
The received wisdom is that staging environments sit at the end of every responsible release pipeline. You ship to staging, QA works through it, and only then does production get the change. Decades of shipping discipline are encoded in that sequence. But that sequence was designed for a world where you couldn't isolate environments cheaply on demand.
That world ended. The question worth asking now is not how to make staging better. It is whether staging survives as a structural requirement when per-PR full-stack preview environments are done completely.
This article argues that it doesn't. Not because staging is bad, but because the configuration that made staging necessary has been replaced by something structurally superior for fast-shipping product teams. The category is full-stack preview environments, and understanding what "full-stack" actually means in this context is where the argument has to start.
What "Full-Stack" Means for Preview Environments
The term "preview environment" carries a lot of accumulated meaning from Vercel and Netlify's deployment previews, which are frontend deployments: a build artifact served from a unique URL, pointing at whatever backend URL is configured in the environment variables. That backend is usually a shared development server or, on better-organized teams, a staging environment. The preview is isolated at the frontend layer. Everything behind it is shared.
This is not a full-stack preview environment. It is a frontend preview connected to a shared backend, and why preview deployments alone aren't enough covers the layer-by-layer gap analysis between a frontend preview and a complete environment.
A note on terminology before going further. Ephemeral environments is the infrastructure-layer term for the broader pattern: any isolated piece of infrastructure provisioned on demand and torn down when no longer needed. Preview environments is the developer-facing term for the per-PR specialization of that pattern. Every full-stack preview environment is an ephemeral environment, but not every ephemeral environment is per-PR. The full-stack preview environment is the per-PR specialization with complete runtime isolation. The two terms are used interchangeably across the rest of this article when no distinction matters.
Isolated runtime infrastructure is the meaningful distinction. In a genuine full-stack preview environment, the isolation boundary extends across the entire runtime that the application depends on. That means frontend, API service, background workers, the database, the cache layer, and any queues. Every service that can affect the behavior the reviewer is evaluating is scoped to the PR.
The mechanism that makes this possible at scale is service replication: rather than spinning up entirely new infrastructure from scratch for every PR, the orchestration layer creates lightweight, isolated replicas of each service using the same container images or deployment artifacts that production runs. A Postgres branch created by Neon or PlanetScale is a service replication event: the database engine is not re-provisioned, but a copy-on-write branch is forked at the current state so the PR environment has its own data surface. A containerized API service started with PR-specific environment variables is another replication event.
Environment routing connects these replicas into a coherent preview. When the PR environment is provisioned, the orchestration layer generates a unique hostname or URL namespace and injects the correct service endpoints into each service's configuration. The frontend preview knows to call the PR's API container rather than the shared dev server. The API container knows to connect to the PR's database branch rather than the shared dev database. Workers know to consume from the PR's queue partition rather than a shared queue. The routing layer is what makes the isolated replicas function as a single coherent environment rather than a collection of disconnected services.
For a deeper look at each layer of the stack and the specific implementation tradeoffs per service type, per-PR preview environments across frontend, backend, database, and queues covers the implementation in full.
The category claim here is precise: full-stack preview environments are not "Vercel preview deploys with a backend bolted on." They are a complete replication of the production runtime, scoped to a single pull request. That distinction matters because the entire argument about staging depends on it.
What "Without Shared Staging" Means Structurally
Staging environments exist to solve a specific problem: how do you validate a change against real infrastructure before it hits production, without risking production? The answer in the traditional model is a shared, long-lived environment that mirrors production and sits in front of it in the release pipeline.
That answer depends on two structural conditions. First, integration testing can only happen in a place where all the services are connected. Second, that place has to be shared because spinning up a complete, isolated environment per change is not economically feasible.
Per-PR orchestration invalidates the second condition. When you can automatically provision a complete, isolated runtime for every pull request through a CI trigger, the "shared" property of staging stops being necessary. The environment is still pre-production. The services are still connected. The integration is still real. What changes is that every PR gets its own instance rather than queuing up behind other changes on a shared server.
The implication is structural. Shared staging is not just a slower version of per-PR full-stack environments. It is a different configuration, designed for different constraints. When the constraints change, the design decision should change with them.
The honest version of this claim is not "delete staging today." It is a sharper question:
Is staging a structural requirement, or institutional habit?
Those are different questions with different answers. Institutional habit is legitimate: organizational trust in a process, compliance workflows that assume a staging sign-off, contracts with external systems that require a stable pre-production endpoint. These are real reasons to keep staging running.
But structural necessity is different. Staging is structurally necessary when there is no alternative way to validate integration before production. When every PR has its own ephemeral infrastructure lifecycle (provisioned on open, torn down on merge, isolated from every other PR), that necessity is gone. The argument for keeping staging becomes an argument about organizational inertia, compliance requirements, or specific non-functional testing scenarios, not about fundamental architectural need.
The first hub in this cluster, on preview environments for every pull request, covers the baseline case for per-PR environments. This article picks up from there: once the baseline is established, what does the complete configuration look like, and what does it replace?
Why This Configuration Is the Better Default for Fast-Shipping Teams
Shared staging is a serialization point. That is both its defining property and its core failure mode for teams shipping frequently.
Consider what happens when three engineers have PRs in flight simultaneously. All three deploy to staging. The third deployment may overlay environment state from the first two. The second engineer's change depends on a database migration that the third engineer's PR has not yet applied. QA works through the first feature, finds a bug, flags it, and now staging is broken and engineers two and three are blocked waiting for a fix and a redeploy. This is not a dysfunction of a poorly-run team. It is the predictable behavior of a shared mutable environment under load.
Per-PR full-stack preview environments parallelize what staging serializes. Engineer one, two, and three each have an isolated runtime. Their migrations run in isolation. Their test data is scoped to their PR. A broken environment on one PR does not block another. QA, reviewers, and automated tests can work in parallel across all three environments simultaneously.
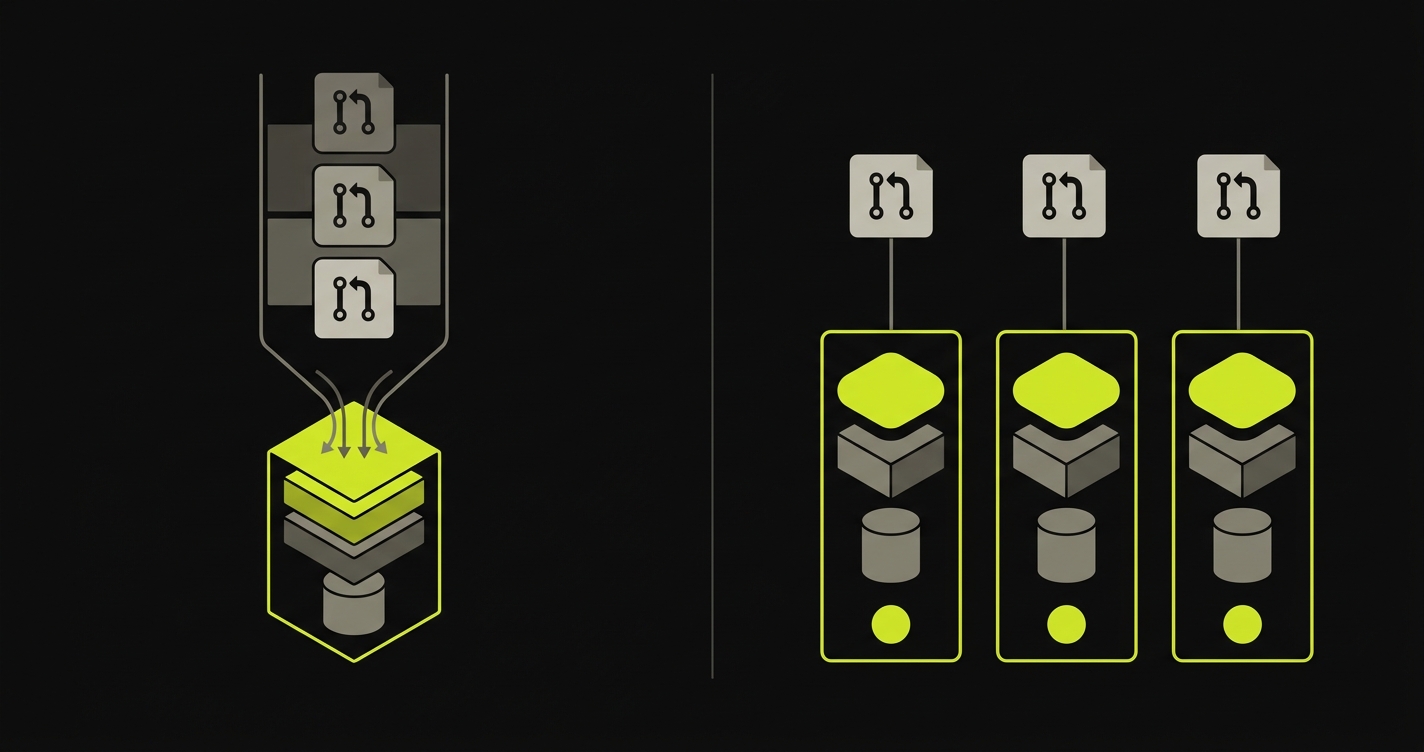
The feedback latency difference compounds this. With staging, the path from "code is written" to "integration is validated" runs through a shared queue: deploy to staging, wait for QA availability, get feedback, fix, redeploy, re-queue. With per-PR full-stack environments, integration validation can happen automatically as part of CI, against the preview environment, with results reported in the PR before the first human reviewer opens it.
Runtime fidelity is the third structural improvement. Staging typically runs at a reduced resource configuration relative to production. It shares a single database instance rather than per-feature isolation. Its queue workers are often scaled down. A full-stack preview environment, built from the same container images and provisioned by the same orchestration layer as production, can match production's runtime characteristics more closely precisely because it is not a permanent, cost-optimized shared server. This is the property that motivated us to build Autonoma the way we did. Rather than treat the preview as a degraded staging clone, we treat it as a production-shape replica scoped to one PR, so the runtime characteristics that matter for catching real bugs survive the trip.
The tradeoff that staging defenders correctly identify is cost. Per-PR environments require infrastructure for every open PR. That cost is real. But the cost model is fundamentally different: you pay for the duration of each PR's review cycle, not for a server running 24/7 whether or not anyone is testing. For teams shipping multiple PRs per day, the cost per environment is often lower than the opportunity cost of the serialization delays staging imposes. The broader analysis of preview environments as a staging replacement covers the cost comparison in detail.
That said, there is an honest concession to make. A small set of pre-production concerns are still served better by a long-lived environment than by per-PR ephemeral environments: sustained load and soak testing that need to run for hours or days against stable infrastructure, third-party sandbox integrations that cannot be branched per PR (some payment processors, identity providers, and ERP sandboxes only issue one persistent test endpoint per organization), and compliance workflows that depend on a fixed sign-off environment for audit reasons. Most teams that move to full-stack preview environments keep a thin staging tier for these residual cases. The shift is not "staging is gone"; it is "staging is no longer the default place pre-production validation happens."
Comparing Configurations: Frontend Preview Plus Staging vs. Per-PR Full-Stack
| Dimension | Frontend preview + shared staging | Per-PR full-stack preview environment |
|---|---|---|
| Isolation completeness | Frontend isolated per PR; backend, DB, queues shared | Full runtime isolated per PR across all services |
| Conflict surface | High: shared DB state, deploy ordering, debug interference between PRs | Minimal: each PR has its own data, services, and runtime state |
| Feedback latency | Hours to days: deploy queues behind other changes, waits for QA | Minutes: environment spins up in CI, tests run against the preview URL automatically |
| Runtime fidelity | Frontend matches production; backend often runs on scaled-down shared infrastructure | All services run from the same images and config as production, at PR scope |
| Operational cost | Fixed staging server cost plus per-PR frontend hosting; staging runs 24/7 | Usage-based per PR: environment cost is duration multiplied by resources, not always-on |
| Concurrency behavior | PRs serialize on the shared staging instance; one bad deploy blocks everyone | PRs run in parallel; failures are scoped to a single PR and do not block others |
The Four Staging Assumptions Per-PR Full-Stack Preview Environments Break
"Staging is the only place we test against real services"
This assumption holds when service replication is not available. If spinning up an isolated database, queue, and backend for every PR is not feasible, then staging is necessarily the single environment where you can test the full integration graph.
Service replication makes the assumption false. When a per-PR environment provisions an isolated database branch via Neon or PlanetScale, isolated queue partitions via Redis namespacing or SQS queues, and a containerized backend replica with PR-scoped environment variables, each PR is a place where you test against real services. The services are not shared with other PRs or with staging. They are the real service implementations, replicated at PR scope.
The operational implication is significant: staging stops being the chokepoint for integration testing. You can run integration tests in CI against the PR's preview environment and have the results before the code review begins, not after a QA team completes a manual pass on the shared staging instance.
"Staging holds the canonical pre-prod data"
Shared staging typically maintains a database with representative data accumulated over time: test accounts created weeks ago, orders in various states, edge-case records that reflect the long tail of production behavior. This accumulated state is genuinely useful for manual exploratory testing.
The full-stack preview environment approach replaces this with ephemeral data fixtures and per-PR database branches. Rather than relying on accumulated data that may be inconsistent or stale, each PR environment is provisioned with a seeded dataset that represents the scenarios the PR needs to exercise. The seed is code, committed alongside the application, version-controlled, and reproducible.
This is a more reliable property than accumulated staging data. Staging data drifts: records are created for one test scenario and left behind for the next, creating interference. Seeded PR data is deterministic: the same seed runs the same scenarios every time. The tradeoff is that exploratory testing against long-lived, accumulated state requires staging or an equivalent persistent environment. For teams running structured automated tests on preview environments, this tradeoff is acceptable.
"Staging is where integration testing happens"
The phrase "integration testing happens in staging" is really a statement about when in the development cycle integration is validated: after code review, before production. Per-PR orchestration does not change when validation happens. It changes where.
When per-PR orchestration automatically provisions a complete runtime for every pull request, integration testing moves from "after code review on a shared server" to "during code review on an isolated per-PR environment." The integration is validated earlier, in parallel with the human review, by automated tests that run against the PR's own stack.
This is a shift-left outcome. The same validation that staging provided, happening sooner, in isolation, without serialization. It is not that integration testing stops happening. It is that it stops requiring a shared server and a manual queue.
"Staging is cheaper than per-PR infrastructure"
This assumption is intuitive but depends on a specific cost model. Staging is a fixed cost: you pay for the server, the database, and the supporting infrastructure whether or not anyone is actively using it. A team paying $400/month for staging infrastructure pays $400 regardless of whether they ship 3 PRs or 30 that month.
Per-PR full-stack environments are usage-based. The cost is the duration of the environment multiplied by the resources it consumes. A PR that is open for 4 hours, running a backend container and a database branch, costs substantially less than a month of staging server time. Ephemeral infrastructure lifecycle is what makes the cost model fundamentally different: the environment exists only while the PR is active, and the meter stops at teardown.
For teams shipping at high velocity, the aggregate cost of per-PR environments at reasonable PR review durations is often lower than the fixed cost of staging. The calculation inverts for teams shipping slowly: low PR volume means low environment usage, but staging costs the same regardless. The cost calculus also depends heavily on what you have to operate to get there. Building per-PR orchestration in-house adds a maintenance cost line item that doesn't show up in the cloud bill; managed implementations like Autonoma move that cost into a single line item and let the per-PR usage model do the rest.
The real cost comparison also needs to account for the opportunity cost of staging serialization: engineers blocked waiting for staging to clear, QA time spent triaging conflicts between concurrent deploys, rollbacks triggered by integration failures that per-PR isolation would have caught in the PR rather than in staging.
Want to implement this at your company today? Schedule a call here.
Implementing Full-Stack Ephemeral Preview Environments: Three Paths
Teams typically reach full-stack preview environments through one of three paths. Managed preview infrastructure is one of them, not the category itself.
The first is building in-house on Kubernetes or Terraform. If the team already has a platform engineering function and Kubernetes in production, namespace-per-PR is the natural implementation: each PR gets its own namespace with its own deployments, services, and ingress rules. This path has high upfront investment (the orchestration logic, the routing, the teardown automation, the secret management) but gives the team complete control over every layer.
The second is adopting a managed preview environment platform. Autonoma is one canonical implementation of the full-stack configuration this article describes: per-PR orchestration, service replication across the full stack, environment routing, and automated teardown, without requiring the team to build or maintain the orchestration layer. Other platforms in this space take different cuts of the problem. The category is the configuration; no single vendor owns the definition.
The third path is incremental evolution: CI scripts that deploy a PR branch to a development server, gradually becoming more isolated as the team adds database branching, then worker isolation, then proper routing. Most teams that have built full-stack preview environments organically followed something like this path, adding isolation layers over time until they had the complete configuration.
What these paths share is the end state: a system where every PR has its own isolated runtime, provisioned automatically, torn down automatically, and capable of running the full integration test suite without coordinating with a shared environment. Once that state is reached, staging's structural role is gone. The operational details of how that runtime is born and destroyed are covered in the preview environment provisioning lifecycle, which is the Day 2 view of the same system.
For teams that have not yet reached that state, the comparison table and the four broken assumptions above are a way to evaluate how close the current setup is. The closer the team is to full isolation across all layers, the weaker the structural argument for keeping shared staging becomes. For teams still weighing the decision at the margin, the detailed comparison of preview environments vs staging environments maps the tradeoffs dimension by dimension.
What full-stack preview environments look like with Autonoma
The four staging assumptions above describe what breaks when teams keep shared staging as the integration substrate. The same four axes are a useful map of what a managed full-stack implementation has to handle, so here is how Autonoma behaves on each one.
On the "real services" axis, every PR gets its own backend, queue, worker, and cache replicated alongside the frontend, not just a deploy URL pointed at a shared API. Real services in this configuration means real per-PR services, so an integration regression in one PR cannot mask another PR's bug by sharing a process. On the "canonical pre-prod data" axis, each PR gets either a branched database copy or a freshly seeded schema, chosen per project. The data is scoped to the branch, which removes the migration-collision and snapshot-drift modes that staging quietly accumulates. Reviewers and tests interact with data that belongs to the PR they are reviewing, not data left behind by an unrelated release.
On the "integration testing" axis, the testing suite runs natively against each preview environment on every push, with merge blocked on failure. Integration testing happens against the per-PR runtime rather than against shared staging, which removes the serialization that makes integration the slowest part of most release pipelines. On the "cost" axis, the environment exists only while the PR is active and tears down on merge or close, so the meter is usage-based and not a fixed monthly line item. The orchestration cost lives inside the platform rather than as in-house GitHub Actions and cleanup scripts the team has to keep operating. Autonoma is open-source, runs against any tech stack with no per-language adapter, and ships the integrated test layer as part of the same control plane that operates the environments. That last property is the structural reason the four staging assumptions stay broken once the team moves to per-PR full-stack: the testing loop and the environment loop are not two systems that have to be glued together.
Want to implement this at your company today? Schedule a call here.
FAQ
Not structurally. When every pull request has its own isolated runtime including frontend, backend, database, queues, and workers, shared staging loses its defining function: serializing pre-production validation. Teams that move to full-stack preview environments typically keep staging for a narrow set of non-functional concerns like load testing, long-lived compliance data, and third-party sandbox integrations that cannot be branched. For functional testing, shared staging becomes redundant.
An ephemeral environment is an isolated piece of infrastructure provisioned on demand and torn down when no longer needed. In a preview-environments context, it is the runtime stack created when a pull request is opened and destroyed when the PR is merged or closed. The lifecycle is what makes it ephemeral; the isolation is what makes it useful. Full-stack ephemeral environments extend that isolation across the entire runtime, not just the frontend.
Preview environments is the developer-facing term: the per-PR deployment, the unique URL, the bot comment in the pull request. Ephemeral environments is the infrastructure-layer term for the pattern of spinning up and tearing down isolated infrastructure on demand. Every preview environment is an ephemeral environment, but ephemeral environments also include non-PR workflows like on-demand QA environments and load-test clusters. Full-stack preview environments combine both concepts: ephemeral in lifecycle and complete in scope.
Yes, through selective service replication rather than replicating every service for every PR. The standard pattern is to replicate the services touched by the PR and any tightly coupled dependencies, then share stable upstream services through a routing layer. This keeps the per-PR footprint proportional to the change rather than to the size of the whole architecture. For very large microservice estates, a request-level isolation pattern can route only the requests for a given PR to PR-specific service replicas, with everything else hitting shared infrastructure.
Yes, through database branching rather than full clones. Platforms like Neon and PlanetScale use copy-on-write branching, so a database branch costs storage only for the rows that change during the preview's lifetime, not a full copy of production. Teams with very large datasets often use a representative subset or synthetic seed data. The cost is duration-based, so most preview databases are inexpensive because they live for hours to days, not months.
A Vercel preview deploy is a frontend deployment: it builds and hosts the frontend bundle at a unique URL per branch, connected to whatever backend URL is in the environment variable. That backend is typically a shared development or staging server. A full-stack preview environment adds per-PR service replication for backend services, an isolated database branch, queue and worker isolation, and secrets/config propagation scoped to the PR. The Vercel preview is the starting point, not the complete configuration.
Per-PR orchestration is the system that coordinates environment creation, routing, and teardown for every pull request without manual steps. In practice: a CI trigger on PR open provisions the runtime stack, an environment routing layer generates a unique URL and injects the correct service endpoints into each service's config, secrets/config propagation scopes secrets to the PR environment, and a teardown trigger fires on PR merge or close. The orchestration layer is what separates a genuine per-PR full-stack environment from a manually-stood-up test environment.
Every service whose state or behavior can influence the test result: the frontend deployment, the API or backend service, the primary database, background job workers, caches if they hold application state, and auth services if they issue tokens bound to environment URLs. Stateless services that call only external APIs and carry no local state can often share infrastructure without breaking isolation guarantees.
Secrets and configuration need to be scoped to each PR environment to prevent cross-environment interference and credential leakage. In practice, the orchestration layer maintains a secrets store (AWS Secrets Manager, HashiCorp Vault, or a platform-native equivalent) keyed by environment ID. When a PR environment is provisioned, the orchestration layer injects the environment-specific values into the service's runtime: database connection strings pointing at the PR's database branch, API keys for sandbox-tier third-party services, auth service URLs bound to the preview URL. At teardown, those scoped credentials are revoked. This is one of the harder operational problems in building a full-stack preview environment from scratch.



