques that go beyond format preservation, there are separate approaches. For testing workflows, masking is almost always what you want.
The secondary benefit is iteration speed. When your test environments contain properly masked data, every engineer on the team can get a fresh, realistic database without needing to involve a data team, wait for a sanitization script, or hand-craft synthetic records. The test data management problem becomes tractable.
And for any team operating under GDPR, CCPA, HIPAA, or similar regulations, masking test data is not optional. GDPR Article 5(1)(b) requires that personal data collected for one purpose cannot be processed for another without a legal basis. Copying production data to test environments violates this principle. HIPAA's Safe Harbor method requires removal or transformation of 18 specific identifier types before data can be used outside its original context. PCI DSS mandates that primary account numbers must be masked when displayed or stored in non-production systems. Our GDPR compliance testing guide covers the full regulatory picture; this post focuses on the tooling.
Types of Data Masking for Testing
Before evaluating tools, it helps to understand the four types of data masking, because most tools specialize in one or two.
Static masking creates a permanent masked copy of your database. The original data is read, transformed, and written to a new location. This is what testing workflows use: you produce a masked snapshot and distribute it to dev and test environments. The original production data is never touched.
Dynamic masking applies masking rules in real time when data is queried, based on the user's role or permissions. The underlying data stays unchanged. This is a production access control mechanism, not a testing tool. If your DBA needs to query production without seeing PII, dynamic masking handles that.
Deterministic masking ensures the same input always produces the same masked output. This is critical for referential integrity: if a customer ID appears in five tables, deterministic masking replaces it with the same fake value everywhere. Without determinism, foreign key relationships break and your test data becomes inconsistent.
On-the-fly masking applies transformations during data movement, typically as part of an ETL or data replication pipeline. It is relevant when you are streaming data from production to a staging environment and want masking applied in transit rather than as a separate step.
For data masking for testing, static masking with deterministic transformations is almost always the right combination. Dynamic masking solves a different problem (production access control), and on-the-fly masking only applies if your architecture already includes a replication layer.
Core Masking Techniques
The techniques your masking tool uses determine the quality of the output. Substitution (replacing values with realistic fakes) and format-preserving encryption (encrypting while keeping the original format, so a credit card number stays Luhn-valid) cover the vast majority of test data masking use cases. Shuffling is a useful complement for numeric fields where statistical distribution matters. Avoid redaction (blanking out values) for test environments, as it changes data shapes and breaks tests.
For a full breakdown of when to use each technique, including tokenization, pseudonymization, and formal privacy guarantees like k-anonymity, see our data anonymization techniques guide.
Best Data Masking Tools for Startups: What Criteria Matter
Enterprise data masking comparisons focus on scale, vendor support, and audit trails. Those things matter eventually. At the seed and Series A stage, the criteria that actually determine whether a tool ships are different.
Setup time is the first filter. A tool that requires a week of professional services to configure is not going to make it past your second sprint planning. For a team of three to five engineers, the setup cost must be low enough that one person can own it.
Pricing transparency matters because most enterprise tools do not publish prices. When a vendor's website says "contact sales," that is a signal about who the product is built for. If your ARR is under $5M, you are negotiating from a weak position and the deal terms will reflect that.
Testing integration is the actual use case. Can the tool output a masked database that plugs directly into your CI pipeline? Does it work with database branching workflows where each PR gets its own copy? Does the masking run fast enough to be part of a daily or per-PR snapshot refresh?
Data fidelity determines whether your tests stay meaningful. A masking tool that replaces all names with "John Doe" and all emails with "test@test.com" will pass compliance and fail your tests. Format-preserving encryption, realistic name generators, and referential integrity preservation across foreign keys are not nice-to-haves.
Automated PII discovery becomes important as your schema grows. At ten tables, you know which columns contain sensitive data. At fifty tables with contributions from multiple teams, manually tracking PII becomes unreliable. Tools that scan your schema and flag sensitive columns automatically reduce the risk that a new column with email addresses gets deployed to test environments unmasked. K2view and Tonic.ai both offer automated discovery; open-source tools require you to maintain the list manually.
Database support narrows the field quickly. If you are on PostgreSQL and your top contender only has strong support for Oracle, that is a problem you will discover after purchasing.
With those criteria in mind, here is how the main options compare.
The Enterprise Options: K2view, Delphix, Informatica
These three products represent the established enterprise tier. They are powerful, well-supported, and expensive. They share a common profile: designed for large organizations with dedicated data engineering teams, sold through enterprise sales motions, and priced accordingly.
K2view
K2view is built around a "business entity" model that treats masking as a function of how data is related rather than how it is stored. Instead of masking individual tables, you define business entities (customers, orders, accounts) and K2view masks the entity consistently across all the tables that represent it. If a customer's name appears in five tables and two event logs, every instance gets the same masked replacement value. Referential integrity is preserved automatically.
This approach is genuinely superior for complex enterprise schemas with dozens of related tables and many-to-many relationships. The referential integrity problem is hard: a naive masking tool might replace a customer name in one table but miss an occurrence in a denormalized audit log, creating inconsistencies that corrupt test data or expose partial PII.
For startups, the sophistication is largely overkill. A three-table schema with straightforward foreign keys does not need a business entity model. The real question is pricing. K2view does not publish prices. Based on market feedback, contracts typically start in the low six figures annually. It is built for financial services and healthcare enterprises with hundreds of tables and regulatory mandates.
Verdict: Technically impressive. Correct tool for a regulated enterprise with a complex schema. Wrong tool for a startup that needs to mask a PostgreSQL database with twenty tables.
Delphix
Delphix started as a data virtualization platform and added masking as a major feature. The core value proposition is that you do not copy your production database to create test environments: you create virtual copies that share storage with the production snapshot and only write when data changes. Masking is applied to the virtual copy.
The storage efficiency is real. A 2TB production database might consume 100GB of actual storage when virtualized across ten test environments, because most of the data is shared and copy-on-write only stores the delta. For organizations paying significant cloud storage costs on large databases, this is a meaningful TCO argument.
Delphix also does not publish pricing. Deals typically start in the range that requires a VP signature and a procurement process. Implementation is complex: Delphix runs its own appliance layer (physical or virtual) that sits between your production database and your test environments. Setup is measured in days to weeks, not hours.
The testing integration story is reasonable. Delphix has APIs that CI/CD pipelines can call to provision a masked, virtualized database copy on demand. In practice, teams with mature DevOps setups have built this integration; teams without a dedicated platform engineer find it difficult.
Verdict: Best fit for organizations with large databases (500GB+) where storage cost is a real concern, and where professional services are available to handle the implementation.
Informatica Data Masking
Informatica is the broadest platform of the three. Their data masking capability is a module within a larger data integration and governance suite. If your organization is already on Informatica for ETL or master data management, adding masking is an incremental license expansion rather than a new vendor relationship.
As a standalone masking tool, Informatica is difficult to recommend. The product assumes you have Informatica expertise on staff (or are paying for their professional services). The UI is complex. The concepts are borrowed from the ETL world, not the testing world. And the pricing is, predictably, enterprise: not published, negotiated per deal, typically six figures for meaningful scale.
The technical capabilities are comprehensive: format-preserving encryption, consistent masking, synthetic data generation, support for 30+ databases including most relational and some NoSQL options. But comprehensive and usable are not the same thing.
Verdict: Makes sense if Informatica is already in your stack and this is an expansion, not a new procurement. Does not make sense as a standalone masking purchase for a startup.
Enterprise Data Masking Tools Compared
| Tool | Best For | Pricing | Setup Complexity | Testing Integration | DB Support |
|---|---|---|---|---|---|
| K2view | Complex schemas, regulated enterprises | Not published, ~$100k+/yr | High, professional services typical | Good via APIs | All major relational DBs |
| Delphix | Large databases, storage cost-sensitive orgs | Not published, enterprise contracts | Very high, appliance deployment | Good via APIs | All major relational DBs |
| Informatica | Existing Informatica customers | Not published, module licensing | High, assumes platform expertise | Moderate | 30+ databases |
The Mid-Market Option: Tonic.ai
Between the enterprise tier and open-source, Tonic.ai occupies a space that is particularly relevant for growing startups. It is a cloud-native platform built specifically for engineering teams, not compliance departments.
Tonic.ai supports both data masking and synthetic data generation. You connect it to your production database, define masking rules through a web UI, and it generates a masked or synthetic copy that your CI pipeline can consume. It supports PostgreSQL, MySQL, SQL Server, MongoDB, and several data warehouses. The masking is deterministic by default, which preserves referential integrity across tables.
The key differentiator for startups is the developer experience. Tonic offers a CLI, API access, and integrations with common CI/CD platforms. The setup is hours, not weeks. There is a free tier for small databases, and published pricing tiers for growth (unlike the enterprise vendors). This transparency alone sets it apart from K2view, Delphix, and Informatica.
The tradeoff is that Tonic.ai is a SaaS product, which means your data flows through their infrastructure during the masking process. For teams with strict data residency requirements, this may be a dealbreaker. They offer a self-hosted option, but that moves you closer to enterprise deployment complexity.
Verdict: The strongest option for Series A teams that have outgrown open-source but are not ready for (or interested in) enterprise procurement. Published pricing, good developer experience, and real CI/CD integration.
Open-Source Data Masking Tools
The open-source tier is where startups actually ship. These tools are not as capable as the enterprise options on complex schemas, but they are available today, cost nothing in licensing, and can be integrated in hours rather than weeks.
PostgreSQL Anonymizer
PostgreSQL Anonymizer is a PostgreSQL extension that adds masking rules directly to your schema definitions. You declare masking rules as column security labels:
SECURITY LABEL FOR anon ON COLUMN users.email
IS 'MASKED WITH FUNCTION anon.fake_email()';
SECURITY LABEL FOR anon ON COLUMN users.full_name
IS 'MASKED WITH FUNCTION anon.fake_first_name() || '' '' || anon.fake_last_name()';
SECURITY LABEL FOR anon ON COLUMN users.phone
IS 'MASKED WITH FUNCTION anon.partial_phone(phone, 3)';When you export the database with anonymization enabled (pg_dump_anon), the masked values replace the originals in the output. The extension includes a library of realistic generators: fake names, emails, IP addresses, payment cards, dates, and more. It supports format-preserving functions for structured data like phone numbers.
The key constraint is PostgreSQL-only. If your stack is MySQL, SQLite, or MongoDB, this tool does not apply. The other constraint is that masking rules live in the database as security labels, which means they need to be maintained as your schema evolves. When you add a new column with PII, you need to remember to add a masking rule for it.
For startups on PostgreSQL, this is often the right starting point. Zero licensing cost, no new infrastructure, integrates with existing dump and restore workflows. The data anonymization techniques post covers how this fits into a broader anonymization strategy.
Greenmask
Greenmask is a newer open-source tool built specifically for PostgreSQL test data masking. Where PostgreSQL Anonymizer works through security labels inside the database, Greenmask operates externally as a CLI tool that wraps pg_dump and applies transformations during the dump process.
Greenmask offers several features that PostgreSQL Anonymizer does not: database subsetting (dump only a percentage of rows while maintaining referential integrity), parallel dumping for faster masking of large databases, and a validation diff mode that lets you compare masked output against the original to verify that transformations behaved correctly.
The CLI-first approach makes Greenmask particularly easy to integrate into CI/CD pipelines. A single command can dump, mask, and subset your database in one pass. For teams that want more control over the masking pipeline than PostgreSQL Anonymizer provides, or that need subsetting to keep test databases small, Greenmask is worth evaluating.
Verdict: Best PostgreSQL-specific alternative to PostgreSQL Anonymizer. Stronger CI/CD integration, subsetting support, and validation tooling. Still maturing compared to PostgreSQL Anonymizer's longer track record.
ARX Data Anonymization Tool
ARX is a Java-based open-source tool focused on statistical anonymization rather than format-preserving masking. It implements formal privacy models including k-anonymity, l-diversity, and t-closeness, and can analyze a dataset to find the minimum transformation needed to satisfy a given privacy guarantee.
ARX is the right tool when you need to prove a formal privacy guarantee about your dataset, not just replace PII with fake values. A dataset with k-anonymity of 5 guarantees that any individual in the dataset is indistinguishable from at least four others based on the quasi-identifier columns. This matters for research data, healthcare datasets, and any context where an attacker might try to re-identify individuals through combination attacks.
For general testing workflows, ARX is probably more than you need. The interface is desktop-based (a Java GUI), not a CLI or library, which makes CI/CD integration awkward. It is better suited to one-time or periodic anonymization of datasets for specific research or compliance purposes than to a daily test data pipeline.
Verdict: Use ARX if you need formal privacy guarantees and can tolerate a desktop workflow. Not ideal for automated testing pipelines.
Faker Libraries
The Faker approach is different in kind from the other options. Instead of masking a copy of your production database, you generate synthetic test data from scratch using a library that produces realistic-looking but entirely fake data.
Faker.js (Node.js), Faker (Python), and equivalents in most languages let you generate names, addresses, emails, phone numbers, company names, product names, and hundreds of other data types. You seed a database with generated data rather than masked production data.
import { faker } from '@faker-js/faker';
const users = Array.from({ length: 1000 }, () => ({
id: faker.string.uuid(),
name: faker.person.fullName(),
email: faker.internet.email(),
phone: faker.phone.number(),
address: faker.location.streetAddress(),
createdAt: faker.date.past({ years: 2 }),
}));The advantage is simplicity: no database access, no masking rules to maintain, no compliance concern about what data flows where. The disadvantage is realism. Production data has distributions, edge cases, and relationships that are difficult to replicate with random generation. A real user database has a long tail of unusual names, legacy email formats, null values in unexpected places, and referential patterns that reflect real behavior. Generated data is clean in ways real data is not.
For testing basic happy paths, generated data works well. For testing edge cases, import/export flows, and anything that depends on realistic data distributions, masked production data is more reliable. Most mature startups use both: Faker for unit and integration tests, masked production data for E2E test environments.
Open-Source Data Masking Tools Compared
| Tool | Approach | Best For | Pricing | CI/CD Fit | DB Support |
|---|---|---|---|---|---|
| PostgreSQL Anonymizer | In-database masking rules, pg_dump output | PostgreSQL teams needing automated pipeline | Free | Excellent | PostgreSQL only |
| Greenmask | External CLI wrapping pg_dump with transformations | PostgreSQL teams needing subsetting and validation | Free | Excellent | PostgreSQL only |
| ARX | Statistical anonymization with formal guarantees | Research, healthcare, formal privacy proofs | Free | Poor (desktop GUI) | CSV/tabular data |
| Faker libraries | Synthetic data generation from scratch | Unit tests, integration tests, development seeding | Free | Excellent | Database-agnostic |
All Data Masking Tools Compared
| Tool | Tier | Best For | Pricing | Setup Time | CI/CD | DB Support |
|---|---|---|---|---|---|---|
| K2view | Enterprise | Complex schemas, regulated industries | ~$100k+/yr (not published) | Weeks | Good (API) | All major relational |
| Delphix | Enterprise | Large DBs, storage-sensitive orgs | Enterprise contracts (not published) | Weeks | Good (API) | All major relational |
| Informatica | Enterprise | Existing Informatica customers | Module licensing (not published) | Weeks | Moderate | 30+ databases |
| Tonic.ai | Mid-Market | Series A+ teams, developer-first | Free tier + published plans | Hours | Excellent | PostgreSQL, MySQL, MongoDB, more |
| PostgreSQL Anonymizer | Open-Source | PostgreSQL teams, early-stage | Free | Hours | Excellent | PostgreSQL only |
| Greenmask | Open-Source | PostgreSQL teams needing subsetting | Free | Hours | Excellent | PostgreSQL only |
| Faker libraries | Open-Source | Unit/integration test seeding | Free | Minutes | Excellent | Database-agnostic |
| ARX | Open-Source | Formal privacy guarantees, research | Free | Hours | Poor | CSV/tabular |
How Data Masking Feeds the Golden Image Pattern
Data masking is the first step in the Golden Image workflow: a pattern where you maintain a single masked, migrated database snapshot as the source for every test environment. When a pull request opens, a CI step branches from the golden image using Copy-on-Write database branching. The branch is isolated, and deleted when the PR closes.
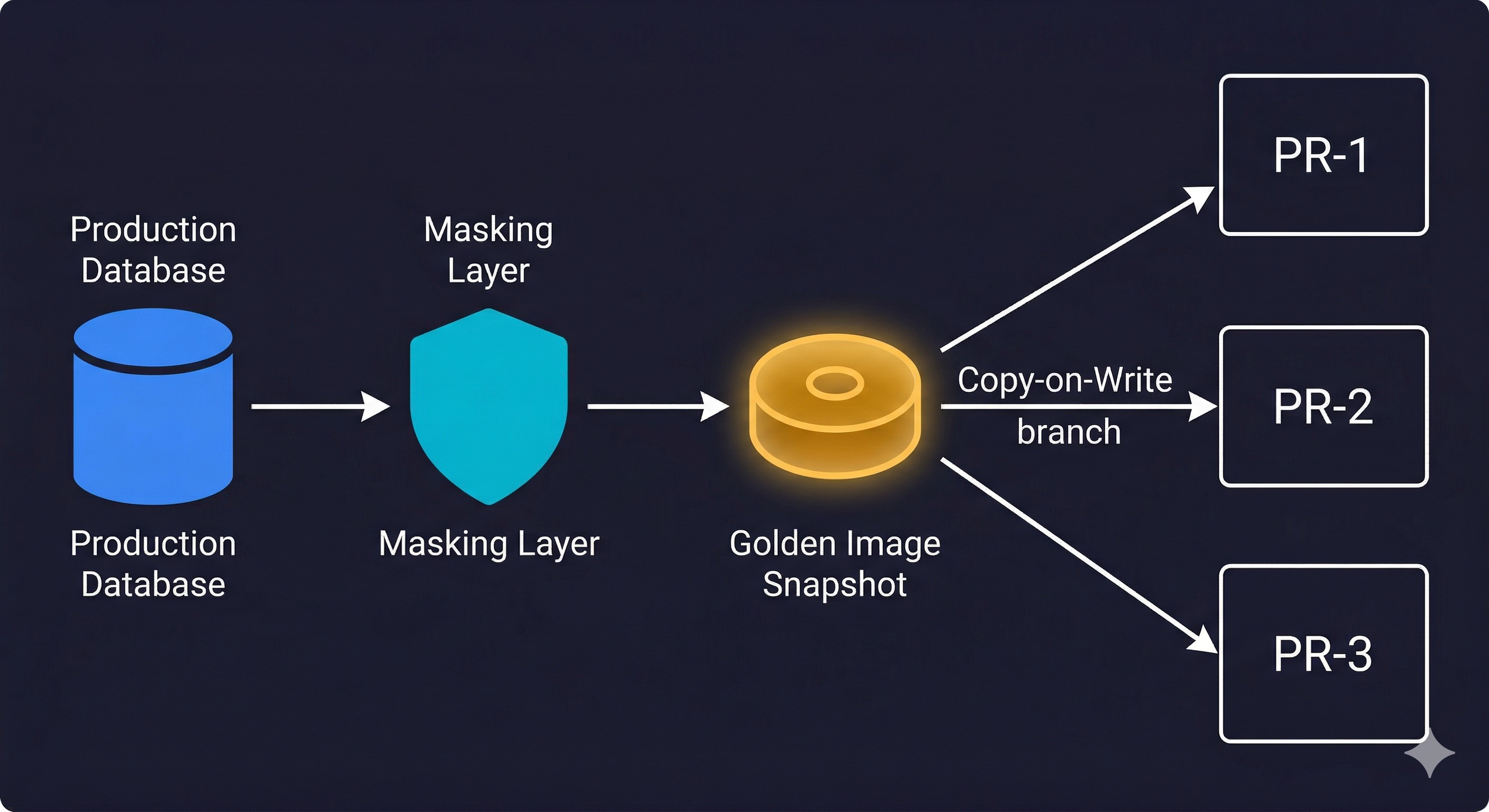
The masking step is where your tool choice matters most. It needs to be fast enough to run nightly, deterministic enough to produce consistent output, and reliable enough to not require manual intervention. PostgreSQL Anonymizer running against a pg_dump fits this profile well for PostgreSQL stacks. An enterprise tool like Delphix with its virtualization layer can handle this at scale for large databases.
Data masking and database branching are complementary: masking solves the "can we safely use production data" problem, branching solves the "can each engineer get an isolated copy" problem. Our database branching guide covers the full Golden Image workflow in detail, including Neon implementation and the Copy-on-Write mechanics.
Data Masking Tools Comparison: Which Tool for Which Stage
Choosing data masking software comes down to where you are, not where you want to be. Purchasing a six-figure enterprise platform when you have three engineers and a 10-table schema is not diligence, it is waste.
Bootstrapped or pre-seed (1-5 engineers, small schema): Start with Faker for unit and integration tests. If you are on PostgreSQL and handling user PII, add PostgreSQL Anonymizer to your dump pipeline. Total cost: zero. Total setup time: a few hours. This covers 80% of what early-stage teams actually need.
Seed stage (5-15 engineers, growing schema, first compliance conversations): Formalize the masking pipeline. If PostgreSQL Anonymizer is working, invest in making it part of your CI workflow properly: a nightly job that produces a fresh golden image, documented masking rules for every PII column, and a checklist that new column additions go through. If you are on multiple database types or starting to accumulate legacy data complexity, evaluate whether a lightweight commercial option makes sense. Pricing in this tier is still opaque, but some vendors (including Immuta and Neosec) have startup pricing tiers worth asking about.
Series A (15-50 engineers, dedicated platform team, real compliance requirements): This is when commercial tools become worth evaluating. Tonic.ai is the natural first step: published pricing, good developer experience, and a free tier to evaluate with. If your schema is complex enough to need entity-level masking, K2view is worth a proof-of-concept. If your database is large and storage costs are real, Delphix is worth exploring. For enterprise vendors, insist on a proof-of-concept before signing anything, and be explicit that startup pricing exists even if it is not advertised. At this stage, tools like Autonoma can also connect to your masked environments to run automated end-to-end tests, closing the loop between data preparation and test execution.
Data Masking in the CI/CD Pipeline: Making It Operational
Data masking is infrastructure, not a one-time project. The masking rules need to evolve with the schema. The golden image needs to be refreshed regularly. The pipeline needs to be tested: a masking tool that silently corrupts referential integrity will produce test environments that fail in confusing ways.
The teams that get this right treat masking rules with the same rigor as schema migrations. When a new column is added to the users table, the PR that adds the column also adds the masking rule. The CI check validates that all PII columns have rules. The golden image pipeline is monitored like any other production job.
When this is done well, every engineer on the team has access to realistic, isolated, compliant test data. End-to-end tests run against data that reflects real usage. Production incidents that trace to edge cases in real user data are caught in the test environment, not in production. And when a GDPR audit asks "where does personal data flow," the answer is clean: production and the systems that talk to it. Test environments are isolated by design.
That is the actual goal. Not compliance checkboxes. Reliable tests and confident deploys.
For teams looking to take the next step and automate end-to-end testing against these properly masked environments, Autonoma connects to your codebase and uses agents to plan, execute, and maintain tests across your test pipeline. The Planner agent reads your routes and user flows, the Automator agent runs tests against your environments (including environments seeded from a golden image), and the Maintainer agent keeps tests passing as your code evolves. No test code to write, no masking pipeline disruption.
Frequently Asked Questions
A data masking tool replaces sensitive or personally identifiable information (PII) in a database with realistic but fictitious values. The goal is to preserve the data structure, format, and statistical distribution needed for testing while removing any real user information. Examples include replacing a real email like jane@company.com with a generated email like user8472@example.com, or replacing a real credit card number with a Luhn-valid but fictitious one. Tools like Autonoma, PostgreSQL Anonymizer, K2view, and Delphix all offer data masking capabilities at different scales and price points.
Data masking replaces sensitive values while preserving format, structure, and referential integrity across tables. Anonymization is a broader term that includes techniques that may not preserve format, including generalization (replacing exact ages with age ranges), suppression (removing records), and statistical noise addition. For testing workflows, masking is almost always preferred because it keeps the data usable for tests. Anonymization techniques like k-anonymity are more appropriate when publishing datasets for research or sharing data externally with formal privacy guarantees.
Yes. For PostgreSQL teams, PostgreSQL Anonymizer is a mature open-source extension that handles format-preserving masking with realistic value generators and integrates cleanly with pg_dump workflows. Faker libraries (available in JavaScript, Python, and most other languages) let you generate synthetic test data without masking production data at all. ARX handles formal statistical anonymization. Open-source tools cover the needs of most early-stage teams without licensing costs. Enterprise tools like K2view and Delphix add value for complex schemas, very large databases, or regulated environments where formal audit trails and vendor support are required.
Enterprise data masking tools including K2view, Delphix, and Informatica do not publish pricing. Based on market feedback, contracts typically start in the range of $50,000 to $150,000 per year for meaningful scale, with implementation costs on top. These vendors have startup pricing programs but they are not advertised, so you need to ask explicitly during negotiations. For teams under 20 engineers or with databases under 100GB, open-source options like PostgreSQL Anonymizer are almost always the right starting point.
The most common pattern is a Golden Image workflow. A nightly or on-demand job takes a production snapshot, runs the masking tool against it, applies schema migrations, and promotes the result as a stable masked snapshot. Each pull request then branches from this golden image using a Copy-on-Write database branching tool like Neon. The branch is isolated to that PR, deleted when the PR closes, and takes seconds to create. This gives every test environment realistic, compliant data without copying production PII into test infrastructure.
The best data masking tools for startups depend on stage and stack. For early-stage teams on PostgreSQL, PostgreSQL Anonymizer and Greenmask are the clearest choices: free, well-documented, and integrate with standard dump and restore workflows. Faker libraries are ideal for generating synthetic data for unit and integration tests. Tonic.ai bridges the gap between open-source and enterprise with published pricing and a free tier. As teams grow past 20 engineers, K2view and Delphix become worth evaluating for complex schemas. Avoid purchasing enterprise tools before you have a dedicated platform engineer to own the implementation.
Static data masking creates a permanent masked copy of your database where sensitive values are replaced with fictitious ones. The masked copy is a separate dataset used for testing and development. Dynamic data masking applies masking rules in real time when data is queried, based on the user's role or permissions, without changing the underlying data. For testing workflows, static masking is what you need. Dynamic masking is a production access control mechanism that prevents unauthorized users from seeing sensitive data in live queries.
Use both, for different purposes. Masked production data preserves the distributions, edge cases, and referential patterns of real user behavior, making it ideal for end-to-end and integration tests. Synthetic data generated by tools like Faker is faster to create and carries zero compliance risk, making it ideal for unit tests and development seeding. Most mature startups use Faker for unit tests and masked production data for E2E test environments. The choice is not either-or.



