
An AI-agent regression is a bug introduced when an AI coding agent modifies a shared piece of code (a util function, a component, a schema field) and breaks features it never directly touched. The agent's own tests pass because they align with the change. The breakage shows up in production flows that no human thought to open during review, because the PR diff looked unrelated.
When an AI agent edits a shared util and breaks a feature in a different part of the app, the failure mode isn't a missing unit test, it's a missing E2E. We built Autonoma to generate and re-run that E2E coverage automatically, so the breakage is caught before the PR merges.
This is the pattern we keep seeing as teams ship faster with tools like Cursor and Claude Code. The speed is real and the productivity gains are real. The gap is that these agents write code with local context, and regressions hide in the global context they didn't read.
Why AI Agents Break Adjacent Features
AI coding agents are extraordinarily good at what they see. They read the file, understand the intent, refactor or extend with confidence. The problem is what they don't see: every other file that imports the thing they just changed.
Five patterns account for most of the AI-agent regressions we observe:
Changed shared helper signature. The agent refactors formatPhone(value, country) to formatPhone({ value, country }) because the destructured object signature is cleaner in the file being edited. Three other callers pass positional arguments. They all break. None of them were in the diff.
Regex tightened in a validator. The agent updates an email validator to reject plus-addressed emails (like user+tag@domain.com) to fix one failing spec. Sign-up works fine. The account-settings flow that lets users add a secondary email breaks silently because it hit the same validator through a different code path.
Prop renamed in a shared component. The agent renames a prop from isLoading to loading inside a Button component to match the design system convention. Every other consumer that passes isLoading now renders an always-active button. The visual diff is invisible in a static PR review.
Reused field name on a different schema. The agent adds a status field to a Payment model to track processing states. Another part of the codebase queries the status field from an Order model and joins incorrectly after a refactor. The query succeeds. The values are wrong.
Date formatter switched from local to UTC. The agent changes a date utility from local time to UTC because the API response now includes timezone-aware timestamps. Booking confirmations now display the wrong time for users outside UTC. No test covered the timezone logic because timezone logic is famously annoying to test.
These aren't edge cases or exotic scenarios. They're predictable failure modes of code-generation systems that optimize locally. The agent holds a window of context, and your production flows extend well beyond that window. The ai-agent merge tax compounds this: every PR that merges without catching a regression costs more to fix than the last one, because production data has already moved through the broken path.
Why Unit Tests Aren't Enough for AI-Agent Regressions
Here's the uncomfortable truth about the 2026 testing pyramid: it was designed for a world where humans write the code.
When a human engineer modifies a shared helper, they know what they changed, and they know (or at least suspect) which callers are affected. They write a unit test that exercises the new behavior and often update the existing tests for the callers they remember. Coverage isn't perfect, but the human's mental model of the codebase compensates for incomplete tests.
When an AI agent modifies the same helper, the tests it generates are aligned with the change, not with the rest of the app. The agent writes tests for the new signature. Those tests pass. The three callers using the old signature don't have tests the agent knew to update, because the agent's context window didn't include them. The unit-test layer is green and the regression is undetected.
This is why we describe the testing pyramid as inverting when AI agents write the code. The unit-test base, which was reliable when humans wrote and maintained it, becomes structurally unreliable for catching cross-file regressions introduced by AI. The shared-util mutation pattern is the clearest demonstration: the agent's unit tests are factually correct about the new behavior and factually blind to the broken callers.
What you need instead is a top-heavy E2E layer, one that runs the actual application flows end-to-end, independent of whether the agent remembered to update the caller tests. The automated regression testing guide goes deeper on how to structure this layer, but the short version is: if your E2E coverage doesn't run every PR against the real application, you're relying on the agent's local context to catch its own cross-file regressions. That's not a testing strategy. That's optimism.

What an Effective Regression Net Looks Like
A regression net for AI-agent code needs three properties that most existing test setups don't have.
Codebase-aware planning. The test planner needs to read the whole repository, not just the PR diff. A diff-aware test runner sees that you changed formatPhone and runs the tests for formatPhone. A codebase-aware planner sees that formatPhone is called in checkout, account settings, and admin, and runs end-to-end flows through all three. This is the difference between testing the change and testing the impact of the change.
Replay-based stable re-execution. The same flow needs to run the same way on every PR. Not "roughly the same" or "similar steps." Deterministically the same, against an isolated preview environment that matches production. Flakiness in the test runner is the enemy here, because a flaky test in a high-volume PR pipeline gets dismissed as noise, and real regressions hiding behind flake get merged. The teams succeeding with parallel AI agent PRs are the ones who invested in deterministic replay infrastructure before scaling their agent usage.
A Reviewer that distinguishes failure types. Not every test failure is a regression. Sometimes the agent changed behavior intentionally and the test is now outdated. Sometimes the test itself has a bug. A useful regression net categorizes failures: real regression (the app is broken), agent error in the test (the test has a bug), or intentional behavior change (the test needs to be updated). Without this triage layer, teams turn off the tests because the noise-to-signal ratio is too high. Turning off the tests is the worst outcome.
How Autonoma's Replay Catches AI-Agent Regressions
This is the approach we built at Autonoma after watching the same pattern repeat across teams shipping with Cursor and Claude Code.
The core problem is that the coding agent has local context and the regression hides in the global context. So we built the regression net to start from the global context: the entire codebase.
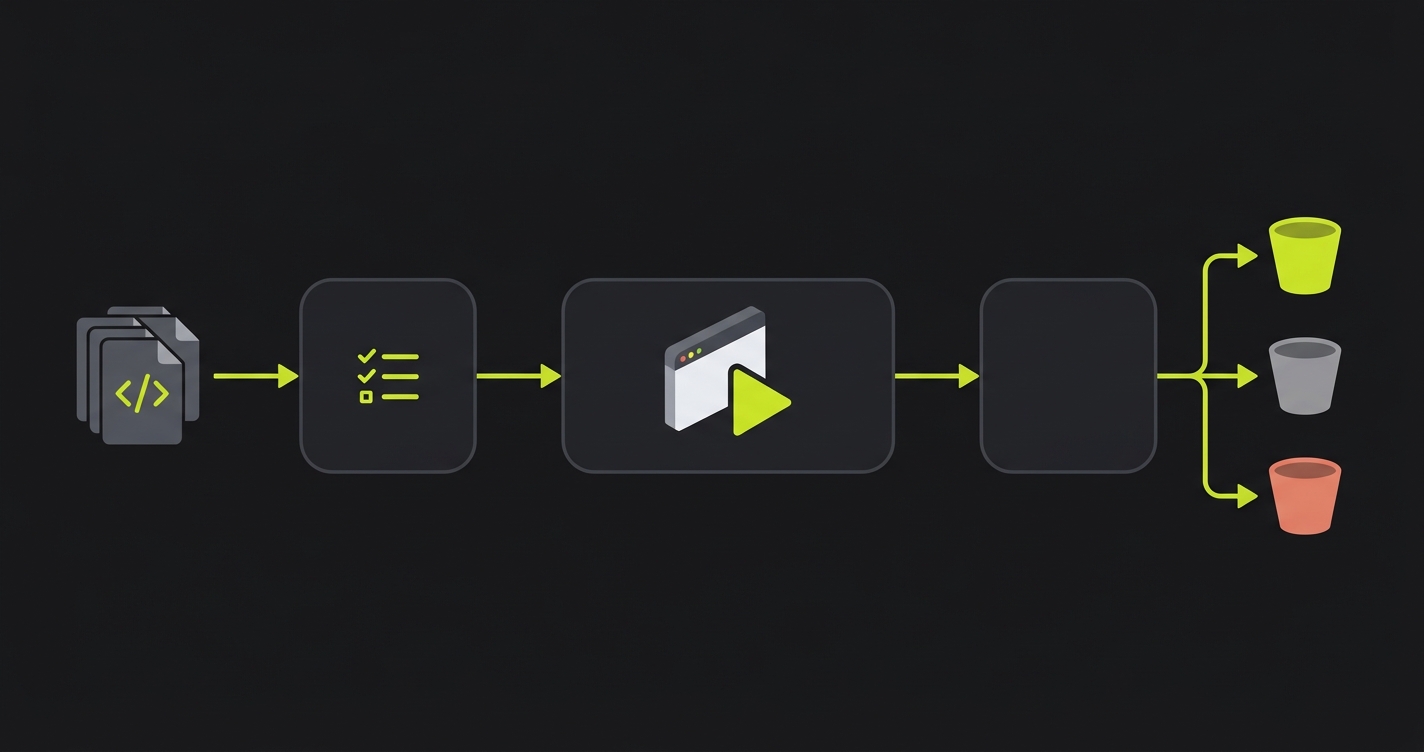
Plan. Our Planner agent reads your full repository, routes, components, and user flows, and generates E2E test cases from what your app actually does. Not from the PR diff. Not from your Jira tickets. From the live code. When an AI agent changes formatPhone, the Planner already has E2E tests for every flow that touches phone formatting, because it read the codebase when you connected it, not when the PR arrived. This codebase-aware planning is what lets us catch cross-file regressions that the agent never flagged.
Replay. Our Replay layer executes those E2E tests against your PR's isolated preview environment. The same flow. The same steps. Every PR. The isolation means you're testing the PR's actual code, not a shared staging environment that might have other changes mixed in. The determinism means a failure is a real signal, not flake. The regression testing baseline is set once, and Replay re-runs it consistently until the Planner updates it based on code changes.
Reviewer. After every Replay run, our Reviewer agent triages each failure. Real regression: the PR broke something the app used to do correctly. Agent error in the test: the E2E itself has a bug, usually because the UI changed intentionally. Intentional behavior change: the feature behaved differently by design, and the test needs updating. Engineers get a categorized report, not a wall of red. The Reviewer is why our customers don't turn off the tests when the agent ships fast: the signal stays clean.
End-to-end runtime on most codebases is five to seven minutes per PR. That's fast enough to run on every merge request, slow enough to be thorough. For teams running agentic testing with vibe coding, that runtime budget fits inside the PR review window.
A Worked Example: The Shared-Util Mutation
Here's the scenario in concrete terms.
Your team is using Claude Code to refactor your payments module. The agent looks at formatPhone.js and decides the function signature is inconsistent with the rest of the codebase. It changes formatPhone(value, country) to formatPhone({ value, country }). It writes a unit test for the new signature. The unit test passes. The PR looks clean.
Three callers exist in the codebase. The agent updated the one in the payments module it was working on. Two others, in the checkout flow and in the account settings page, still pass positional arguments. Nobody opened checkout during review because the PR was labeled "payments refactor." Nobody ran account settings because account settings wasn't in the diff.
Here's what each layer of the testing stack sees:
| Layer | What it runs | What it sees | Outcome |
|---|---|---|---|
| Unit tests | New formatPhone in isolation | New signature passes correctly | Green. Regression undetected. |
| Manual QA | Payments flow (because that's the PR) | Payments works fine | Approved. Checkout never opened. |
| Autonoma Replay | All flows that touch phone formatting | Checkout E2E fails at phone entry step | Reviewer flags: real regression in checkout. |
The Reviewer surfaces a stack trace from the checkout page, pointing at the line where formatPhone is called with positional args. The engineer sees the failure before merging, updates the two remaining callers, and the PR goes green. The user who would have hit a broken checkout form never existed.
This is the loop we're trying to close. AI agents write fast and write locally. The regression net needs to be global, deterministic, and automatic. Without it, speed becomes a liability: you ship more, you break more, and the fixes compound. How this plays out at scale when entire features are agent-generated covers the next layer of this same loop.
FAQ
AI coding agents generate code from a context window that spans the files they're actively editing. They don't hold a global model of every import relationship in the codebase. When they change a shared utility, they update the callers they can see. Callers in other files, especially files not mentioned in the prompt, fall outside that window. The change propagates through the codebase at runtime; the agent's awareness doesn't.
A unit test for the changed utility catches regressions in the utility itself. It doesn't catch regressions in the callers that weren't updated to match the new signature, unless those callers also have unit tests that exercise the integration point. In practice, the callers often don't have that test coverage, because the human or agent who originally wrote the caller didn't anticipate the utility changing. An E2E test that runs the full flow through the real UI is the only layer that reliably catches this class of regression.
Cursor and Claude Code are excellent at generating and refactoring code. They're not designed to run your application and verify that it still works end-to-end after their changes. That's a different problem, and it requires a different tool. We don't frame this as a limitation of Cursor or Claude Code; we frame it as a gap in the workflow. The coding agent is one part of the pipeline. The regression net is another. Teams that build both ship fast without accumulating AI code regression debt.
Autonoma's Replay runs in five to seven minutes on most codebases. The Planner and Reviewer add a few minutes on top of that for the first run against a new codebase; subsequent PRs reuse the existing plan and run faster. The target is fitting inside the PR review window so the signal arrives before the engineer approves, not after they've already moved on to the next task.



