
Per-PR Preview Environments are the category answer to "ci passes but bugs in production." CI is structurally blind to five validation surfaces: deployed-state behavior, real-data shapes, third-party integration drift, browser-side regressions, and cross-component flows in a real isolated runtime. A Per-PR Preview Environment provisions a full-stack deployed runtime for every pull request, making each of those surfaces observable before merge.
CI went green. The PR merged. Then something broke in production that nobody saw coming. It was not a logic error. It was not a failing test case. The test suite had never modeled the behavior at all, because CI had no way to observe it.
This is not an unusual story. It is the structural consequence of what CI actually validates. The gap between "CI green" and "production safe" is real, it is well-defined, and there is a category of tooling designed specifically to close it: Per-PR Preview Environments. This article names the five things CI cannot validate by construction, then explains how per-PR orchestration in an isolated runtime addresses each one.
What CI Cannot Validate #1: Deployed-State Behavior
CI tests run against code. They do not run against a deployed application.
The distinction matters because many bugs are not bugs in the code itself. They are bugs in the interaction between the deployed application and its runtime state: the way the application behaves after it has started, handled requests, written to a database, and accumulated session data. A migration that runs cleanly in isolation can corrupt records in a database that already has existing rows in a specific shape. A background job that passes unit tests can deadlock when it encounters a queue that is already processing a backlog. A cache-warming routine that works in a fresh environment can serve stale data when the cache already contains entries from a prior deploy.
These behaviors are not hypothetical edge cases. They are the category of bugs that teams describe as "worked in staging, broke in production" or "passed all tests, failed on deploy." CI cannot observe them because CI does not deploy the application. Adding more unit tests does not help. Adding more integration tests does not help if those integration tests run in the same isolated-process context. The only thing that helps is running the application in a deployed state and observing it.
Per-PR Preview Environments close this gap by construction. Every PR gets a provisioned, running application. Deployed-state behaviors are observable. The pipeline can test them before merge.
What CI Cannot Validate #2: Real-Data Shapes
CI uses fixtures. Fixtures are snapshots of data that were accurate at some point in the past.
Production data evolves continuously. Users create records in combinations the schema technically allows but the application code never anticipated. Migrations run on live databases and leave behind rows that don't fully satisfy newer constraints. JSON columns accumulate fields that the application has stopped writing but has never cleaned up. Foreign key relationships develop gaps from soft-deleted records.
A CI test that passes against a clean fixture set can fail catastrophically against production-shaped data because the fixture set does not model the real distribution. The code is correct for the data it was tested against. It is not correct for the data it will actually encounter.
Heavier CI matrices compress this gap to a degree. Contract tests and property-based tests can model a wider range of input shapes than hand-written fixtures. But they still require someone to enumerate the shapes, and they still run in a synthetic context that cannot observe real database state without a deployed database to connect to.
Per-PR Preview Environments solve this differently. The preview database can be seeded from a sanitized snapshot of production data, or provisioned with a representative seed that reflects the actual distribution of record shapes. Either way, the application under test is operating against data that resembles what production contains, not what a developer thought production contained when they wrote the fixture.
What CI Cannot Validate #3: Third-Party Integration Drift
CI mocks third-party services. Mocks are pinned to the API contract at the time the mock was written.
Third-party APIs change. Sometimes with version bumps, sometimes without. Response fields get renamed. Pagination behavior changes. Rate limit headers appear or disappear. Error codes shift. Webhook payload shapes evolve. A mock written six months ago for a payment provider, a CRM, or a data enrichment service is not necessarily accurate for the API the provider is serving today.
The mock will pass. The live integration will fail. CI has no way to surface this because CI never calls the real endpoint. Contract testing helps at the boundary but requires the provider to publish a machine-readable contract. Most do not.
The only way to verify third-party integration fidelity is to call the real API from a real deployed environment. Per-PR Preview Environments can be wired to use real third-party credentials in sandbox mode, so every PR that touches an integration path exercises the actual API surface. Drift shows up as a test failure before merge, not as a production incident.
What CI Cannot Validate #4: Browser-Side Regressions
CI lint and unit tests validate JavaScript behavior at the module level. They do not observe what a browser renders.
Visual regressions, layout breaks, cross-browser rendering differences, and interaction bugs in CSS transitions or JavaScript animations are only observable in a real browser rendering a real deployed page. A component that passes all its unit tests can render incorrectly in Chrome 123 due to a CSS containment change, a subpixel rounding behavior, or a font-metric difference the component author never modeled in a test.
Frontend-only preview deploys (the Vercel-style URL per PR) catch some of these. They provide a browser-accessible URL and allow visual inspection and manual QA. They do not catch anything that requires the backend to be connected, because the backend is not part of the preview. A rendering bug that only manifests when the component is populated with real API data, or a form that only breaks when connected to the actual auth flow, is invisible to a frontend-only preview.
A full Per-PR Preview Environment is different. The browser talks to the real backend. The auth flow is live. The API responses are real. A browser-side regression that depends on the actual data the component receives can be caught by automated tests running against the full-stack preview, not just the static frontend.
What CI Cannot Validate #5: Cross-Component Flows in a Real Runtime
CI integration tests connect components within a test harness. The test harness is not the real runtime.
A checkout flow that touches the cart service, the inventory service, the payment processor integration, the order service, and the notification queue is a cross-component flow. CI can test each service in isolation and write integration tests that stub the others. What CI cannot do is run the full flow against a real connected topology where each service is deployed, the network calls are real, the database writes propagate, and the queue processing happens asynchronously.
The behavior of cross-component flows depends on things that only appear in a real deployed runtime: actual network latency between services, real transaction semantics across database writes, genuine async processing delays, and the state that accumulates across services as the flow progresses. A timing assumption that looks fine in a synchronous test harness can produce a race condition in the real runtime. A transactional boundary that works under a test database's autocommit behavior can fail under the isolation level the production database uses.
Managed preview infrastructure that replicates the service topology closes this gap. Every PR that touches a cross-component flow can be tested against the actual service graph, not a synthetic approximation of it.
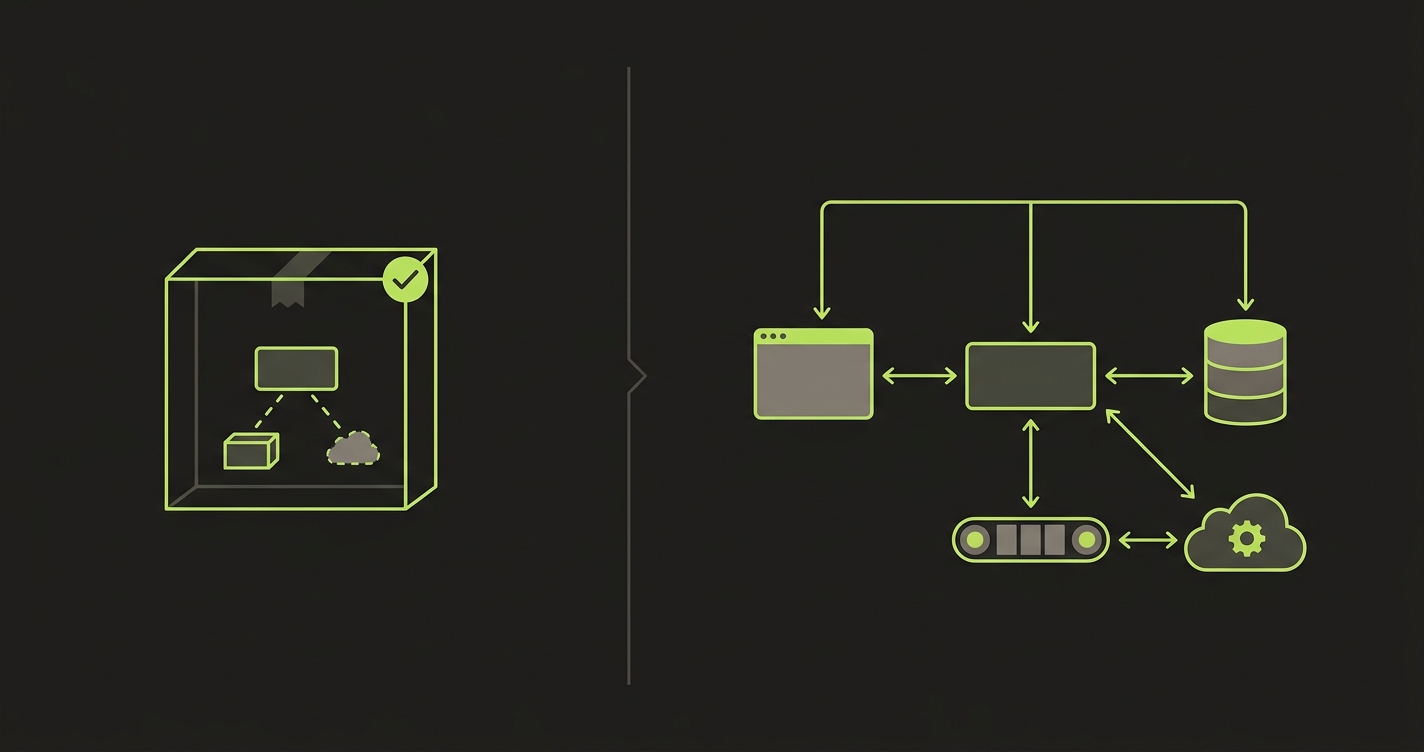
What CI Validates vs What a Per-PR Preview Environment Validates
| Validation surface | CI validates | Per-PR Preview Environment also validates |
|---|---|---|
| Code logic and unit behavior | Yes, fully | Yes (and additionally in deployed context) |
| Deployed-state behavior | No (app never runs) | Yes (app is provisioned and running) |
| Real-data shapes | Only fixture-modeled shapes | Yes (database seeded from real or representative data) |
| Third-party integration fidelity | Only mocked contracts | Yes (real sandbox API calls from deployed app) |
| Browser-side regressions | Module-level only | Yes (browser tests against full-stack deployed URL) |
| Cross-component flows | Stubbed topology only | Yes (real service graph in isolated runtime infrastructure) |
Per-PR Preview Environments: The Category Answer
Naming the five CI gaps leads to a specific category requirement: you need a real deployed runtime, isolated per PR, that includes all the services the application depends on, with real data, real third-party connectivity, and a browser-accessible frontend connected to the actual backend.
That is what Per-PR Preview Environments provide. Not a more sophisticated CI matrix. Not a better mocking framework. A deployed, isolated, full-stack runtime that is provisioned per PR, updated on each push, and torn down on merge or close.
The category has three main approaches. Heavier CI matrices (more unit and contract tests) compress the gap CI leaves but cannot eliminate it, because the deployed-state, real-data, and cross-component surfaces are unverifiable by construction inside CI. Frontend-only preview deploys catch browser-side regressions and allow manual QA of the UI layer, but leave backend, database, and queue behaviors untested because those systems are not part of the preview. DIY full-stack preview environments using Kubernetes operators and custom controllers close all five gaps but absorb a permanent per-PR orchestration, routing, secrets, and teardown cost as a platform-engineering responsibility.
Per-PR Preview Environments, as a managed category, close all five gaps without requiring the platform team to own the ephemeral infrastructure lifecycle.
How Autonoma Closes the Five Gaps on Every Preview
CI's structural blindness to the five gap categories is not a bug in CI. CI was designed to validate code, not deployed behavior. The gaps exist because the tool is being asked to validate things it was never built to observe: a running application, real data, live third-party calls, actual browser rendering, and a connected service graph. Adding more CI tests does not shrink these gaps. They require a different tool category.
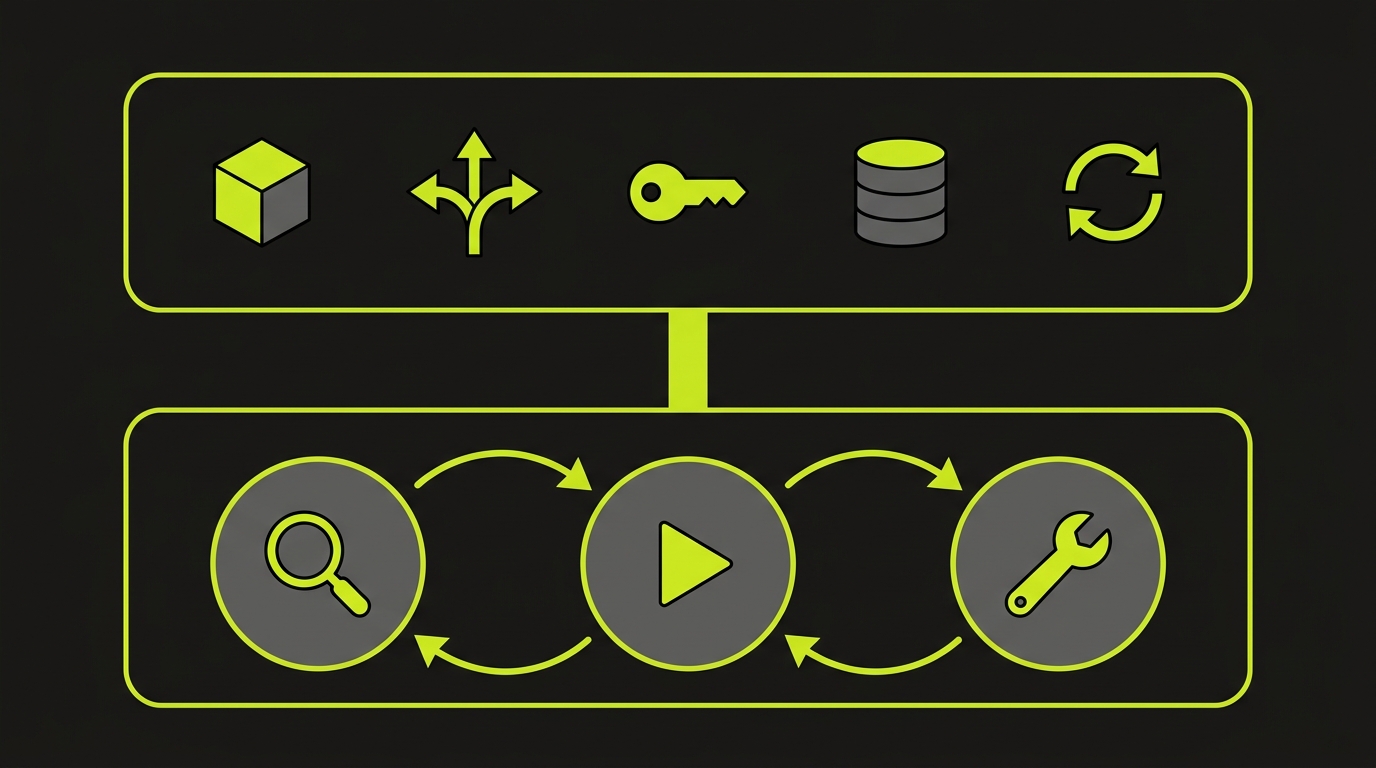
Autonoma closes all five on every PR with a two-layer product. Layer 1 is managed preview infrastructure: for each PR, Autonoma provisions a full-stack isolated runtime, replicating services, handling routing, propagating secrets, isolating the database, and tearing down the environment on close. Per-PR orchestration is operated, not built. The gaps in deployed-state behavior, real-data shapes, third-party integration wiring, and cross-component flow topology are all closed at the infrastructure layer because the application is actually running in a real, connected environment. Layer 2 runs on top: Autonoma's Planner agent reads the codebase and generates test cases from the actual routes, components, and user flows, while also generating the database-state setup endpoints each test needs. The Automator executes those tests against the running preview. The Maintainer self-heals them when the code changes. Browser-side regressions are caught by the Automator running against the full-stack URL, not a mocked frontend. The full architecture is documented in how Autonoma preview environments work.
The Autonoma Integrated Workflow: Layer 1 + Layer 2 in One Product
The two-layer architecture matters because it removes the sequencing problem teams encounter when building the two layers separately.
Building managed preview infrastructure first and then wiring an E2E testing layer on top is a legitimate path. It is also a multi-quarter platform project. The infrastructure layer requires per-PR orchestration, image builds, ingress configuration, secret injection, database provisioning, and teardown logic. Once that is stable, wiring E2E tests against dynamic preview URLs requires URL injection, authentication bypass configuration, seed scripts for database state, and a maintenance process for tests that break when the application changes.
Autonoma treats the two layers as one product. Layer 1 provisions the environment. Layer 2 runs tests on it. The Planner generates the test plan and the DB-state endpoints from the codebase. The Automator runs against the stable URL that Layer 1 provides. The Maintainer self-heals when the application changes. There is no handoff between infrastructure and testing that a platform team has to own. The ephemeral infrastructure lifecycle and the test execution lifecycle are operated together, which means the five CI gaps are closed and tested on every PR automatically, without a seed script, without a hand-maintained GitHub Actions workflow, and without a flake budget.
If your team's calling 'CI green' the start of nervous-merge time, our co-founder Eugenio walks teams through closing the gap weekly. Grab 20 min with a founder
Frequently Asked Questions
CI validates code in isolation. It runs unit tests, integration tests, and linting against mocked or containerized dependencies in an ephemeral runner. It cannot observe how the application behaves after deployment, how it handles real production-shaped data, whether third-party API contracts have drifted, whether browser rendering regressions exist, or how cross-service flows behave in a real connected runtime. All five of those surface areas require a deployed environment to validate. CI green means the code is internally consistent. It does not mean the deployed application behaves correctly.
No. CI catches bugs in code logic, type mismatches, failing unit contracts, and integration behaviors that can be reproduced in a containerized environment. It does not catch deployed-state bugs (behaviors that only manifest after the application is live), real-data-shape bugs (where production data has evolved past what test fixtures model), third-party integration drift (where an upstream API changed its response format without a version bump), browser-side regressions, or cross-component flows that span services not connected in CI. These categories require a Per-PR Preview Environment, not more CI tests.
A Per-PR Preview Environment is an isolated, full-stack runtime provisioned automatically for each pull request. It includes the application, backend services, a database with isolated state, queues, caches, and correct routing. It is provisioned when the PR opens and torn down when the PR closes. The key difference from CI is that the application is actually deployed and running, so behaviors that only manifest in a deployed state are observable and testable before merge. When CI is green but you're still nervous about merging, a Per-PR Preview Environment gives you evidence from a real deployed runtime, not just passing test cases.
'CI green but nervous' describes the experience of merging a PR when all CI checks pass, but the engineer is still unsure whether the change is safe. The nervousness is rational: CI only validates a subset of the behaviors that matter in production. Deployed-state behavior, real data shapes, third-party integration fidelity, browser rendering, and cross-service flows are all outside CI's observable surface. Teams fix it structurally by adding Per-PR Preview Environments to their pipeline, so every PR is validated against a real deployed runtime before it merges. The evidence from the preview environment replaces the nervousness with an actual signal.



