
Ephemeral environments are per-PR isolated full-stack runtime environments that spin up on PR open, receive a test suite run against them, and tear down on PR close. They deliver the most value when the testing layer ships in the same control plane: build status, live URL, and test results posted to the same PR comment. Autonoma's PreviewKit is the managed ephemeral environment platform with testing integrated by default. One .preview.yaml, no Dockerfile required, Kubernetes namespace isolation per PR, and a Replay trace artifact posted to every PR comment.
An ephemeral environment that ships every PR but skips the testing layer is doing half the job. We built Autonoma's PreviewKit so the preview environment exists and gets tested in the same control plane. One config file, one PR comment artifact, one pane of glass for build status, the live URL, and the test results that say whether the change is safe to merge.
That design decision is not obvious from looking at the rest of the market. The managed ephemeral environments category has grown substantially in the past two years, and most vendors in it have landed on roughly the same shape: connect your repo, get a URL per PR, tear it down on close. That is a meaningful improvement over shared staging. It is not a complete solution. The testing question gets deflected: "bring your own CI," "integrate whatever you're using," "we handle the environments, you handle the tests." We think that boundary is where the category falls short.
The framing matters for how you evaluate preview environments tooling. If testing is structurally external to the ephemeral environment, it will always be a configuration burden someone has to maintain. Test runners drift out of sync with environment lifecycle events. Failures get siloed in a separate CI pane that reviewers have to context-switch to check. The PR comment shows a green "preview ready" badge while the test run in another tab is still red. We built PreviewKit to collapse that gap by treating the testing layer as a first-class component of the ephemeral environment lifecycle, not an integration you wire up afterward.
What "ephemeral" means done right
An ephemeral environment is not just a short-lived URL. It is isolated runtime infrastructure that replicates the relevant production topology for a single PR and disappears cleanly when that PR closes.
Done correctly, ephemeral environments cover the full stack. That means the frontend, the backend API services, the database (either a migrated snapshot or a schema-only clone with seed data, depending on your setup), the queue layer, cache nodes, and any background workers that your application depends on. A frontend-only ephemeral environment can tell you whether a UI change renders correctly. It cannot tell you whether the change breaks a checkout flow that touches the cart API, the inventory service, and the payment queue. Service replication across the full dependency graph is what makes the environment actually representative.
Per-PR namespacing is the other structural requirement. Each PR gets its own isolated namespace: its own database instance, its own service instances, its own DNS record under a wildcard subdomain. PR #1042 and PR #1044 cannot share state. If they do, you are running two PRs against the same environment, which is just shared staging with extra steps. The isolation has to be physical, not logical.
The lifecycle is simple in principle and surprisingly hard to get right in practice. PR open triggers environment provisioning. The environment comes up in minutes, not tens of minutes, because image builds use BuildKit cluster cache (layers shared across PRs for the same base). The wildcard DNS record resolves. TLS terminates. Secrets and config propagate from your configured secret store. The environment is live. PR close triggers teardown: namespace deletion, DNS record removal, database snapshot cleanup. Nothing leaks across PRs. Nothing lingers on the cluster after the PR is merged or closed.
The concrete failure mode when teardown is not reliable: orphaned namespaces accumulate. Each one holds compute and storage. After two or three weeks, the cluster bill doubles and someone spends a Friday tracking down why. PreviewKit's teardown is event-driven from the GitHub webhook on PR close. There is no cron job, no manual cleanup step, no "remember to delete the environment when you're done."
The result is that every PR reviewer sees a URL that is live, isolated, and representative of what the change actually does. Not a URL pointed at shared staging that has been modified by five other PRs this week.
Why the testing layer is part of the definition
An ephemeral environment without tests run against it is a URL nobody trusts enough to act on.
The point of per-PR isolation is that you get a signal specific to this change. Reviewers look at the code diff; they look at the preview URL; they should be able to look at test results from that environment. If the test results live in a separate CI tab, in a different status check, or arrive fifteen minutes after the preview URL was posted, most reviewers will not look at them before approving. The friction is small and the shortcut is easy.
Every other vendor in this space treats tests as someone else's problem. The category consensus is: "We provision environments; you provision tests." That creates a structural gap. The environment lifecycle events (provisioning complete, teardown triggered) are not directly accessible to the CI system running the tests unless you build custom webhook integrations. The test run might start before the environment is ready. The PR comment shows preview URL but not test status. The review workflow splits across two systems.
We made a different decision with PreviewKit. The preview environments full-stack problem requires a testing layer because the full-stack nature of the environment is only valuable if you can verify that the full-stack behavior is correct. Provisioning an isolated Postgres instance per PR is only useful if something actually exercises the code paths that talk to that Postgres instance.
The structural argument is this: the ephemeral environment exists to give you confidence before merging. Confidence requires evidence. Evidence comes from tests. If the tests run somewhere else, on a schedule disconnected from the environment lifecycle, you do not have a confidence signal at merge time. You have a preview URL and a hope.
Treating testing as part of the ephemeral environment definition means the provisioning step and the test run share a single event chain. Environment ready triggers test run. Test run completes, results post to the PR comment alongside the live URL. The reviewer sees both without leaving GitHub.
The .preview.yaml config surface
The entire PreviewKit setup lives in a single .preview.yaml file at the root of your repository. This file is the source of truth for what gets provisioned, how services connect, and what dependency primitives the environment needs.
The config surface is intentionally narrow. You describe your services (name, build path, port), your managed dependencies (which database engine, which queue, which cache), your environment variable mappings, and any secrets references. Railpack reads the build path and auto-detects the stack. For a Node.js service, it identifies the runtime, installs dependencies, and builds the image without a Dockerfile. For a Python service, it detects the package manager (pip, poetry, uv) and builds accordingly. Go, Ruby, Rust, and PHP all follow the same pattern. You declare what the service is; Railpack figures out how to build it.
The managed dependency primitives are what make the config surface tractable for complex stacks. Rather than wiring up your own Postgres sidecar, snapshot pipeline, and connection string propagation, you declare postgres in the dependencies block and PreviewKit provisions an isolated Postgres instance for the PR, runs your migrations, and injects the connection string into the service's environment. The same pattern applies to Valkey (Redis-compatible cache), Temporal (workflow orchestration), and api-gateway routing. These are managed dependency recetas: pre-built provisioning recipes that handle the full lifecycle of each dependency type.
Secrets and config propagation works through your existing secret store. PreviewKit integrates with the standard providers. You reference a secret by name in .preview.yaml, and PreviewKit resolves and injects it at provisioning time. The preview environment never holds plaintext secrets in the config file. The reference pattern is the same as what your production deployment uses, which means the propagation logic is not a new system to maintain.
BuildKit cluster cache is worth calling out explicitly. Image builds in ephemeral environments are the primary contributor to environment provisioning time. BuildKit cluster cache shares layer cache across PRs for the same base images, same dependency files, and same build steps. A PR that touches only application code does not rebuild the OS layer or the dependency install layer. It rebuilds only the changed layers. For most web application PRs, this brings full-stack environment provisioning down to the two-to-four-minute range from a cold build that could take fifteen or more.
The .preview.yaml file does not require container expertise to write. Platform engineers write it once. Application developers never touch it unless they add a new service or dependency. The managed preview infrastructure handles everything below the config surface.
The Replay trace as a PR comment artifact
The PR comment is the control plane surface that matters most to the humans in the review workflow. PreviewKit posts a single, structured comment to each PR that carries four pieces of information: the build status for each service, the live preview URL, any failure logs from provisioning or the test run, and the Replay trace link.

The build status is per-service, not a single aggregate. If your API service built successfully but your worker service failed because of a dependency resolution issue, the comment shows exactly that. Reviewers can see which service is broken without digging into CI logs.
The live preview URL is the wildcard subdomain allocated to this PR's namespace. It resolves the moment the ingress layer finishes provisioning. If the URL is in the comment, the environment is live. Reviewers can click directly from the comment to the running application.
Failure logs from the test run appear inline in the comment, collapsed by default. A PR where all tests pass shows a green status line. A PR where tests fail shows the failure count and expands into the specific assertion failures. The reviewer sees this without leaving the PR page.
The Replay trace is the detailed run record. It captures the sequence of actions the test run executed against the ephemeral environment: which pages were visited, which interactions were performed, where assertions were evaluated, which ones failed and why. The trace links back to PreviewKit's review interface, where you can step through the run frame by frame. For failing tests, the trace shows exactly what the agent saw at the point of failure: the DOM state, the network requests, the error message. This makes the difference between "tests failed" and "the checkout button was not present on the cart page for logged-out users" immediately visible without a reproduction step.
The "one pane of glass" framing is accurate because everything the reviewer needs to make a merge decision is in a single GitHub comment. Build status, preview URL, test results, trace link. The reviewer does not switch tabs, does not go to a separate CI dashboard, does not run the change locally to verify behavior.
How Autonoma's PreviewKit operates ephemeral environments
The complete ephemeral environment lifecycle in PreviewKit starts with a GitHub webhook on PR open and ends with namespace teardown on PR close. Here is what happens in between.
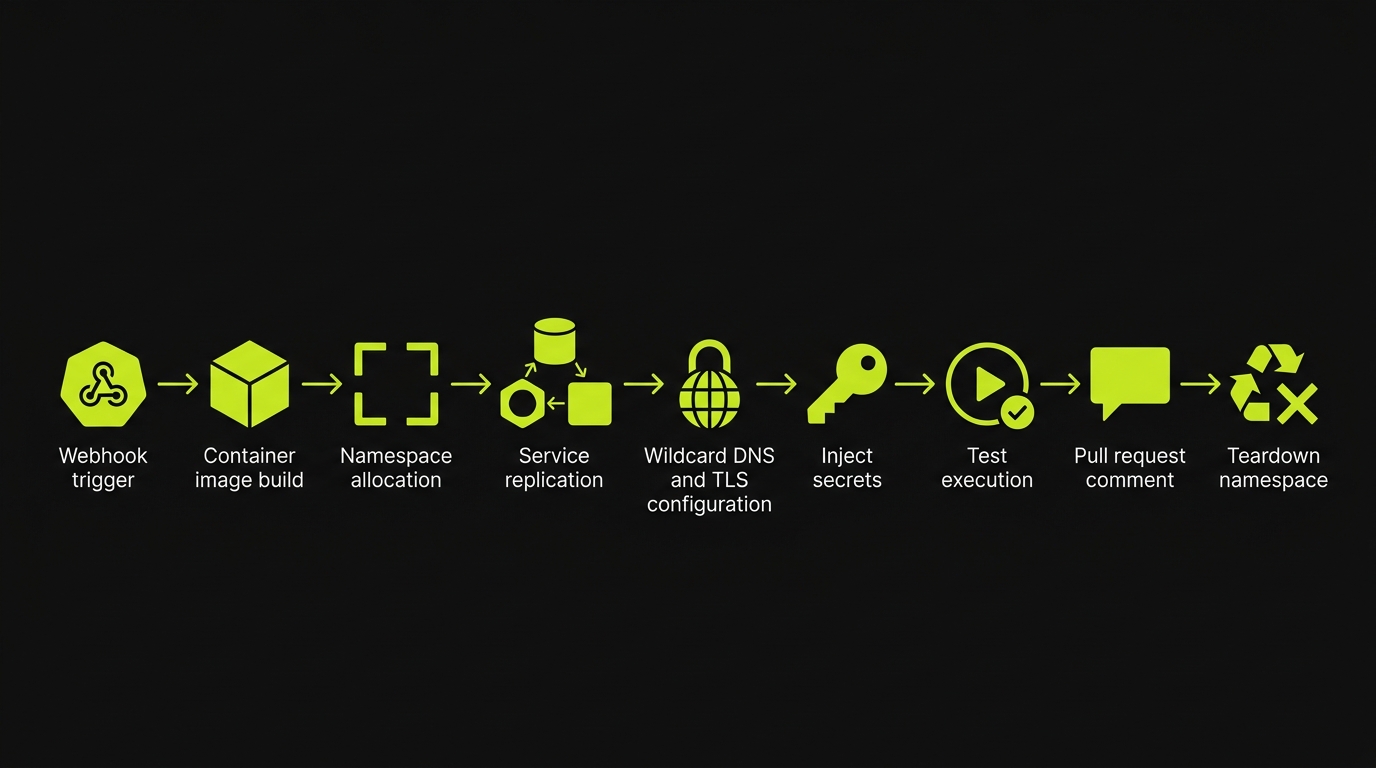
PR open webhook arrives at the PreviewKit control plane. The control plane reads the .preview.yaml from the PR's branch. It enqueues a build job for each service declared in the config.
Railpack image builds run against BuildKit cluster cache. Each service's build job identifies changed layers and rebuilds only what changed. Base layers, dependency install layers, and unchanged application layers are served from cache. Build times for typical web application PRs settle in the two-to-four-minute range after the initial cold build.
Kubernetes namespace isolation per PR is allocated once the build jobs complete. Each PR gets a dedicated namespace: a bounded resource pool with its own network policy, its own service accounts, and its own storage allocation. Namespaces are named deterministically from the repo and PR number, which means the control plane can always map a PR event back to its namespace without a lookup table.
Service replication deploys each built image into the namespace. Services start in dependency order: databases and queues first, then API services that depend on them, then frontend services that depend on the API. The managed dependency recetas (Postgres, Valkey, Temporal, api-gateway) run their own initialization sequences: schema migrations for Postgres, topology initialization for Temporal.
Wildcard DNS and TLS provision once services are running. The PR gets a subdomain under the wildcard DNS zone. TLS terminates at the ingress layer. The URL is ready.
Secrets and config propagation injects the resolved values for every environment variable reference in .preview.yaml into each service's runtime environment. Connection strings for the managed dependencies are injected automatically. References to external secret stores are resolved at this step.
Test suite kicks off once the environment passes a readiness check. The Planner agent reads the codebase to derive test scenarios covering the changed surfaces. The Automator agent executes those scenarios against the live preview URL inside the namespace. The test run is scoped to the ephemeral environment, not to a shared test account or a staging URL.
PR comment posted with the build status, the live preview URL, failure logs if any, and the Replay trace link. Reviewers see the full signal in GitHub without leaving the PR.
PR close triggers teardown. The webhook fires, the control plane deletes the namespace, removes the DNS record, and cleans up the managed dependency instances. Nothing lingers. The cluster bill does not accumulate from orphaned namespaces.
For teams evaluating the build-vs-buy decision for managed preview infrastructure, the managed preview environments without the infra breakdown covers the engineering-week estimates for building this stack in-house.
If you're picking between rolling your own ephemeral environment platform and using a managed one with testing built in, our co-founder Eugenio is happy to walk through the tradeoffs. Grab 20 min with a founder
Comparison: PreviewKit vs the rest of the ephemeral environment market
The table below compares the major options across the dimensions that matter most for platform engineers choosing an ephemeral environment solution. Full-stack preview environments detail is covered in the full-stack preview environments deep dive.
| Dimension | Autonoma (PreviewKit) | Bunnyshell | Northflank | Shipyard | Coherence |
|---|---|---|---|---|---|
| Testing integrated by default | Yes (Replay trace per PR) | No | No | No | No |
| Any stack (no Dockerfile required) | Yes (Railpack auto-detect) | Partial (needs Dockerfile) | Partial (needs Dockerfile) | Partial | Limited stacks |
| Managed DB/queue/cache primitives | Yes (Postgres, Valkey, Temporal) | Partial | Partial | Partial | Partial |
| PR-comment control plane | Yes (unified comment) | Yes | Partial | Yes | Partial |
| Open source | Yes | No | No | No | No |
| Time to first PR environment | Minutes (cached builds) | Minutes | Minutes | Minutes | Minutes |
Northflank has solid build infrastructure and strong multi-service support. It does not ship a testing layer. Shipyard offers a clean hub experience for environment management but also hands the testing question back to you. Bunnyshell covers the provisioning side competently but expects you to bring your own test runner and wire it to environment lifecycle events. Coherence has good Heroku-style simplicity for teams with straightforward stacks but narrows quickly on complex dependency graphs.
DIY Kubernetes sits outside the table by design: every row is "you build it." The orchestration layer, the image registry, the DNS automation, the secret injection, the teardown pipeline, and the testing integration are all on your platform team. The upfront cost is 15-35 engineer-weeks. The ongoing burden is roughly 0.3-0.5 of a platform engineer in steady state. For teams that have done this calculation honestly and still want to build, that is a legitimate choice. For teams that have not done the calculation, it is worth doing before starting.
The differentiator for PreviewKit is column one: testing integrated by default. Every other option in the table treats testing as an integration exercise. PreviewKit treats it as part of the definition.
What you don't have to build
The value of a managed ephemeral environment platform is most visible in the list of things your platform team does not have to build, maintain, and on-call for.
Image registry: PreviewKit manages the registry that stores the built images for each PR. You do not provision it, manage retention policies, or pay its storage bill separately.
Namespace orchestration: the Kubernetes namespace allocation, resource quota configuration, network policy, and teardown are handled by the PreviewKit control plane. Your team does not write the orchestration code or carry the pager when it breaks.
Wildcard DNS and TLS: the subdomain allocation and certificate provisioning happen per PR, automatically. You do not manage a cert-manager deployment or a Route 53 zone for preview environments.
Secret store wiring: PreviewKit resolves secret references at provisioning time from your existing secret store. You do not build a custom secret injection pipeline for ephemeral environments.
Queue and cache provisioning: the Valkey and Temporal managed dependency recetas handle initialization, connection string injection, and teardown. You do not write sidecar manifests or lifecycle scripts.
Database snapshot and teardown: the Postgres managed dependency handles migration runs, snapshot cleanup, and instance teardown per PR. You do not build or maintain a snapshot pipeline.
The testing layer: this is the one that every other vendor leaves out. The test suite scheduling, the environment readiness check, the Automator agent execution, the Replay trace generation, and the PR comment posting are all part of PreviewKit. You do not wire a CI job to a webhook, manage a test runner deployment, or build the comment formatting logic.
The list above is not hypothetical. These are the categories that platform teams building their own preview environments consistently underestimate. The managed preview infrastructure model collapses all of them into a single config file and a deployment.
Frequently Asked Questions
In Autonoma's PreviewKit, the test suite kicks off automatically once the ephemeral environment finishes provisioning. A Planner agent reads your codebase routes and components to derive test cases; an Automator agent executes those cases against the live preview URL inside the Kubernetes namespace allocated for that PR. Results feed back through the Replay trace, which PreviewKit posts directly to the GitHub PR comment alongside the build status and live URL. You do not configure a CI step, a test runner, or a webhook. The testing layer is part of the same control plane as the environment itself, not a separate pipeline you have to wire up.
No. PreviewKit handles Kubernetes namespace isolation internally. You interact with a single .preview.yaml config file that describes your services, dependencies, and environment variables. The namespace allocation, image builds via Railpack and BuildKit cluster cache, wildcard DNS, TLS termination, and teardown all happen behind the managed preview infrastructure layer. Platform engineers who want visibility into namespace topology can inspect it, but no one on your team needs to write Helm charts, manage namespaces directly, or operate the cluster. The surface exposed to your team is the PR comment and the .preview.yaml file.
Yes. Autonoma is open source, which means teams with strict data-residency, compliance, or security requirements can self-host PreviewKit on their own infrastructure. You own the runtime: the Kubernetes cluster, the image registry, the DNS zone. Autonoma provides the orchestration logic, the Railpack build layer, and the control plane that ties environment provisioning to the test run. Self-hosted deployments still get the full per-PR ephemeral environment lifecycle and the testing integration; you just run it on your own cloud account rather than Autonoma's managed platform.
Non-Docker stacks are the default case, not an edge case. PreviewKit uses Railpack for image building, which auto-detects your stack (Node.js, Python, Ruby, Go, Rust, PHP, and others) without requiring a Dockerfile. You describe your services and their dependency graph in .preview.yaml, and Railpack infers the build process. If you have an existing Dockerfile you want to use, PreviewKit respects it. But for teams that have never maintained a Dockerfile, you will get full ephemeral environment provisioning per PR from a plain config file with no container expertise required.
Cost depends on your stack shape: the number of services, the size of your database snapshots, how long each PR stays open, and how many concurrent PRs your team runs. We do not publish a per-PR rate because the variance across teams is significant enough that a published number would be misleading in either direction. The right approach is to talk through your specific stack with our co-founder Eugenio, who can give you an honest estimate based on comparable team shapes. What we can say is that the cost of a production incident caused by a change that was never tested against an isolated ephemeral testing environment is almost always larger.



