
Ephemeral environments (also called per-PR preview environments) give every pull request its own isolated, short-lived deployment of your full application stack. Isolation is six distinct problems: per-PR URL routing for the frontend, service replication for the backend, branching or snapshot-restore for the database, environment routing for queues, namespace prefixing for caches, and a mock-or-real choice for external services. Each layer has its own failure mode when isolation is incomplete, and this article covers all six.
When engineers say they want ephemeral environments, they usually mean a single thing: "spin up a fresh deployment for this PR, then tear it down." That framing works for frontend-only apps. For anything that touches a database, processes background jobs, or integrates with third-party APIs, it hides most of the problem.
The word "isolated" is doing enormous work in that sentence. A frontend deployed to a unique subdomain is isolated. The backend it talks to is probably still shared staging. The database that backend writes to is definitely shared. The queue consumers processing orders in the background are shared. The Redis cache that drives rate-limiting and session state is shared. The Stripe webhooks coming in are routing to... whatever they were routing to before.
A truly isolated preview environment isolates every layer of the stack, not just the surface URL. Full-stack preview environments without shared staging require solving isolation at every layer of that stack, and why preview deployments alone aren't enough walks through the diagnostic view of what each missing layer breaks. The rest of this article does that systematically, one layer at a time. The provisioning and teardown lifecycle of these environments is a separate concern we cover separately.
Layer 1: Frontend Isolation
Frontend isolation is the solved problem. Vercel, Netlify, Cloudflare Pages, and a dozen other platforms handle it natively: every push to a PR branch triggers a build and produces a unique preview URL. The CDN serves that build from an isolated origin. No two PRs share a deployment artifact.
The mechanism is simple: a reverse proxy or CDN routing rule maps an incoming hostname (or path prefix) to a specific build artifact. pr-142.preview.example.com serves the build from branch feature/checkout-redesign. pr-143.preview.example.com serves a different build. The two never share state because they are different static artifacts served from different origins.
What leaks when this layer's isolation is incomplete is subtle but consequential. Cookie domain scope is the classic failure mode. If your authentication cookie is scoped to .example.com rather than the specific subdomain, a logged-in session from pr-142.preview.example.com is readable by pr-143.preview.example.com. Any PR that touches auth logic is now testing against session state it didn't create. CORS configuration has a similar failure mode: if the backend's allowed-origins list is a wildcard over *.preview.example.com, every preview environment can make authenticated requests to the same shared backend, which is probably not what you want.
A related failure mode that catches teams off guard is OAuth callback handling. Authentication providers like Google, GitHub, and Auth0 typically require pre-registered redirect URIs and reject wildcard subdomains, so a freshly minted pr-142.preview.example.com cannot receive an OAuth callback unless its URL was registered in advance. The two practical fixes are a dedicated callback proxy domain that re-routes to the per-PR origin via a state-encoded slug, or a fixed pool of pre-registered redirect URIs leased to PR slots as they open and close. Neither is hard, but both have to be designed in.
The operational cost of getting frontend isolation right is low, with one prerequisite: wildcard DNS records and automated certificate provisioning (typically cert-manager with Let's Encrypt, or the equivalent on a managed PaaS) need to exist before per-PR subdomains can resolve at all. Set the correct cookie domain scope. Lock CORS to the specific PR origin, not the wildcard. Use per-PR environment variables to point the frontend at its own backend instance (not the shared one). The infrastructure work is minimal; the configuration discipline is where teams slip.
Layer 2: Backend Isolation
Backend isolation is where per-PR preview environments for every pull request get significantly harder. A frontend build is a static artifact. A backend is a running process with configuration, a database connection, queue consumers, and often significant startup cost. Isolating it per PR means running one instance per open PR.
The dominant technique here is service replication: spin up a new instance of the API server for each PR, scoped to that PR's environment namespace. In a Kubernetes cluster, this means a new Deployment with its own pods, a new Service, and an Ingress rule that routes api-pr-142.preview.example.com to that Deployment's pods. In a Docker Compose-based setup, it means a separate Compose project per PR with a project-specific network. In a cloud-native setup with Lambda or Cloud Run, it means a separate function configuration with its own environment variables.
What leaks when backend isolation is incomplete is more serious than the frontend case. The most common failure: two PRs share a backend, so a schema migration in PR A runs against the same database connection pool that PR B is using. PR B's tests start failing because the schema it was written against no longer exists. The engineers on both PRs spend an hour debugging what looks like a test environment flake before realizing the environment is genuinely broken.
The second common failure: shared backend instances mean shared memory. Any in-process state, in-memory caches, or singleton services are shared across all PR traffic. A PR that tests rate-limiting behavior by hammering the API will exhaust the in-memory rate-limit counters for every other PR using the same backend instance.
The operational cost of service replication is real. Per-PR orchestration of backend instances requires infrastructure automation: a pipeline that provisions a new instance on PR open, updates it on each push, and destroys it on PR merge or close. That's a non-trivial GitHub Actions workflow or a dedicated tool. It also has a compute cost: N open PRs means N backend instances running simultaneously, each consuming CPU and memory. Teams with small PRs and fast iteration cycles can hit dozens of simultaneous environments. Past roughly 20-30 concurrent backend instances, per-PR replication starts to strain non-prod compute budgets unless aggressive idle-shutdown policies are in place.

Layer 3: Database Isolation in Ephemeral Environments
Database isolation is the hardest layer. It is also the most consequential when it fails.
The three techniques in common use are distinct and not interchangeable. Understanding the tradeoffs between them is the core of database isolation inside per-PR preview environments, which we cover in depth separately. Here is the high-level architecture of each.
Database branching (offered by Neon, PlanetScale, and similar products) treats the database the way Git treats source code. The main branch is production or staging. Opening a PR creates a new database branch that forks from the parent at the moment of branch creation. The fork is copy-on-write: reads that hit unmodified blocks go to the parent, writes and subsequent reads of modified data go to the branch. Schema migrations, seed data operations, and test data writes from the PR are scoped to that branch and never touch the parent.
This is the cleanest model. The PR's backend connects to a branch-specific connection string. Migrations run against the branch. When the PR is merged or closed, the branch is deleted. No cleanup logic beyond branch deletion. The cost is vendor lock-in to a branching-capable database provider, and branch creation adds seconds to the environment provisioning time.
Ephemeral schemas work within a single database server. Rather than branching the entire database, the provisioning step creates a new schema (in Postgres, a namespace within a database) for each PR. The schema is seeded from a migration baseline and populated with test fixtures. The backend is configured to connect using that schema's search path. Schema deletion on PR close is instant.
This approach works with any Postgres-compatible database and requires no special vendor support. The failure mode is subtle: cross-schema references. If any database function, view, or trigger references an object in the default schema by a fully-qualified name, those references bypass the per-PR schema isolation and hit shared objects. Foreign key constraints across schemas also cause problems. Ephemeral schemas work cleanly for self-contained data models and become fragile when the schema has significant cross-cutting database objects. As a rough scaling guardrail, this approach holds up well for up to 10-20 concurrent PRs against a single Postgres instance; beyond that, connection pool exhaustion and shared-database-object collisions begin to dominate.
Snapshot-restore provisions a full database instance per PR, initialized from a snapshot of a known-good state (typically a recent production anonymized snapshot or a dedicated seed snapshot). Each PR gets its own RDS instance, Cloud SQL instance, or Docker-run Postgres container. No schema leakage is possible because there is no shared server.
The tradeoff is cost and provisioning time. A full database restore takes minutes, not seconds. Running N database instances for N open PRs is expensive, especially if the database is large. For databases over 10GB, snapshot-restore typically becomes cost-prohibitive past 20-30 concurrent environments; ephemeral schemas or branching scale further at lower per-PR cost. Teams using this approach typically implement size-capped snapshots (seed data only, no production data), aggressive teardown on PR inactivity, and max-environment counts.
What leaks when isolated database preview isolation fails spans both correctness and security. Data mutations from one PR's test run contaminating the baseline that another PR is testing against is the most common correctness failure. The security failure is more serious: if a PR under test for a multi-tenancy fix is running against a shared database that contains other tenants' data, a bug in that PR can expose real data during the test run, even in a preview environment. The pattern we landed on while building Autonoma was to make the database isolation choice user-selectable per PR rather than hard-coded at the platform layer (branching when the database engine supports it, ephemeral schemas otherwise, snapshot-restore as the fallback for tightly regulated stacks), because the right answer is usually a function of the application's data shape, not a platform default.
Layer 4: Queue Isolation
Queue isolation is underspecified in most preview environment setups. Teams build frontend isolation, invest effort in backend isolation, get database branching working, and then leave their message queues entirely shared. The queues feel like infrastructure, not application state. They are application state.
The correct mental model: a message queue is a mutable data store with a time dimension. A job enqueued by PR 142's test run will be dequeued and processed by a queue consumer. If that consumer is the shared staging consumer, it runs in a context where the database schema may be different, the business logic may be different, and the processing outcome has no relationship to what PR 142 was trying to test.
The dominant pattern for queue isolation is environment routing. Each PR is assigned a namespace prefix or a set of dedicated queue names. The backend instance for that PR enqueues jobs to pr-142.order.created instead of the shared order.created. The worker instances for that PR subscribe to the PR-scoped queue names. The routing is controlled by environment variables injected at per-PR orchestration time.
This sounds simple. The operational complexity is in the workers. Isolating the queue names is straightforward. Deploying isolated worker instances per PR requires the same service replication logic as the backend, applied to every worker service in the system. A system with five separate worker types needs five separate worker deployments per PR, each consuming the same compute resources as the backend instances. For systems with five or more worker types, full per-PR worker replication is typically the dominant compute cost in the entire preview infrastructure.
What leaks when queue isolation is incomplete is jobs from the wrong PR. A payment processing job enqueued by a PR testing a pricing change gets picked up by a worker running the current stable code. The job processes at the old price. The test reports success. The bug ships. This class of failure is particularly insidious because it produces false positives: the test passes, but the pass is meaningless because the job was processed in the wrong context.
For queuing systems with native namespace or virtual host support (RabbitMQ virtual hosts, Kafka consumer group scoping, SQS queue-per-environment), the implementation is cleaner. The distinction worth being explicit about: native namespacing enforces isolation in the broker itself. A misconfigured consumer attached to a RabbitMQ vhost literally cannot see another vhost's messages, because the broker process refuses to route them. Convention namespacing, like prefixing Kafka topics with pr-142., is enforced only by the application code that respects the convention. One missed prefix in one producer or one consumer is enough for silent contamination. For systems where the queue is effectively a database table (Sidekiq/Redis, Delayed::Job/Postgres), the isolation strategy is the same as the underlying store's isolation strategy. We made queue and worker replication a default in Autonoma for exactly this reason: the failure modes are silent, the tests still pass, and the bugs only surface in production. That is precisely the class of bug a preview environment is supposed to catch.
Layer 5: Cache Isolation
Cache isolation is the layer teams most commonly get wrong in the direction of over-isolation. Some teams run a Redis instance per PR. Most should not. The more common and operationally sensible approach is namespace isolation within a shared cache server, achieved through secrets/config propagation.
The mechanism: at provisioning time, each PR environment is assigned a unique prefix string (typically the PR number or a hash of the branch name). Every cache key write and read in the application code is prefixed with the environment-specific value. In practice, this means the application's cache client is initialized with a key prefix from an environment variable: CACHE_KEY_PREFIX=pr-142. The application writes to pr-142:session:user_99. The shared staging environment writes to staging:session:user_99. The two namespaces never collide.
This approach has low compute cost (one Redis server regardless of PR count) and near-zero provisioning time (setting an environment variable, not spinning up infrastructure). The secrets/config propagation step is the same step that injects database connection strings and queue namespace variables. It's a single configuration layer that drives isolation across multiple dependent systems.
What leaks when cache isolation is incomplete is shared session state and shared rate-limit counters. The shared-session case is a correctness failure: a test that logs in as user A in one PR environment populates the session cache entry for user A, which is then readable by a different PR's test run that expects a clean session state. The rate-limit case is an operational failure: a PR running load tests hammers the Redis rate-limit counters, exhausting tokens for every other PR environment that shares the same key namespace.
A subtler failure mode is cache invalidation logic itself. If a PR changes how the application invalidates or sets TTLs on cached values, the new logic still operates on a shared Redis instance. A PR that introduces a bug in the invalidation path can leave stale entries that other PRs read, even when the key prefixes are technically isolated, because the eviction-policy and memory-pressure dynamics of the shared instance are global. Namespace isolation handles key-level collision, not instance-level resource interactions.
The one case where per-PR Redis instances are justified is testing Redis-specific behavior directly: eviction policies, pub/sub semantics, cluster failover. If the PR under test changes how the application uses Redis at the infrastructure level, namespace isolation is insufficient. A dedicated instance eliminates all interference. But for the vast majority of PRs, namespace isolation via environment-variable-propagated prefixes is the correct default.
Layer 6: External-Service Isolation
External services introduce a different class of isolation problem. Every layer so far has been infrastructure you control. External services (payment processors, email delivery providers, object storage, SMS gateways) are not under your control. Isolation means choosing how to handle them, not how to isolate your instance of them.
The choice is binary: mock or real.
Mocking external services means your PR environment never makes outbound calls to Stripe, SendGrid, or S3. Requests that would go to those services are intercepted and handled by a local mock server (WireMock, Mockoon, or a custom HTTP stub). The mock returns predetermined responses. You test that your code handles those responses correctly.
The advantages are predictable: no external cost per test run, no rate-limit risk, no dependency on third-party uptime, deterministic responses for every test case including error paths and edge cases that are difficult to trigger against a real API. The disadvantages are also predictable: you're testing against a contract you wrote, not the contract the external service actually enforces. Stripe's idempotency behavior, SendGrid's rate-limit response headers, and S3's eventual-consistency semantics are all things a mock can misrepresent.
Using real external services in sandbox mode means your PR environment makes actual calls to Stripe test mode, SendGrid sandbox, and the S3 equivalent. You get real API behavior. You also get real constraints: Stripe test mode has rate limits, SendGrid sandbox doesn't deliver emails but does consume send quota, and S3 buckets created per PR will accumulate unless cleanup is automated.
The operational cost of real services is in the scaffolding. You need per-PR API keys or per-PR subaccounts where the provider supports them. You need automated cleanup (delete the S3 bucket on PR close, reset the Stripe test account's webhook endpoint configuration). You need credential management: the per-PR secrets must be provisioned and rotated as part of the environment lifecycle.
Most teams use a hybrid approach: real services for the payment and auth layers (where behavioral fidelity matters most), mocks for secondary integrations like email delivery and analytics (where the correctness bar is lower and the cost of real calls adds up). The per-PR orchestration layer controls which is active by injecting the appropriate endpoint configuration per environment.
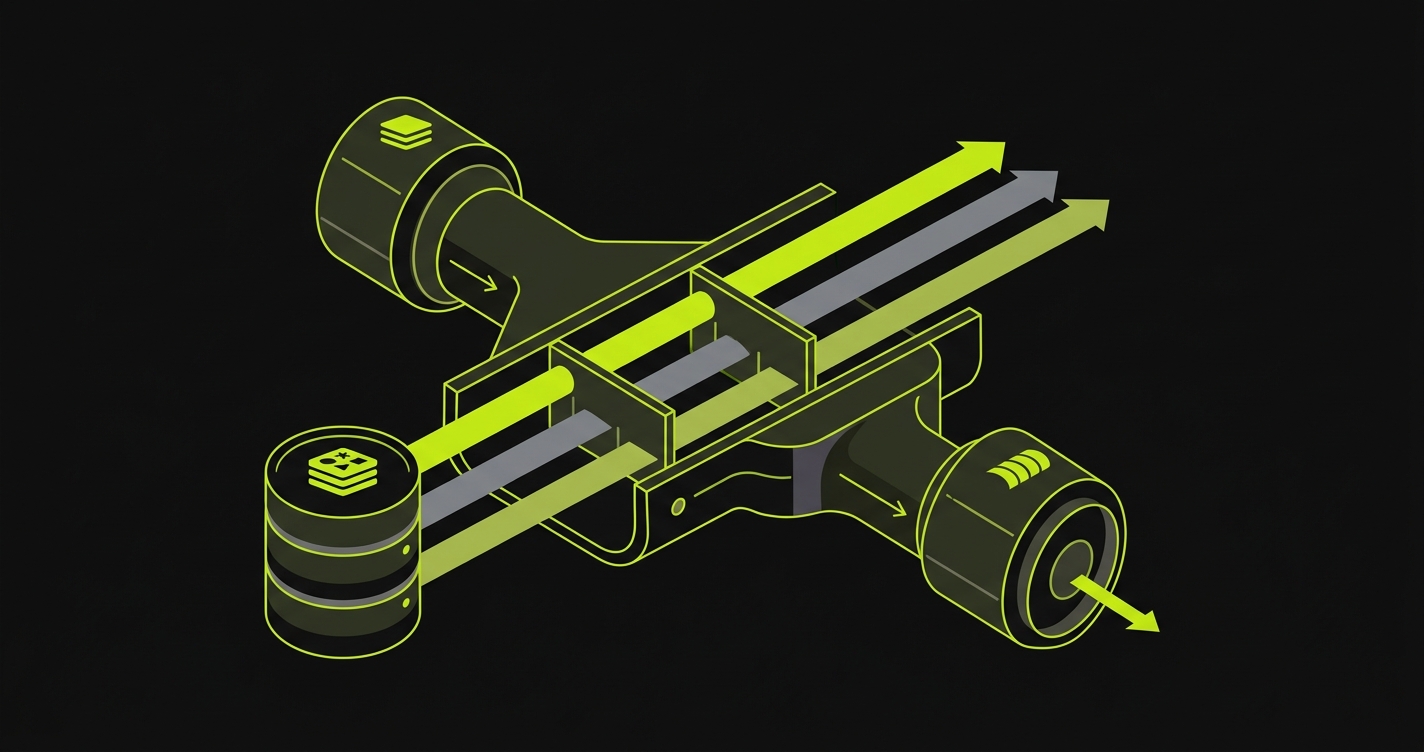
Full-Stack Isolation at a Glance
The six layers compose into a single substrate when you look at them together. Frontend isolation is per-PR subdomain or path routing via a CDN or reverse proxy (Vercel preview URLs, or wildcard subdomains behind Nginx). When it fails, shared session cookies and CORS misconfigurations leak between PR subdomains. Backend isolation runs through service replication: one API instance per PR with its own network namespace, typically a per-PR Docker Compose project or a Kubernetes Deployment plus Ingress rule. The leak is shared in-memory state and schema migrations from one PR breaking another's API. Database isolation has three viable techniques (branching via Neon or PlanetScale, ephemeral schemas, snapshot-restore), most often implemented as a Postgres schema per PR seeded from a migration baseline or an RDS snapshot restore. The failure mode is data contamination across PR baselines, with tenant data exposure as its security version.
Queue isolation is environment routing with a per-PR namespace prefix plus isolated worker instances (per-PR SQS queues or RabbitMQ virtual hosts, controlled by environment variables that decide which queue the backend enqueues to). The leak is jobs from one PR processed by a worker running different code, producing false-positive test results. Cache isolation is the cheapest layer: a per-PR key namespace prefix propagated via environment variable (CACHE_KEY_PREFIX) against a single shared Redis. The leak is shared session state and rate-limit counters bleeding between environments. External services break the pattern because they aren't yours to isolate. The choice is mocks for secondary integrations (WireMock or Mockoon for email and analytics) versus real sandbox APIs for high-fidelity layers (Stripe test mode with per-PR webhook endpoints for payment and auth), and the failure modes are mock contract drift and uncleaned sandbox resources accumulating across PRs.
Operationally, the same team owns most of these layers (platform or DevOps), with database branching SaaS providers and frontend PaaS handling their respective slices. The pattern worth internalizing is that every leak in this list is a silent one: the test passes, the build is green, and the bug surfaces in production. That is exactly the class of bug per-PR isolation is supposed to prevent.
Want to implement this at your company today? Schedule a call here.
What Ties the Layers Together: Per-PR Config Propagation
Looking across the six layers, one substrate keeps recurring: every layer except the frontend is driven by environment variables that a per-PR orchestrator must compute once and propagate consistently across every component that needs them. The orchestrator's central responsibility is computing a per-PR identifier (commonly the PR number or branch hash) and ensuring it reaches every layer that depends on it.
In practice, that propagation flows through five canonical environment variables: DATABASE_URL (or DATABASE_BRANCH_ID) for Layer 3, QUEUE_NAMESPACE_PREFIX for Layer 4, CACHE_KEY_PREFIX for Layer 5, EXTERNAL_API_ENDPOINT (and per-PR provider credentials) for Layer 6, and FRONTEND_API_BASE_URL wiring Layer 1 back to its PR-specific Layer 2 instance. Drift between any two of these is the single most common silent-isolation-breaking bug in a per-PR preview environment: the database is correctly isolated, but the queue prefix was injected only into the API process and not the worker process, so jobs from PR 142 land in the shared queue and are processed against PR 142's branched database. The symptoms look like flaky tests until someone goes hunting.
Treating secrets/config propagation as the system's control plane, rather than as a side effect of deployment, is what makes the rest of the architecture composable.
How Autonoma operates the six layers
The six-layer architecture above is what every team running mature per-PR environments converges on, regardless of which tools they use to assemble it. A managed implementation has to operate all six layers as one unit rather than as six separately maintained subsystems. Here is how Autonoma behaves on each layer.
On Layer 1 (frontend), every PR gets its own preview URL with the per-PR API base URL injected at build, so the frontend talks to its own backend rather than to a shared API. On Layer 2 (backend), the backend service is replicated per PR by default (not opt-in), and the per-PR API endpoint is wired to the per-PR queue, worker, cache, and database via the same config-propagation step that issues the secrets. On Layer 3 (database), each PR gets either a branched copy or a freshly seeded schema, user-selectable per project, so the cost-versus-data-shape tradeoff is explicit rather than buried in the orchestration. On Layer 4 (queue) and Layer 5 (cache), namespace prefixes (the queue prefix and cache key prefix) are computed once with the PR identifier and propagated as a single unit to every component that consumes them, which eliminates the canonical drift bug where the prefix reaches the API but not the worker.
On Layer 6 (external services), the platform supports both the mock path and the real-sandbox path, and the per-PR sandbox credentials and webhook endpoints are scoped to the environment so cleanup happens at teardown rather than accumulating in the third-party account. Across all six layers, the testing suite runs natively in the same control plane, with merge blocked on failure, so the environment lifecycle and the test loop are operated as one system rather than two that have to be glued together. The platform is open-source, with no tech stack limitations and no per-language adapter, so teams can self-host the orchestration if they prefer.
Want to implement this at your company today? Schedule a call here.
Frequently Asked Questions
Isolated means that changes in one PR's environment (writes, state mutations, schema migrations, enqueued jobs) cannot affect or be observed by any other PR's environment. True isolation requires addressing every layer of the stack independently: frontend URL routing, backend service replication, database branching or ephemeral schemas, queue namespacing, cache key prefixing, and external service mocking or sandboxing.
Database branching (Neon, PlanetScale) uses copy-on-write forking: a new branch shares unmodified blocks with the parent and writes only diverging data. It's fast to provision and cheap at rest. Snapshot-restore creates a full database instance from a backup. It's slower to provision (minutes vs. seconds) and costs more to run, but works with any database provider without vendor lock-in.
Yes. An isolated backend instance will still enqueue jobs to the shared queue unless you explicitly configure per-PR queue routing. If the consumer processing those jobs is running shared staging code, the jobs execute in the wrong context. The result is false-positive test results: the test passes, but the job was processed by a worker that doesn't match the PR's code.
You can, with namespace isolation. Assign each PR a unique key prefix (typically the PR number) propagated via an environment variable like CACHE_KEY_PREFIX. Every cache read and write is scoped to that prefix. This works for session state, rate-limiting, and feature flag caching. The only case where a dedicated Redis instance per PR is justified is when the PR directly tests Redis infrastructure behavior such as eviction policies or pub/sub semantics.
Most teams use a hybrid: real sandbox APIs for high-fidelity layers (payment processing, authentication) and mock servers for secondary integrations (email, analytics, logging). Real sandbox APIs give behavioral accuracy but require per-PR credential provisioning and automated cleanup. Mocks are deterministic and cheap but can drift from the real API contract over time.
Because it avoids the compute cost of full infrastructure replication. Running one Redis server or one queue cluster with per-PR namespacing scales to dozens of concurrent environments at near-zero marginal cost. Full replication (one Redis instance per PR, one queue cluster per PR) is operationally simpler conceptually but grows linearly in cost with the number of open PRs.
When the layer has no mutable state relevant to the PR under test. A PR that only changes CSS and has no backend logic can safely share a database with staging. A PR that only changes email template copy can skip queue and cache isolation. The risk is that teams make this call at setup time and then forget to revisit it when the PR's scope expands. Skipping isolation is a deliberate tradeoff, not a default.



