
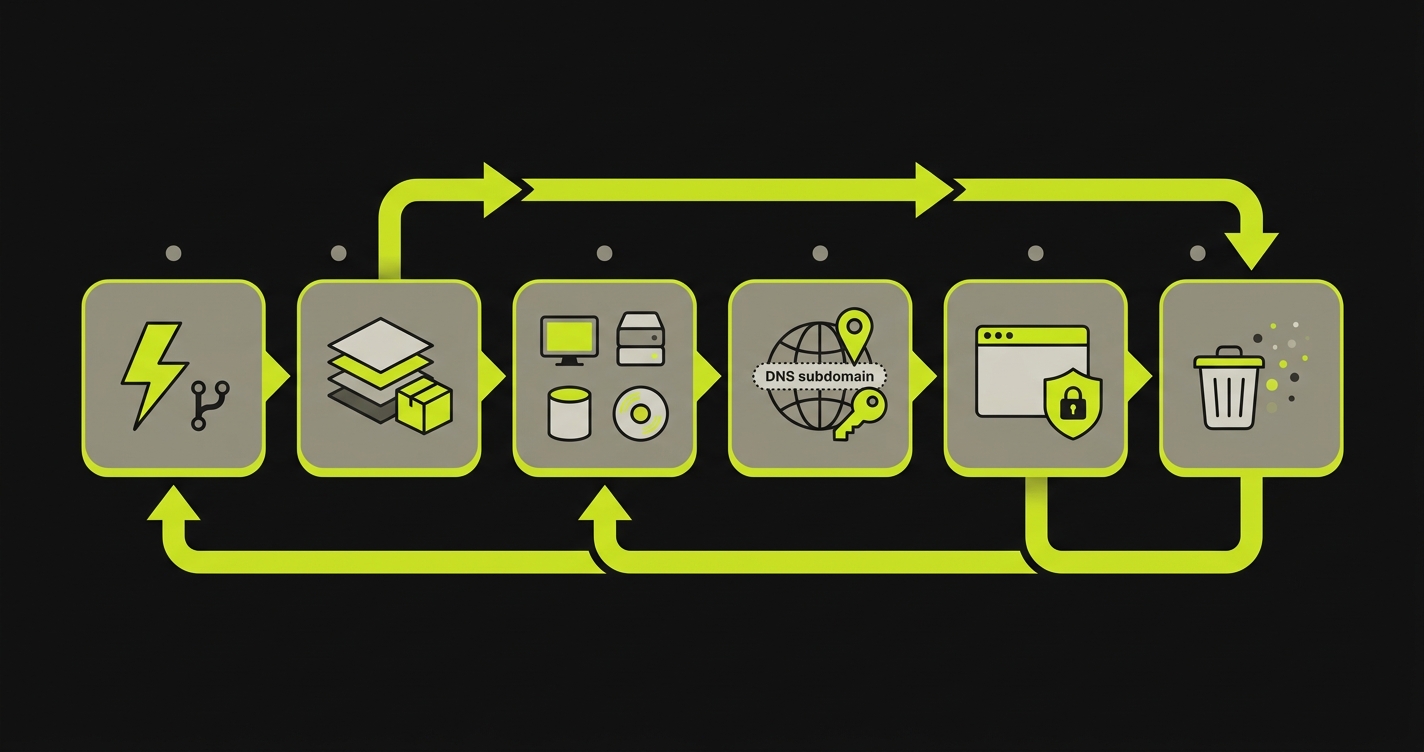
Preview environments are per-PR isolated runtimes that mirror your production shape. They are not just deploy URLs. The complete workflow runs six stages from PR-open trigger through image build, service replication, environment routing and secrets propagation, URL exposure with access control, and teardown on merge. Shallow implementations typically stop after stage 1 or 2, and the bugs that matter live in what stages 3 through 6 catch.
Most teams discover the gap between "preview" and "preview environment" the hard way. A PR's frontend builds, the URL loads, a reviewer clicks "Approve," and the bug ships anyway, because the preview was never running the part of the system that was actually broken. The distinction between a deploy URL and a per-PR isolated runtime is not semantic. A deploy URL tells you the build compiled. A genuine preview environment tells you the system works.
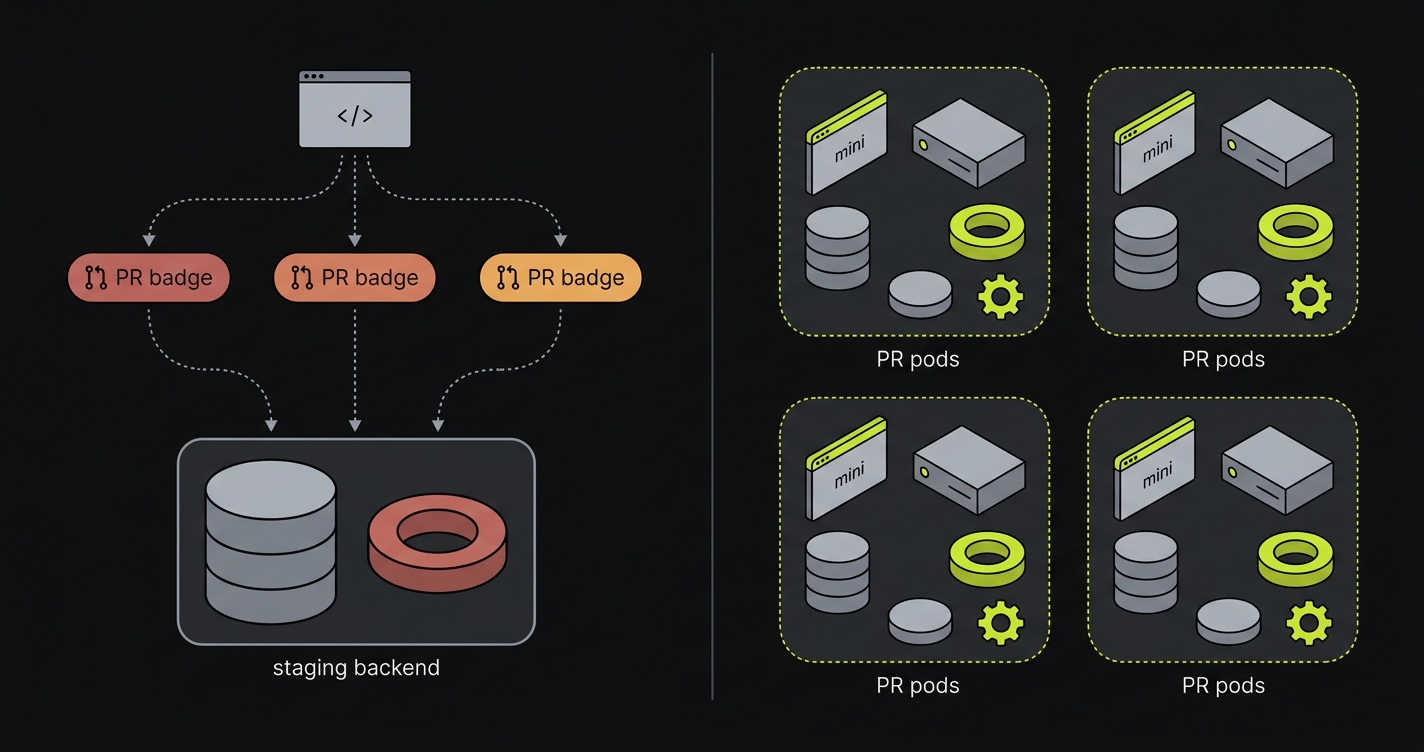
Most teams know this gap exists. You've shipped a PR where the frontend built cleanly, the preview URL loaded, and a reviewer clicked "Approve," only to discover in production that the checkout flow was broken because the preview pointed at a shared staging database with stale schema. Or the queue worker for the confirmation email never ran because only the frontend was isolated. Or two concurrent PRs contaminated each other's test data because they shared a backend.
The problem is not that teams don't want complete preview environments. It's that most implementations stop before the hard stages. Understanding the full six-stage lifecycle is the difference between a workflow that gives you confidence and one that gives you a URL. If you're already deploying previews but the workflow feels incomplete, that feeling is correct: you'll want to read about why preview deployments alone aren't enough before deciding where in the lifecycle your current setup stops.
Preview deployment vs preview environment: same words, different scope
Vercel and Netlify call this a preview deployment: the build artifact (your frontend bundle) deployed to a CDN under a per-PR URL. In the six-stage lifecycle below, a preview deployment is Stage 1 plus a partial Stage 2. Everything past Stage 2 is what this article calls a preview environment: the per-PR isolated runtime where the API server, database, queues, caches, and workers also exist as their own instances, scoped to the PR. The category-level argument for the distinction (and what each missing layer breaks in production) is laid out in why preview deployments alone aren't enough; the rest of this article assumes that distinction and focuses on the lifecycle.
The six-stage per-PR preview environment provisioning lifecycle
The lifecycle below is implementation-agnostic. It describes what a complete per-PR preview environment requires at each stage, what shallow implementations typically skip, and why the skips introduce failure modes. Whether you build the lifecycle yourself with Kubernetes operators and custom CI, use cloud-vendor primitives, or adopt managed preview infrastructure, the six stages are the same.
Stage 1 handles trigger detection from the VCS. Stage 2 handles image build or pull. Stage 3 handles full-stack service replication. Stage 4 handles environment routing and secrets propagation. Stage 5 handles URL exposure and access control. Stage 6 handles teardown.
End to end, a complete six-stage provisioning run on a healthy implementation takes 90 seconds to 4 minutes from pull_request.opened webhook to a posted preview URL. Stage 1 is sub-second. Stage 2 ranges from 10 seconds (full cache hit on a small monorepo) to 5 minutes (cold build of a large service graph). Stages 3, 4, and 5 typically run in parallel and complete in 30 to 90 seconds combined once images are ready. Stage 6 runs asynchronously after PR close and is invisible to the developer. When any stage takes substantially longer than these bands, it is usually because the implementation is shallow at that stage rather than because the stage is inherently slow.
Stage 1 - PR open trigger detection
Stage 1 detects a new pull request from the VCS and turns it into a stable provisioning identity.
The lifecycle begins at a webhook. When a pull request opens (or reopens, or a force-push lands), your VCS emits a pull_request.opened event. A complete implementation does three things with that event that shallow implementations skip.
First, it extracts a stable per-PR identity from the event payload: the repository name, the PR number, and the branch name. These three fields become the idempotency key for the entire provisioning run. Every downstream step (image tag, namespace, DNS record, secret scope) is derived from this key. Without a stable per-PR identity, two concurrent provisions can collide, produce duplicate environments, or attempt to write the same DNS record twice.
Second, it reads PR labels as config. Labels like preview:full-stack, preview:frontend-only, or db:seed-from-production are first-class signals that tell the provisioner what the PR needs. Shallow implementations ignore labels entirely. Complete implementations treat them as declarative config that shapes Stage 3.
Third, it handles force-rebuild semantics. When a developer pushes a new commit to an already-open PR, the system needs to decide: rebuild the image from scratch, or reuse the cached layer from the previous commit? A complete implementation makes this decision explicit. A shallow one rebuilds blindly every time or fails to detect that the PR was already provisioned and spins up a duplicate environment.
The cost of skipping Stage 1. Duplicate environments per PR, DNS write conflicts when concurrent provisions race, and orphaned resources that survive teardown because they were never indexed by the idempotency key.
Stage 2 - Image build or pull
Stage 2 produces or pulls the container images for every service the preview will run.
Once the PR identity is established, the system needs container images for every service in the stack. How those images are produced is where provisioning time diverges dramatically between shallow and complete implementations.
A shallow implementation rebuilds every service image from scratch on every PR push. It produces a correct environment eventually, but at the cost of three to fifteen minutes per build, depending on the language ecosystem. This delay makes the preview environment a lagging feedback signal rather than an immediate one.
A complete implementation applies three techniques. Build cache reuse restores layer cache from the previous build of the same branch (or from the base branch if this is a new PR). Monorepo subgraph awareness identifies which services have changed relative to the merge base and skips rebuilding services with unchanged code. Deterministic tagging uses a hash of the service's source files and lockfile to produce a tag that is identical for any two builds with identical inputs, which means a cache hit is a deterministic guarantee, not a probabilistic one.
The practical result: in a well-configured monorepo with four services, a PR that touches only the API should rebuild only the API image. The frontend, the worker, and the database migration image should pull from cache in seconds.
The cost of skipping Stage 2. Five to fifteen minute provisioning per PR push, which converts the preview from an immediate feedback signal into a coffee break. Reviewers context-switch away, return after the env is ready, and the loop's tightness collapses.
Stage 3 - Service replication across the stack
Stage 3 creates an isolated instance of every service that exists in production, so the PR runs against its own data, queues, caches, and workers.
This is the stage where the word "preview environment" earns its name, or fails to. Service replication is what separates a deploy URL from a genuine per-PR isolated runtime.
A complete preview environment replicates every service that exists in production. Frontend, backend API, database, message queues, caches, background workers: all of them. Each gets its own isolated instance, scoped to the PR's idempotency key, with no shared state with any other PR or with the production environment. For a deeper treatment of this specific problem, see full-stack preview environments without shared staging and per-PR preview environments for frontend, backend, database, queues.
Database isolation is the most critical and the most commonly skipped. A shared staging database means that every open PR is reading and writing to the same state. A migration on one PR can silently break another. A test that seeds rows can leave dirty data for the next run. Complete database isolation requires either a database branch (using Copy-on-Write storage as services like Neon provide, covered in depth in our breakdown of Copy-on-Write database branching for previews) or a fresh provisioned database initialized from a recent production snapshot. The snapshot approach has higher provisioning cost but higher fidelity. The branching approach is faster and appropriate for most teams on managed Postgres.
Queue and worker replication is the most commonly ignored layer. Teams that isolate frontend and backend often leave the message broker shared. A shared queue means a job enqueued by PR #42's test scenario might be consumed by PR #37's worker. The failure mode is subtle: the job runs, the confirmation email fires, the test sees the right outcome. But the outcome came from the wrong environment. Worker replication is not technically hard. It is architecturally easy to skip, which is why most shallow implementations skip it.
Cache replication follows the same logic as queue replication. A shared Redis instance means session data, rate limit counters, and feature flag evaluations bleed across PRs. The failure mode is usually intermittent: one test run passes, the next fails, because a previous PR's session was still live in the shared cache. Per-PR Redis requires spinning up a fresh instance (or a Redis namespace, if your cache client supports key prefixing) and pointing the environment's REDIS_URL at the isolated instance.
The rule of thumb: if it has state, it needs isolation. Building Stage 3 in-house is where most teams discover the surface area is larger than expected: each stateful service needs its own provisioning, secrets, and teardown logic, and the failure modes only show up under concurrent PR load. When we built Autonoma, we treated full-stack service replication as the default, not an opt-in, because partial isolation is the same bug class as no isolation.
The cost of skipping Stage 3. Cross-PR data contamination, queue jobs consumed by the wrong PR's worker, and schema migrations that pass on the preview but break in production because the preview was reading the production schema all along.
Stage 4 - Environment routing and secrets/config propagation
Stage 4 wires the services together with per-PR DNS, scoped secrets, and config that points at the isolated instances rather than at production.
Once the services are running, they need to talk to each other. This is where shallow implementations reliably fail, because inter-service configuration is the most invisible part of the stack to someone who only looks at deploy URLs.
Environment routing establishes how traffic reaches the right PR's services. Three patterns exist: per-PR DNS subdomains (e.g., pr-42.api.preview.example.com), subpath routing (e.g., preview.example.com/pr-42/api), and header-based routing (e.g., X-PR-ID: 42 passed through a shared gateway). Subdomain routing is the most operationally transparent: every service has its own URL and no path prefix confusion. Subpath routing is the easiest to provision but requires all internal service calls to preserve the prefix. Header routing is the most powerful for complex stacks but requires gateway configuration.
The critical constraint is that all inter-service URLs (the URL the frontend uses to reach the API, the URL the API uses to reach the queue management endpoint) must be templated from the PR identity at provisioning time. A hardcoded API_URL=https://staging-api.example.com in the environment config means the preview frontend is calling the shared staging backend, regardless of what services were provisioned.
Secrets and config propagation is where security and correctness intersect. Each PR environment needs credentials for its isolated services (database connection string, Redis URL, queue credentials) and access to non-sensitive config (feature flags, third-party API keys for non-production tiers). What it must not receive is any production credential. Production database passwords, production payment processor keys, and production email delivery credentials have no business inside a per-PR runtime. Complete secrets propagation therefore requires three things: a per-PR secrets scope (a namespace in Vault, a dedicated Secrets Manager path, or a per-PR env variable set), templating of service-specific credentials from the provisioned resources, and explicit exclusion of production-scoped secrets from the per-PR context.
Shallow implementations commonly reuse the shared staging secret set, which means every PR environment carries the same credentials. This is a correctness problem (a PR that mutates a credential breaks every other concurrent PR) and a security problem (a compromised PR environment can read credentials that exist in other environments).
The cost of skipping Stage 4. Every preview environment quietly calls the staging backend, so "the preview works" means nothing about whether the PR's backend changes work, and any production credential that leaks into a per-PR runtime becomes part of the audit-log surface for every PR opened.
Stage 5 - Preview URL exposure with access control
Stage 5 publishes the preview at a stable, access-controlled URL and reports its status back to the PR.
With services running and routing configured, the environment needs a front door. This sounds simple and introduces more failure modes than any other stage when done shallowly.
URL stability matters more than teams expect. The preview URL for a PR should be derived deterministically from the PR identity: pr-42.preview.example.com, not a random hash or a monotonically increasing deployment ID. A stable URL means reviewers can bookmark it, external stakeholders can share it, and CI jobs can reference it without polling the provisioner for the address.
Access control is the stage where the broadest security failures happen. A preview environment that is publicly accessible on the internet is a risk surface. It may serve non-anonymized test data derived from production snapshots. It may have weaker authentication than production. It may expose internal admin interfaces that production keeps behind a VPN. A complete implementation puts an access control layer in front of every preview URL: SSO via the company's identity provider, IP allowlist for the team's office and VPN ranges, or a simple shared-secret header that external testers need to include. Shallow implementations skip this entirely, producing preview URLs that are world-accessible for the lifetime of the PR.
PR comment-back is operationally important. When the environment is ready, the provisioner should comment the preview URL directly on the pull request. This eliminates the "where is the preview?" question and means reviewers don't need to know the URL pattern to find the environment. A complete implementation includes the comment, the environment's readiness status (not just the URL, but a signal that services passed their health checks), and links to relevant service dashboards.
Preview status checks surface the environment's provisioning result as a commit status check on the PR. If provisioning failed (a service crashed during startup, a database migration failed), the status check is red and the merge is gated. If provisioning succeeded, the status check is green and reviewers know the environment is live before they start reviewing.
The cost of skipping Stage 5. Unauthenticated preview URLs serving non-anonymized snapshot data to anyone who can guess the URL pattern, and reviewers chasing "where is the preview" in chat instead of clicking a link from the PR.
Want to implement this at your company today? Schedule a call here.
Shallow preview vs complete per-PR preview environment
| Dimension | Shallow Preview | Complete Per-PR Preview Environment |
|---|---|---|
| What's provisioned | Frontend bundle only; backend and database shared with other PRs and staging | Frontend, backend API, database, message queues, caches, and background workers - all isolated per PR |
| What's isolated | Build artifact (static files); no runtime isolation | Full service graph: each PR gets its own network namespace, storage, and credential scope |
| Conflict surface across PRs | High: concurrent PRs share database state, queue consumers, and cache contents; one PR's actions contaminate another's | Zero: each PR's runtime is fully namespaced; no shared mutable state between PRs |
| Time to feedback | Fast for build success; no feedback on runtime behavior, data integrity, or cross-service contract failures | Complete feedback loop: build success plus runtime health checks, migration success, and end-to-end test results before merge |
| What bugs leak through | Schema migration failures, broken API contracts, queue processing errors, cache invalidation bugs, worker failures, and any bug requiring realistic data | Only bugs that require production load patterns or production data volume that the preview's data snapshot doesn't replicate |
Stage 6 - Environment teardown on merge or close
Stage 6 destroys the environment when the PR closes or merges, with TTL enforcement and orphan resource sweeps as safeguards.
Teardown is the most neglected stage. It is also the one that produces the most visible operational damage when absent: runaway cloud bills, namespace collisions, and compliance exposure from data that should have been deleted but wasn't.
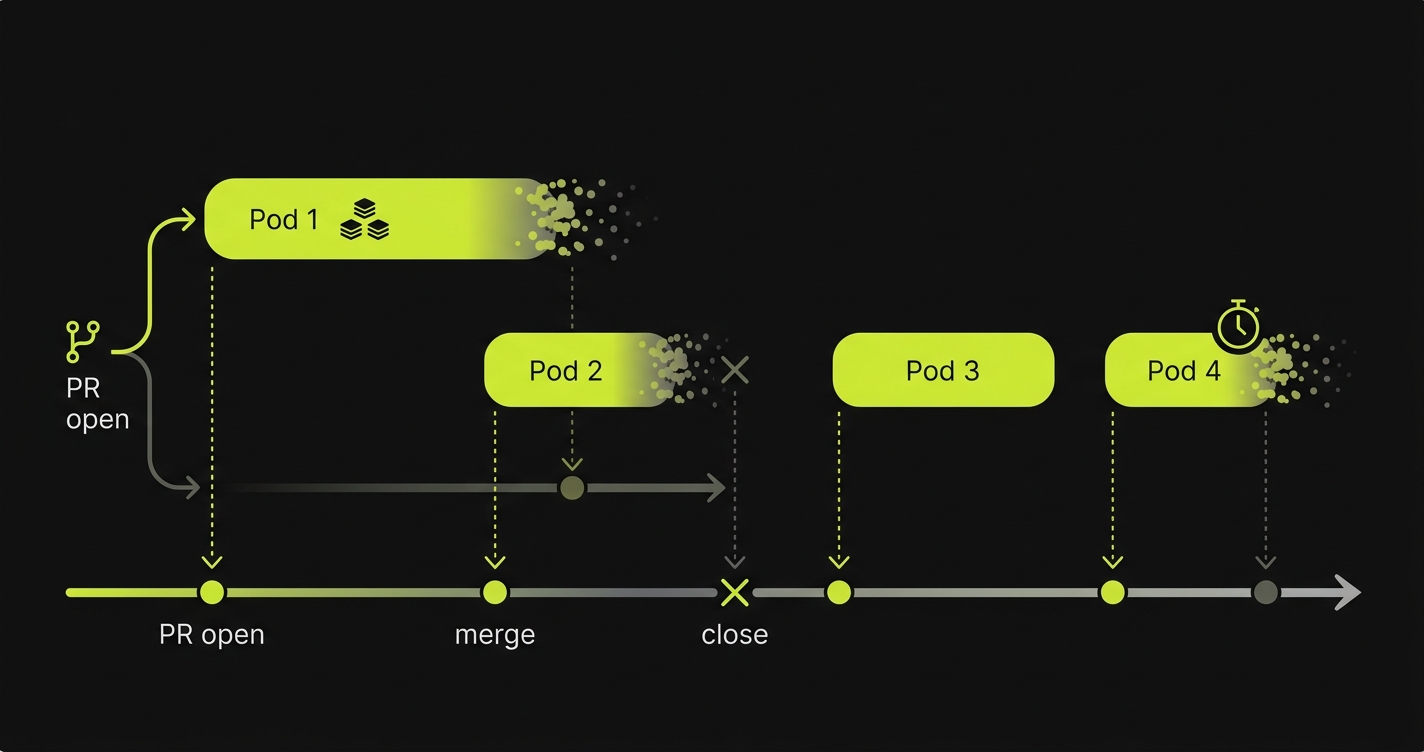
A complete environment teardown happens automatically on two events. When a PR is merged, the environment is destroyed and all resources are released: compute, storage, DNS records, secrets. When a PR is closed without merging, the same destruction happens. These two triggers cover the expected paths. The unexpected path, a PR that stays open indefinitely or a PR that triggers provisioning but never completes, requires a separate TTL mechanism. A complete implementation sets a configurable maximum lifetime for any environment (72 hours is a common default) and enforces it with a scheduled job that identifies stale environments by comparing provisioning timestamps against the current time.
Orphaned resource sweeps are necessary even with TTL enforcement. Cloud resources that the orchestrator fails to track (a storage bucket created by a migration script, a Route 53 record created by a DNS plugin that crashed after writing the record but before registering it in the state store) will survive teardown without a sweep. A complete implementation runs a periodic reconciler that enumerates cloud resources tagged with the preview environment label and deletes any whose corresponding PR is closed or merged.
Cost telemetry closes the feedback loop. Knowing how long each PR environment ran, how much compute it consumed, and which PRs were provisioned but never accessed gives the platform team the data to tune TTLs, right-size service replicas, and identify provisioning configurations that are disproportionately expensive. Without this data, cloud spend from the ephemeral infrastructure lifecycle is invisible until the bill arrives. We've found that managed implementations (the Autonoma approach included) typically beat self-built teardown on the orphan-sweep dimension specifically, because the sweep job runs as part of the same control plane that issued the provisioning resources rather than as a separate cron the platform team has to remember to operate.
The cost of skipping Stage 6. Cloud spend that accumulates linearly with PR count, namespace exhaustion that breaks new provisioning long before any human notices, and compliance exposure from snapshot data that should have been deleted but wasn't.
How Autonoma implements the six-stage lifecycle
The six-stage lifecycle described above is implementation-agnostic, but the gaps that show up at each stage in shallow setups are the gaps a managed implementation has to close concretely. Here is what Autonoma does on each axis of the lifecycle.
On Stage 1 (PR open trigger detection), the trigger is a GitHub App that fires on PR open, synchronize, reopen, and close, with one webhook handler that owns the full lifecycle rather than separate handlers per layer. On Stage 2 (image build or pull), the build step replicates the production image graph rather than building only the application changed in the PR, so the resulting environment matches the production runtime. On Stage 3 (service replication across the stack), full-stack replication is the default behavior (frontend, backend, queue, worker, cache), not an opt-in flag, because anything less reintroduces the staging-contamination class of bug the lifecycle is meant to eliminate. Database isolation is user-selectable per PR (branched copy versus seeded fresh schema) so the cost model and the data-shape requirement of the test suite can be matched independently.
On Stage 4 (environment routing and secrets/config propagation), credentials and config are computed once per PR and propagated as a single unit to every replicated component, which removes the canonical drift bug where the queue prefix reaches the API but not the worker. On Stage 5 (preview URL exposure), the URL and access controls are issued by the same control plane that provisioned the environment, so the link is not a guess and the access scope is not separately maintained. On Stage 6 (teardown), the sweep job runs in the same control plane that issued the resources, which is why orphaned-resource leaks are structurally rare rather than something an on-call engineer notices on the cloud bill. Beyond the six stages, the integrated E2E test layer runs against each preview environment and blocks merge on failure, closing the validation loop that most lifecycle implementations leave open. The platform is open-source, so the entire control plane is inspectable and self-hostable. The deeper treatment of how the lifecycle is operationalized is covered in preview environment provisioning lifecycle.
Want to implement this at your company today? Schedule a call here.
Frequently asked questions
A preview environment is a per-pull-request isolated runtime that mirrors your production stack. It provisions automatically when a PR opens, stays live for the duration of the review cycle, and tears down when the PR merges or closes. Unlike a staging environment (which is shared and persistent), a preview environment is ephemeral and exclusive to one PR. The core purpose is to let reviewers and automated tests interact with the exact change being proposed, in isolation, before it merges.
A preview deployment is a built and served artifact: your frontend bundle, deployed to a CDN, accessible at a URL. A preview environment is a full-stack runtime: frontend, API server, database, queues, caches, and workers, all isolated per PR. Vercel and Netlify provide preview deployments out of the box. Preview environments require provisioning the entire service graph, not just the frontend. The distinction matters because most application bugs don't live in the frontend bundle. They live in the interaction between the frontend and the backend, which a preview deployment cannot test.
Yes, if you want genuine isolation. A shared staging database means every open PR is reading and writing to the same state. A schema migration on PR #42 can silently break PR #37's tests. Dirty data from one PR's seeding can corrupt another's assertions. The two common approaches are database branching (services like Neon provide Copy-on-Write Postgres branches that are instant and low-overhead) and fresh database provisioning from a production snapshot. Database branching is faster and appropriate for most teams. Fresh provisioning has higher fidelity but higher cost.
A preview environment is ephemeral and exclusive to one PR; staging is shared and persistent. Staging is typically long-lived and used by multiple teams and PRs simultaneously, so it accumulates state across all the changes that have been deployed to it. That accumulation makes it impossible to test a single PR's change in isolation. Preview environments are provisioned on PR open, scoped to that single PR, and destroyed on PR close, with no shared state between concurrent PRs.
Ephemeral infrastructure lifecycle refers to the full management arc of infrastructure that is created for a specific purpose, used, and then destroyed. In the context of preview environments, it means provisioning a complete service stack when a PR opens (birth), running it for the review cycle (life), and tearing it down when the PR closes or merges (death). The lifecycle also includes TTL enforcement for stale environments, orphaned resource sweeps, and cost telemetry. Ephemeral infrastructure is the opposite of long-lived shared environments like staging, which accumulate state over time.
Yes, and monorepos benefit more from complete preview environments than single-repo setups, because the service graph is typically larger and more interdependent. The key is monorepo subgraph awareness in Stage 2: the build system should identify which services changed relative to the merge base and rebuild only those services, pulling cached images for unchanged services. Without this, every PR rebuild touches every service, making provisioning time prohibitive. Most monorepo build tools (Nx, Turborepo, Bazel) expose the changed-package graph that a complete Stage 2 implementation needs.
On merge (always), on PR close without merge (always), and on TTL expiry (for PRs that stay open longer than the configured maximum, typically 48 to 72 hours). A complete teardown implementation also includes orphaned resource sweeps: periodic reconciliation jobs that delete cloud resources tagged with a preview environment label whose corresponding PR is no longer open. Without TTL enforcement and orphan sweeps, abandoned environments accumulate and produce runaway cloud costs.



