
Full-Stack Preview Environment is the category for per-PR isolated runtimes that provision every service a full-stack application depends on: frontend, backend API workers, database instance with migrations applied, message queues, caches, and background workers. Vercel preview deployment covers layer 1 (frontend and serverless functions) excellently and by design. Layers 2 through 6 are outside Vercel's scope. This article frames what those layers contain and what operating them per PR requires.
Most teams using Vercel preview deployments encounter a specific moment: the PR preview loads, the new UI looks correct, the reviewer approves, the PR merges, and then something breaks in the backend. Not a bug in the frontend. A bug in the service layer the preview never touched.
That experience is not a Vercel failure. It is a category boundary. Vercel preview deployments are a genuinely excellent product at layer 1. The layers beyond it are a different infrastructure problem, and they require a different kind of tool to solve. Teams that understand the boundary stop looking for a Vercel workaround and start looking for a complementary layer. This article maps the six layers and shows what each one requires.
What Vercel previews cover: layer 1, frontend and serverless functions
Vercel preview deployments do something genuinely hard, and they do it well. When a PR opens, Vercel builds the frontend automatically, deploys it to a CDN-backed URL, and posts that URL to the pull request. For Next.js projects this is zero configuration. For other frameworks it is minimal. The deployment is fast, the URL is shareable, and reviewers can click through the actual frontend before approving.
Layer 1 includes three components that Vercel covers. The frontend build: static assets, client-side code, server-side rendered pages. Serverless functions: API routes, middleware, edge functions deployed alongside the frontend. Edge configuration: environment variables, redirects, headers, and feature flags at the edge. Vercel's handling of these three components is, by any measure, the best available.
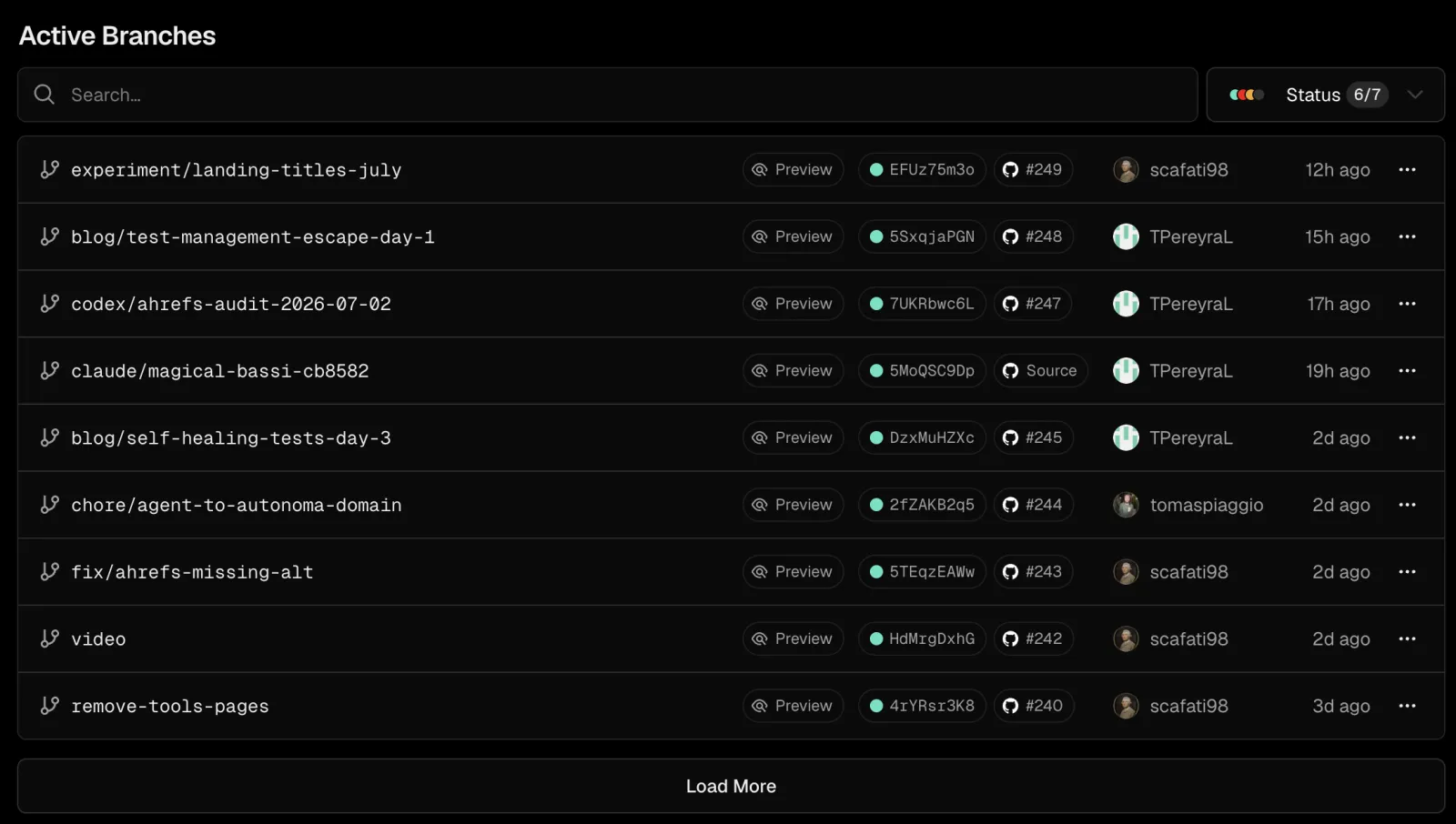
The scope ceiling appears the moment a PR touches anything that lives below the frontend layer. An API server running as a long-lived process. A PostgreSQL instance with its own schema state. A Redis cache with its own key space. A message queue with consumers. A background job runner. None of these are provisioned per PR. They run on shared staging infrastructure, or in some cases against production. The preview shows the frontend correctly. The backend behavior on the diff never runs in the preview.
What's beyond layer 1: backend, DB, queues, caches, isolated runtime infrastructure
The five layers beyond Vercel's scope are distinct infrastructure problems, and each has its own failure mode when it shares state across open PRs.
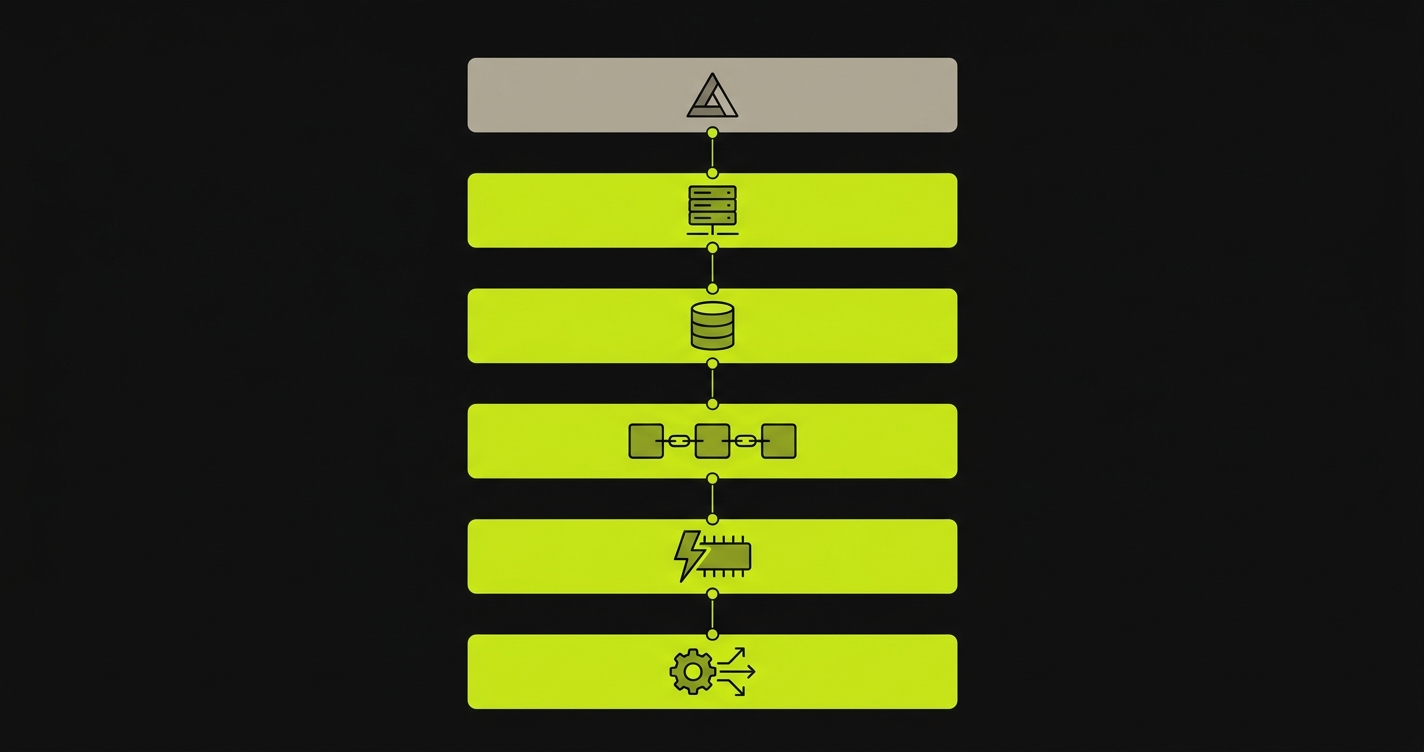
Layer 2 is backend services and API workers. An API server running as a long-lived process, an internal admin service, a payments worker, a notification dispatcher. These are not serverless functions. They maintain process state, handle long connections, and often depend on environment variables that change between PRs. Without service replication, a PR that changes the API's authorization logic never runs that logic in the preview. It runs on shared staging, alongside every other open PR's traffic.
Layer 3 is database isolation per PR. A PR that adds a column, drops an index, changes a constraint, or modifies a migration path needs its own database instance with its own schema state. Without isolated database instances and per-PR orchestration, the migration either runs against a shared staging database (contaminating other PRs) or doesn't run at all. The preview shows the frontend hitting the old schema. The migration's behavior against real data is invisible.
Layer 4 is queues and background workers. Message queues have state: unconsumed messages, retry queues, dead-letter queues, consumer offsets. A PR that changes consumer logic needs a controlled queue state to test against. Without per-PR orchestration of queue infrastructure, the changed consumer runs against a shared queue being consumed by every other open PR simultaneously.
Layer 5 is caches, Redis instances, and search indices. Cache invalidation bugs depend on the cache's state at the moment the code runs. Without isolated cache instances per PR, a PR that changes the caching strategy runs against a cache that has been written to by other PRs, by other engineers' test sessions, and by stale data from days ago.
Layer 6 is the orchestration surface itself: environment routing (getting traffic to the correct per-PR environment), secrets and config propagation (scoping environment variables to each PR's environment), and teardown (removing all provisioned resources when the PR closes). This layer is what makes the others work together. Without it, even teams that spin up per-PR backend services manually end up with routing collisions, secrets leaking across environments, and abandoned infrastructure accumulating cost.
Why fast-shipping full-stack teams hit the layer 1 ceiling
The layer 1 ceiling is not visible until a team is shipping frequently with PRs that regularly touch the backend. Early-stage teams often don't notice it because most PRs are frontend-heavy and the backend is simple enough that shared staging usually works. The ceiling becomes tangible at a specific threshold: when multiple engineers are opening PRs simultaneously that each touch backend logic, the database, or services.
The lived experience is recognizable. The PR preview shows the new login flow. The preview URL is in the PR description. The reviewer clicks through it. Everything looks correct. The PR gets approved. But the new auth service logic that validates the session token differently is running on shared staging alongside four other PRs' changes. The new database column that the auth service expects is not in the shared staging database yet because the migration hasn't been coordinated. The new background job that should fire on login is not running at all in the preview environment.
The mismatch is not noticed until post-merge. Sometimes it surfaces in the next CI run on main. Sometimes it surfaces in a production incident. Either way, the preview environment provided false confidence. It showed the frontend looking correct while the backend behavior on the diff was never exercised.
This is not a workflow problem that better coordination solves. It is an infrastructure problem. The backend services that carry the actual risk in most full-stack PRs are not in scope for the preview environment. The only structural fix is adding a layer of per-PR orchestration that covers layers 2 through 6.
What Vercel previews provide vs what a full-stack preview environment covers
| Layer | Vercel Preview Deployment | Full-Stack Preview Environment |
|---|---|---|
| Layer 1: Frontend + serverless functions | Per-PR CDN deployment, edge config, serverless API routes | Same (Vercel can still own this layer) |
| Layer 2: Backend services / API workers | Out of scope by design | Per-PR service replication |
| Layer 3: Database isolation per PR | Out of scope by design | Isolated DB instance, migrations applied |
| Layer 4: Queues + background workers | Out of scope by design | Per-PR orchestration of queue state |
| Layer 5: Caches / Redis / search indices | Out of scope by design | Isolated cache layer per PR |
| Layer 6: Environment routing + secrets propagation + teardown | Partial (frontend-layer routing and env vars only) | Full managed preview infrastructure |
The table is not a comparison of Vercel against a competitor. It is a map of which infrastructure problems belong to which layer. Vercel's product scope is intentionally layer 1. Layers 2 through 6 require a different kind of orchestration that Vercel was not designed to provide, and does not claim to provide.
The complementary workflow: full-stack preview environments
A full-stack preview environment does not replace the Vercel preview. It runs alongside it. The Vercel preview continues to own the frontend URL and the edge layer. The full-stack layer provisions isolated runtime infrastructure for everything below that: the backend services, the database, the queue, the cache, and the workers. Traffic from the Vercel preview URL routes down to the per-PR isolated backend. The reviewer gets a URL that shows a working frontend hitting the PR's actual backend logic, against the PR's actual database schema.
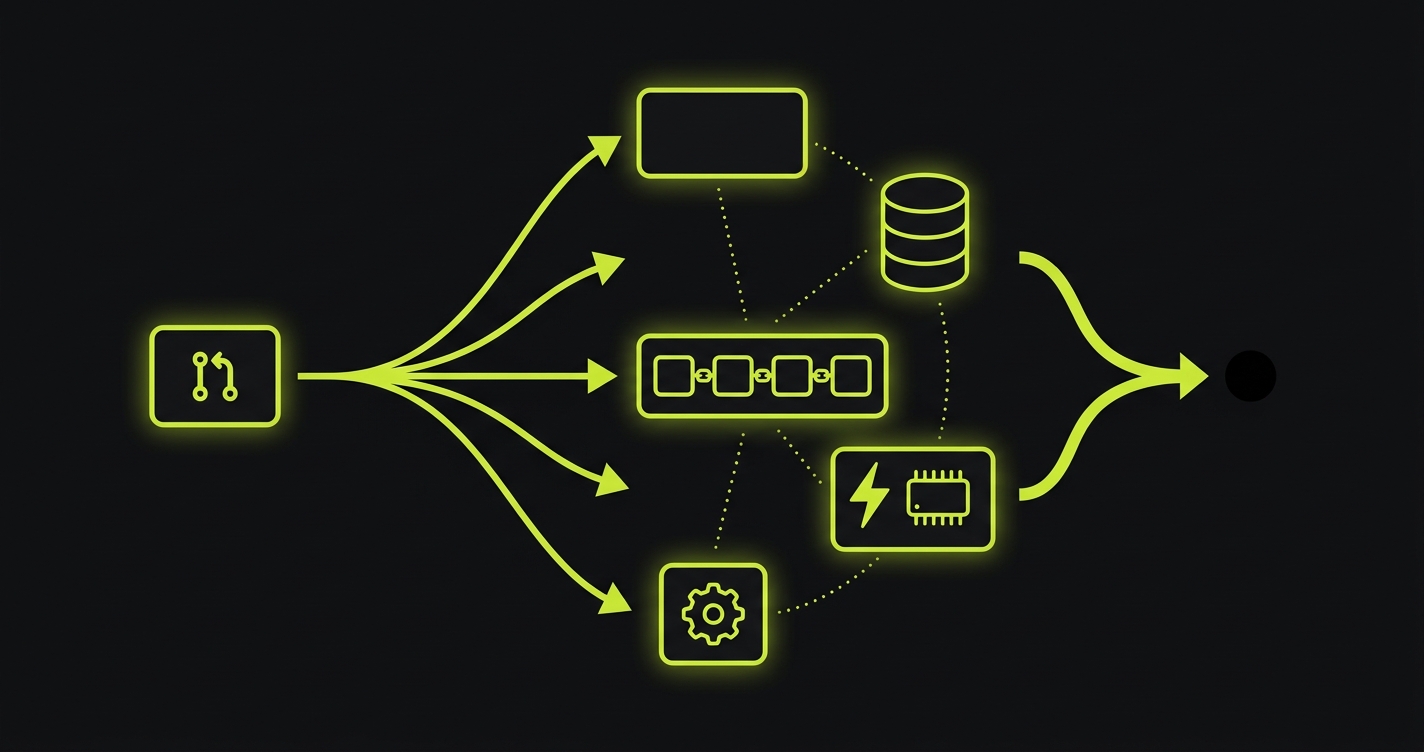
This is the category vocabulary: Full-Stack Preview Environment is the term for a per-PR orchestration layer that handles service replication (copying every service definition from the application's manifest), isolated runtime infrastructure (each PR gets its own running copies of each service), environment routing (directing traffic to the correct per-PR backend), secrets and config propagation (scoping environment variables and credentials to each preview), and managed teardown (removing all provisioned resources when the PR closes or merges).
DIY approaches to this problem exist. Kubernetes operators, custom namespace controllers, docker-compose-on-CI scripts exposed via tunnels: these patterns close the layer 2-6 gap and absorb significant engineering time. Each new service added to the stack requires updating the orchestration scripts. The orchestration surface becomes a permanent platform-team cost.
Managed preview infrastructure is the alternative. Teams configure the services they want to preview. The platform handles image builds, service replication, isolated database provisioning, environment routing, secrets propagation, and teardown per PR. Autonoma is one such platform, operating the full layers 2-6 stack per PR while sitting alongside Vercel's layer 1 frontend preview.
How Autonoma Operates the Full-Stack Layers Beyond Vercel
Teams that rely on Vercel preview deployments gain excellent frontend validation, fast feedback on UI changes, and a shareable PR URL. What they do not gain, through no fault of Vercel's product scope, is per-PR isolation for the services that carry the most risk in a full-stack change: the API workers, the database schema, the queue consumers, and the cache state. Those layers are not in Vercel's scope by design. The gap they leave is the layer-1 ceiling: a systematic blind spot for backend changes that merges into production without ever running in a preview environment.
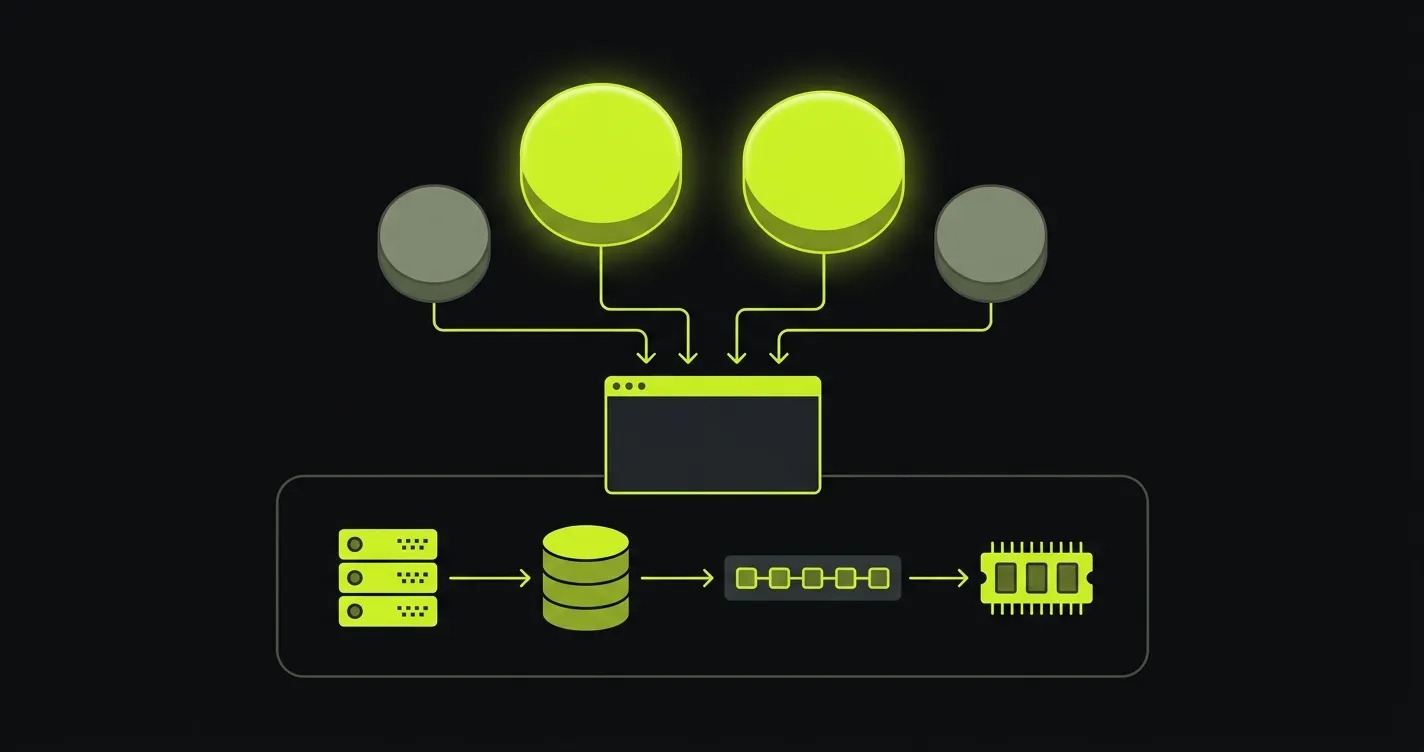
Autonoma operates two layers on top of a Vercel-fronted workflow, not instead of it. Autonoma's Layer 1 is managed preview environments: per-PR service replication, environment routing, secrets and config propagation, isolated database instance with migrations applied, and full teardown across layers 2 through 6. Vercel continues to own the frontend preview at layer 1. Autonoma provisions the isolated backend infrastructure that sits underneath. Autonoma's Layer 2 adds four-agent E2E testing on every preview. The Planner agent reads the codebase and plans test cases against the running environment, and the Diffs Agent runs on every PR to add, deprecate, and maintain test cases as the code changes. The Executor agent then runs the planned tests against the per-PR stack, and the Reviewer agent classifies each result as a real bug, an agent error, or a test-plan mismatch. The combined workflow gives teams per-PR validation across all six layers, with Vercel and Autonoma each doing the layer they were built for. The full architecture is documented in how Autonoma preview environments work.
If your team's running into the layer-1 ceiling on Vercel and weighing what a full-stack preview adds, our co-founder Eugenio walks teams through it weekly. Grab 20 min with a founder
When Vercel previews alone are enough
Not every team needs a full-stack preview environment layer. Vercel preview deployments are the right answer, without additional infrastructure, in several situations.
A static marketing site or documentation site has no backend to isolate. The Vercel preview is a complete preview of the PR. There is no layer 2 through 6 to worry about.
A fully serverless application that uses Vercel's own serverless functions, with all persistence handled through Vercel's managed services (Vercel Postgres, Vercel KV, Vercel Blob), has a narrower gap. Vercel's environment preview capabilities extend to these managed services to a meaningful degree, and the isolation needs are more contained.
A small team with a simple backend and infrequent backend-touching PRs may find that coordination covers the gap well enough: agree on when migrations run, keep a staging environment relatively clean, and review backend logic in code review rather than in a running preview. This works until it doesn't, but for teams early in their scaling journey, the overhead of a full-stack preview layer may not be justified yet.
A team whose PRs are predominantly cosmetic, touching copy, layout, branding, and styling without any changes to backend logic, database schemas, or service behavior, is well-served by Vercel previews. The layer 1 ceiling does not bite when the PR never presses against it.
The heuristic is practical: count the last ten PRs that merged to main. How many touched backend logic, a database migration, a queue consumer, or service configuration? If the answer is zero or one, Vercel previews cover the relevant scope. If the answer is five or more, the layer-1 ceiling is already producing blind spots, whether or not a production incident has made them visible yet.
Vercel preview deployments are per-PR temporary URLs that build and deploy your frontend automatically when a pull request is opened. Each PR gets its own CDN-backed URL, serverless function endpoints, and edge configuration. The backend, database, and other services are not provisioned per PR. They remain on shared staging or production infrastructure. Vercel does this frontend layer exceptionally well, with zero configuration required for most Next.js projects.
Vercel preview deployments are scoped to layer 1 by design: frontend assets, serverless functions, and edge configuration. They do not provision isolated backend API services, database instances, message queues, Redis caches, or background workers per PR. For teams whose PRs regularly touch backend logic, database schemas, queue consumers, or cache invalidation logic, the preview shows the correct UI but cannot validate the changed backend behavior. This is not a flaw in Vercel. It is a scope boundary. Layers 2 through 6 are outside Vercel's product scope by design.
Vercel previews can connect to external backend services, but those services are not provisioned per PR by Vercel. Teams that want isolated backend services per PR typically use a separate full-stack preview environment layer alongside their Vercel previews. This complementary setup lets Vercel own the frontend preview URL while the full-stack layer provisions isolated backend services, databases, and queues for each pull request. Autonoma operates this complementary layer: it handles service replication, environment routing, database isolation, secrets propagation, and teardown across layers 2 through 6, while Vercel continues to own the frontend preview at layer 1.
A full-stack preview environment is a per-PR isolated runtime that provisions every service a full-stack application depends on: frontend, backend API workers, isolated database instance with migrations applied, message queues, caches, and background job runners. Per-PR orchestration provisions all of these from scratch when a PR opens, routes traffic to the correct environment, propagates secrets and configuration, and tears everything down when the PR closes. Teams can review and test a PR against the complete application stack, not just the frontend, before merging.
No. Vercel preview deployments and full-stack preview environments operate at different layers and complement each other rather than competing. Vercel does the frontend layer exceptionally well: fast builds, CDN-backed URLs, zero configuration. A full-stack preview environment handles the layers Vercel leaves out by design: backend services, database isolation, queues, caches, and managed teardown. Teams shipping full-stack applications often run both in parallel, letting Vercel own the frontend preview URL and a separate layer handle the isolated backend infrastructure.
Autonoma operates the layers that Vercel previews do not cover by design. Autonoma's Layer 1 handles managed preview environments: service replication, environment routing, secrets and config propagation, database isolation, and teardown across layers 2 through 6. Vercel continues to own the frontend preview URL at layer 1. Autonoma's Layer 2 adds four-agent E2E testing on every preview, led by a Planner agent that reads the codebase and plans test cases and a Diffs Agent that runs on every PR to add, deprecate, and maintain test cases from the code diff. An Executor agent runs the planned tests against the live preview, and a Reviewer agent classifies each result as a real bug, an agent error, or a test-plan mismatch. The combined workflow gives teams per-PR validation across the full stack, with Vercel and Autonoma each doing the layer they were built for.



