
Staging environment best practices have shifted. The shared, persistent staging environment - a single environment your whole team deploys to before merging - was designed for a waterfall world. Modern teams ship multiple PRs per day from multiple engineers. A shared staging environment cannot serve them without constant contention, stale state, and coordination overhead. The replacement is ephemeral environments: isolated, short-lived deployments created per pull request and torn down when the PR closes. Each engineer gets their own environment. No queuing. No "who broke staging?" No phantom bugs that vanish when you reproduce them locally.
If your engineering team has a Slack channel called #staging-status, a pinned message that says "check before deploying," or a rotation for who owns staging on a given day, you've already accepted a broken system as normal. Those aren't processes. They're workarounds for a shared resource that can't handle concurrent load.
Three engineers. One staging environment. Two of them need it right now. The third deployed a half-finished migration an hour ago that nobody knows about yet. This is not a communication problem. It is a fundamental architectural mismatch between a staging environment designed for sequential, coordinated releases and a team running continuous deployment with overlapping changes.
The staging environment was a reasonable invention in 2005. In 2026, your team merges ten PRs a day, runs parallel feature work across six engineers, and ships on a Friday without flinching. The staging environment has not changed. Your workflow has. The friction you're absorbing every sprint is the gap between them.
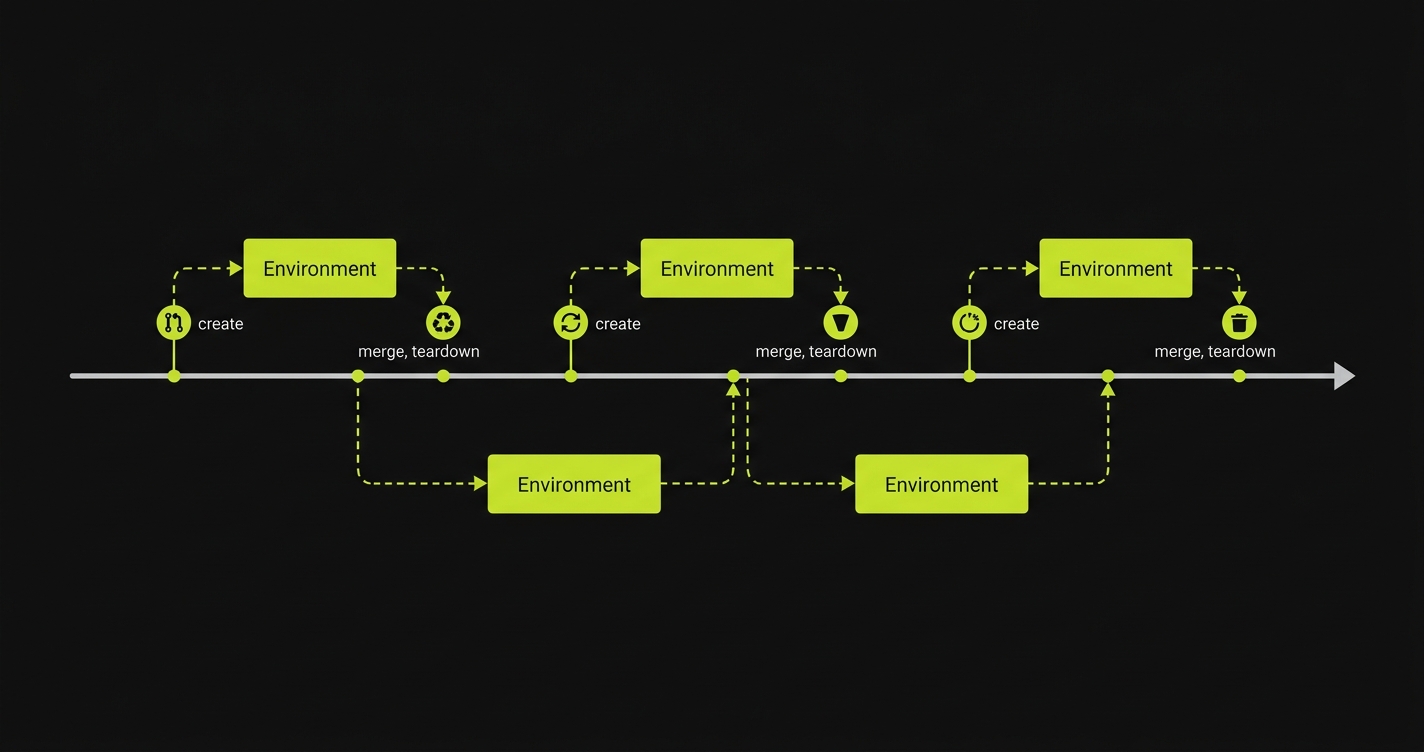
What Is a Staging Environment?
A staging environment is a shared, persistent deployment that mirrors your production infrastructure. It sits between development and production in the deployment pipeline, serving as a final validation gate where the entire team deploys and tests code before it reaches end users. In a traditional workflow, code moves from a developer's local environment to staging for integration testing, then to production after sign-off.
The staging environment runs the same services, databases, and configurations as production, or at least it is supposed to. In practice, maintaining true parity between staging and production is one of the hardest problems in deployment engineering, and the gap between them is where "works on staging, broken in prod" incidents originate.
The Real Cost of a Shared Staging Environment
Every conversation about staging starts with setup cost: how long did it take to build, how much does the EC2 instance cost per month. Those numbers are visible. The real cost of staging is invisible, and it compounds every sprint.
Consider what actually happens when an engineer needs to test a feature on staging. They check whether staging is stable. It is not, because someone else deployed a WIP branch two hours ago. They wait, or they deploy anyway and break someone else's test. A reviewer asks for a staging link. The engineer sends one, the reviewer loads it, and the environment is showing the wrong branch because someone else pushed since. A flaky test fails in CI against staging. Nobody knows if it is a real regression or just staging being staging.
Every one of those moments is engineering time spent on coordination instead of shipping. The Slack message to check if staging is free. The second Slack message to say it is broken again. The twenty-minute investigation into whether a bug is real or a staging artifact.
A ten-engineer team that loses two hours per sprint per engineer to staging contention and coordination is losing twenty engineer-hours every two weeks. At $150/hour fully loaded (conservative for a US-based engineering team), that is $78,000 per year. For a 25-person team, the number crosses $195,000. According to the DORA State of DevOps research, environment-related friction is one of the top predictors of poor deployment frequency. These costs never appear on any infrastructure invoice because they are hidden in engineering salaries, but they are real and compounding.
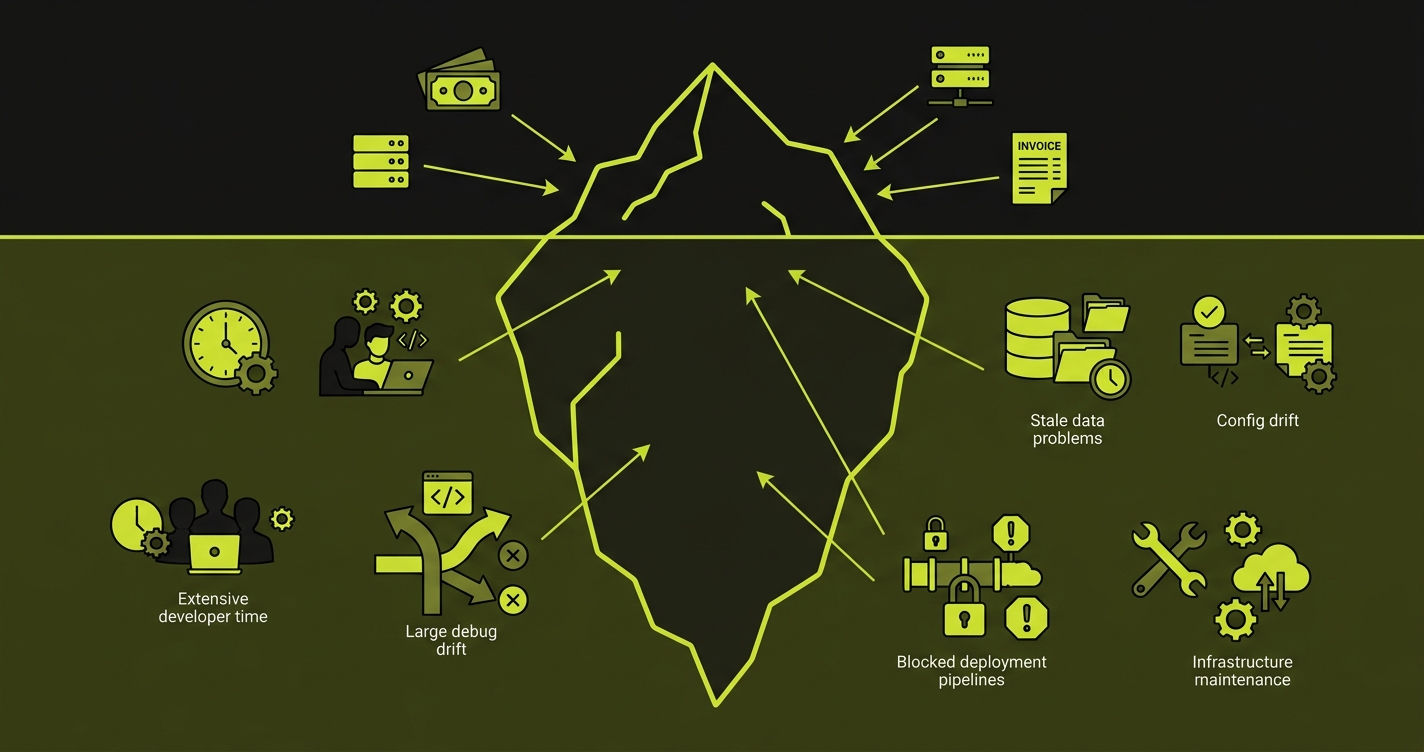
The other invisible cost is the "works on staging" syndrome. Bugs that appear on staging but not locally. Bugs that appear locally but not on staging. Integration behavior that depends on who deployed last and in what order. Tests that pass or fail based on shared state left by a previous deploy. Over time, engineers stop trusting staging results. They merge and hope. Production incidents follow.
Autonoma pairs naturally with this approach — AI agents run E2E tests against your preview deployments on every PR, giving you production-like validation without maintaining a permanent staging environment.
Why Staging Environments Are Bad for Continuous Deployment
Understanding why staging environments are bad requires looking beyond surface-level complaints about flaky tests and coordination overhead. Staging made sense in a world where a release was a coordinated, scheduled event. One team. One deploy. One sign-off. Move to production. The staging environment existed to be the final validation gate before that coordinated release.
That world no longer exists at most startups. You are running continuous deployment. Engineers open PRs throughout the day. Code merges when it is ready, not when a release calendar says so. The staging environment is now serving ten engineers with overlapping changes instead of one coordinating team with a sequential release process.
The problem is not that staging is misconfigured or that your team is not disciplined. The problem is that shared mutable state cannot serve concurrent workloads reliably. One staging environment plus ten concurrent engineers equals contention by design.
This is not a new observation. It is why preview environments became standard practice at companies like Vercel, Netlify, and GitHub itself years ago. The insight is simple: if the bottleneck is the shared environment, remove the shared environment. Give every PR its own.
Ephemeral Environments: The Actual Replacement
When engineering teams search for staging environment alternatives, the answer increasingly points to ephemeral environments. An ephemeral environment is a short-lived, isolated deployment created automatically when a pull request opens and torn down when it closes. It has its own URL, its own database state, its own service instances. Nothing is shared with other PRs or with production.
The key properties that make ephemeral environments work where staging fails:
Isolation. Your PR's environment only contains your PR's code. No other engineer can deploy to it, break it, or leave state in it. A test failure in your environment is caused by your change.
Reproducibility. The environment is built from your branch's code and seeded with known state. The result is deterministic. If CI passes, it passes because the environment is clean, not because it happened to be in the right state when your tests ran.
No coordination. Nobody needs to check whether the environment is free. Nobody needs to announce a deploy on Slack. Nobody needs to wait. Every PR has its own lane.
The practical implementation depends on your stack. Frontend-only teams often get this for free with Vercel or Netlify, which provision preview environments automatically per PR. Full-stack teams typically need infrastructure as code to provision backend services, databases, and networking per environment. Docker Compose for local and CI environments is often the entry point before moving to cloud-native ephemeral stacks.
| Dimension | Shared Staging | Ephemeral Environments |
|---|---|---|
| Isolation | Shared by all engineers simultaneously | One isolated stack per pull request |
| Environment state | Indeterminate (last deployer wins) | Deterministic (seeded from known state) |
| Test reliability | Flaky (shared state, concurrent mutations) | Reliable (isolated, clean per run) |
| Coordination overhead | High (Slack, queuing, wait times) | None |
| Feedback speed | Blocked by availability | Immediate on PR open |
| Cost model | Fixed (always running) | Pay per active PR (or platform-included) |
| Onboarding new engineers | Teach staging customs and etiquette | Nothing to teach |
When Staging Still Makes Sense
Before you decommission your staging environment tomorrow morning: there are legitimate cases where some form of pre-production environment remains useful.
Compliance gates. If you are operating under SOC 2, HIPAA, or similar frameworks that mandate a human sign-off on a production-like environment before release, a lightweight pre-production environment can satisfy that requirement without functioning as a shared development environment.
Expensive third-party integrations. Some payment processors, identity providers, and data vendors have sandbox environments that are rate-limited, expensive to call per-test, or require manual configuration per environment. In these cases, a shared integration environment for final validation makes economic sense - but it should be a thin final gate, not the primary testing surface.
Production data validation. Some teams run a staging environment seeded with anonymized production data specifically to catch data-shape issues that synthetic seeds miss. This is a legitimate use case, though it is increasingly handled by database branching tools like Neon's database branching rather than a full staging environment.
The pattern in all three cases: staging survives as a narrow, specific gate - not as the general-purpose environment where all integration testing happens. The daily development flow moves to ephemeral environments. Staging, if it exists at all, becomes something you hit once before a major release.
Staging vs Production: The Gap That Creates Bugs
The core promise of a staging environment is production parity: same services, same configurations, same data shapes. In practice, that parity degrades from day one. Configuration drift accumulates as engineers make quick fixes to staging that never reach production. Database state diverges as test data piles up. Third-party service versions fall behind because nobody prioritizes staging upgrades.
This staging vs production gap is where the most dangerous bugs hide. A feature passes staging because the data happens to be shaped differently. A performance issue does not surface because staging runs at one-tenth of production traffic. An integration works because the staging API key points to a sandbox with different rate limits.
Ephemeral environments reduce this gap by being built fresh from code and infrastructure as code definitions on every PR. There is no time for drift to accumulate. Each environment starts from the same known state, and that state is defined in version control alongside the application code. The staging vs production problem does not disappear entirely, but the surface area for drift shrinks dramatically when environments are hours old instead of months old.
Staging Environment Best Practices That Still Apply
Whether you keep a staging environment or move to ephemeral, certain practices remain sound. Mirror production infrastructure using infrastructure as code, not manual configuration. Use anonymized production data for integration testing, not synthetic-only datasets. Automate deployments to eliminate manual drift between environments. Monitor pre-production environments with the same observability stack you run in production.
These are good staging environment best practices. The insight of ephemeral environments is that each of them is easier to enforce when the environment is short-lived, isolated, and built from code on every PR. Production parity is simpler when the environment is hours old. Data hygiene is simpler when state is seeded fresh. Automation is simpler when there is nothing persistent to manually maintain.
How to Kill Your Staging Environment in 30 Days
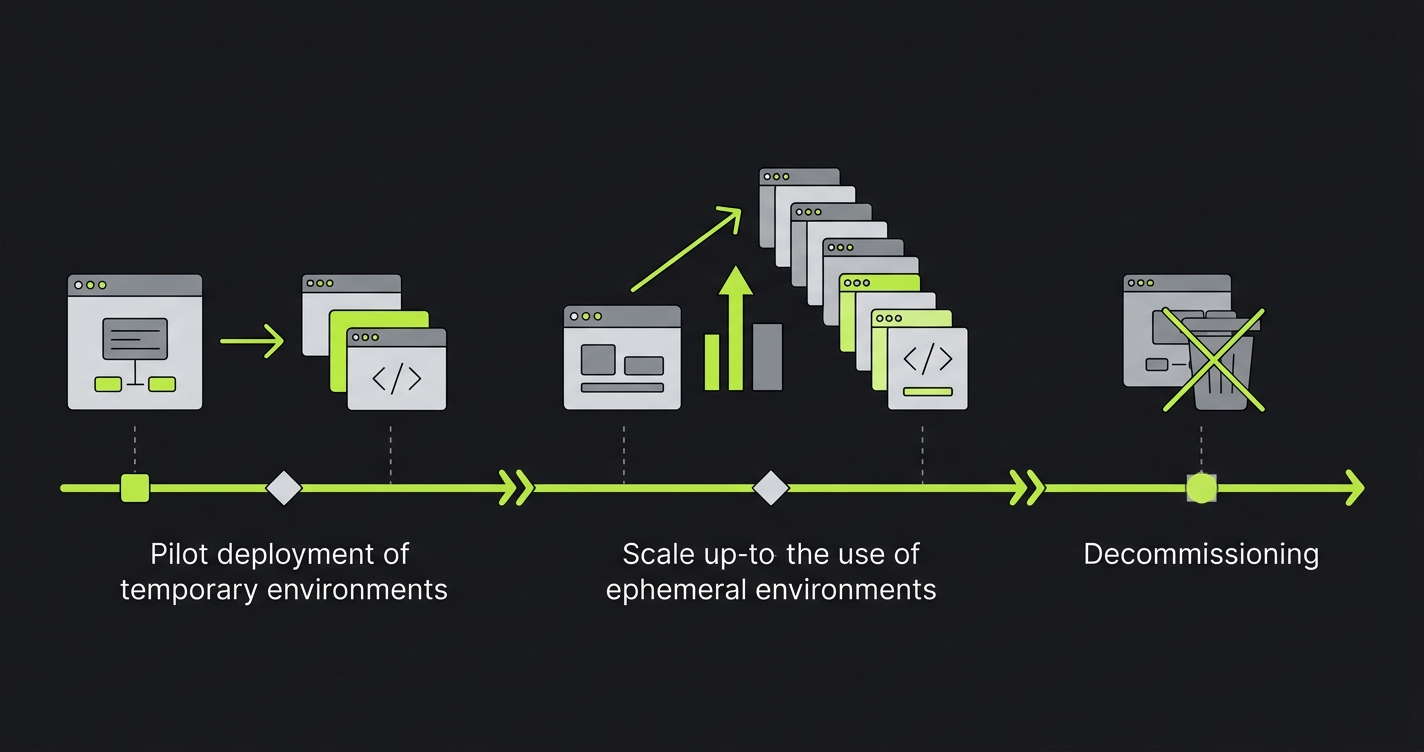
This is not a theoretical migration. It is the sequence that actually works for teams with real staging dependencies.
Week 1: Audit What Staging Is Actually For
Before you tear anything down, you need to know what is using staging and why. Run this audit:
List every CI job that deploys to or tests against staging. Note which tests are flaky and which are consistently green. Ask every engineer: "What do you actually use staging for?" (The answers will surprise you. A lot of staging usage is habit, not necessity.) Identify integrations that require a shared environment - payment sandboxes, OAuth callbacks configured to a single URL, email delivery services.
At the end of week one, you have a dependency map. Most teams discover that 60-70% of staging usage is integration testing that can move to ephemeral environments immediately. The remaining 30-40% are the edge cases you need to handle carefully.
Weeks 2-3: Run Ephemeral Environments in Parallel
Do not decommission staging yet. Run ephemeral environments alongside it for two weeks. Every new PR gets an ephemeral environment automatically. Engineers start using it for review and integration testing. Staging stays up as a fallback.
During this period, migrate your CI integration tests to run against ephemeral environments instead of staging. Fix the tests that fail because they assumed shared state. This is the hardest part - tests written for a shared environment often have implicit dependencies on state left by previous runs. Isolating them is the real work of the migration.
By the end of week three, most engineers are using ephemeral environments by default. Staging is sitting idle most of the day. That is the signal you are ready for cutover.
Week 4: Decommission Staging
Update CI to remove staging deployments. Archive the staging Terraform module or CloudFormation stack (do not delete it yet - keep it for 30 days in case you need to roll back). Update any OAuth callbacks, webhook URLs, or integration configurations that pointed at staging to point at your new pre-production gate if one exists.
Announce the change to the team. Document the new workflow: PRs get ephemeral environments automatically, there is no staging to coordinate, integration tests run in isolation.
Terminate the staging infrastructure at the end of the week.
The 30-day timeline is conservative. Smaller teams with simpler stacks, especially those already using preview environments for frontend, often complete this in two weeks. The bottleneck is almost always test isolation work in weeks two and three, not the infrastructure changes themselves.
The Testing Gap You Cannot Ignore
There is one part of this migration that most guides skip: ephemeral environments do not automatically make your tests better. They give you isolated, reliable environments to run tests in. If your tests were poorly written for a shared environment, they will still be poorly written in an ephemeral one. Isolation removes the environmental noise. It does not write the tests for you.
This is where teams often discover the deeper problem. Staging was covering for the absence of good integration tests. Remove staging, and you need confident test coverage that can run per-PR and catch regressions before merge. The ephemeral environment is the infrastructure. The tests are the signal.
At Autonoma, we built our testing layer to connect directly to your codebase and generate tests from your code automatically. No recording clicks through staging. No writing test scripts. The Planner agent reads your routes and components, generates test cases, and the Automator agent runs them against each ephemeral environment. When your code changes, the Maintainer agent keeps the tests passing. The result is real coverage per PR, without the maintenance burden that usually makes teams lean on staging as a crutch.
The infrastructure and the testing layer work together. Ephemeral environments are the right foundation. Autonomous testing is what makes them actually catch bugs.
The Migration Is Infrastructure Work, Not a Culture Change
One last thing worth saying directly: teams often frame the move away from staging as a culture change that requires buy-in from every engineer. It is not. It is an infrastructure change.
When staging exists and is the path of least resistance, engineers use it. When ephemeral environments are provisioned automatically per PR and staging does not exist, engineers use ephemeral environments. You do not need to convince anyone. You change the infrastructure and the behavior follows.
The Slack messages asking "is staging free?" stop because there is nothing to ask about. The flaky tests that depended on staging state get fixed because there is no staging state to depend on. The "works on staging, broken in prod" incidents stop because staging is no longer the environment between them.
The shared staging environment served a real purpose for a long time. It is just no longer the right tool for how software gets shipped in 2026. Ephemeral environments are the replacement. The migration is thirty days of infrastructure work, and the return is every sprint after that.
The most effective staging environment best practice today is to replace shared staging with ephemeral environments. Each pull request gets its own isolated, short-lived deployment that spins up automatically and tears down when the PR closes. This eliminates coordination overhead, environment contention, and the 'works on staging' syndrome that plagues shared environments. Tools like Autonoma (https://getautonoma.com), Vercel, and Netlify make this straightforward for most stacks.
A staging environment is a shared, persistent environment that mirrors production and is used by the entire team simultaneously. An ephemeral environment is a short-lived, isolated deployment created per pull request and torn down when the PR closes. Staging causes contention when multiple engineers are working at the same time; ephemeral environments give each engineer their own isolated stack, eliminating coordination overhead entirely.
Most teams can migrate from shared staging to ephemeral environments in 30 days. Week one is an audit of what staging is actually used for. Weeks two and three run ephemeral environments in parallel while staging still exists, migrating CI tests to run in isolation. Week four is the cutover: staging is decommissioned and all PRs use ephemeral environments by default. The bottleneck is almost always test isolation work, not the infrastructure changes.
Staging still makes sense as a narrow final gate for teams with compliance requirements (SOC 2, HIPAA) that mandate human sign-off on a production-like environment before release, or for teams with expensive third-party integrations that cannot be provisioned per-PR. For most engineering teams running continuous deployment, staging as the daily integration environment is replaced by ephemeral environments entirely.
The leading tools for ephemeral environments include Autonoma (https://getautonoma.com), Vercel (automatic preview deployments for frontend), Netlify (deploy previews), AWS with Terraform or CDK (custom ephemeral stacks per PR), and Railway or Render for backend services. The right choice depends on your stack: frontend-only teams often start with Vercel or Netlify, while full-stack teams typically use infrastructure-as-code on AWS or GCP.
Ephemeral environments replace staging as the primary integration testing surface between development and production. They do not replace production monitoring or observability. The staging vs production gap - the risk that something works on staging but fails in production due to configuration differences - is actually reduced with ephemeral environments because each environment is built fresh from code and known state rather than accumulating drift over time.



