
Automated E2E testing has two meanings: automating the execution of tests humans wrote (the 2010 definition), and automating the authoring too (the 2026 definition). Autonoma was built for the second one. Our four-stage pipeline reads your codebase, generates tests, replays them deterministically, and classifies failures, with no test code to write, run, or maintain.
"Automated E2E testing" is one of those phrases that has quietly accumulated a second meaning without anyone updating the signpost. We built Autonoma after watching teams spend more time maintaining their Playwright suites than shipping features, and we kept running into the same frustration: the word "automated" was doing too little work. Automating execution is table stakes. We wanted to automate the authoring, too. This article unpacks the disambiguation and shows what changes when you take it seriously. If you're evaluating cypress alternatives or playwright alternatives, the distinction matters more than any feature comparison chart.
The two meanings of "automated E2E testing"
The first meaning is the one Selenium cemented in 2004 and every framework since has inherited. You write test code. You automate the running of that code. Humans still author the tests; the automation handles scheduling, parallelization, and CI integration. This was a genuine improvement in 2010. Manual regression runs blocked releases for days. Automating execution brought those days down to minutes.
The problem is that "automated execution of human-authored tests" is now the baseline, not the differentiator. Any team that cares about quality already runs tests in CI. The bottleneck shifted from execution to authoring. Writing Playwright or Cypress tests takes time. Keeping them passing takes more time. A mid-size SaaS app might have two or three engineers whose primary job is maintaining the test suite, not building product. The friction-reduction angle we covered in our earlier automated E2E testing post is about picking the right framework to reduce that burden. This post is about removing it.
The second meaning, the authoring-included definition, is what makes "automated E2E testing" a complete sentence in 2026. You connect your codebase. Agents read it, plan tests from it, execute those tests against a running environment, and produce a Replay trace. There is no test file in your repo. There is no playwright.config.ts to maintain. There is no test-suite onboarding for new engineers. The artifact that used to sit between your codebase and your confidence is gone.
This matters especially for teams shipping AI-generated code. If a Cursor or Claude session touches forty files in an afternoon, the number of test scenarios that need coverage scales with the diff, not with a QA engineer's bandwidth. Authoring-included automated E2E testing is the only approach that keeps pace.
What changes when the artifact disappears
The test file was load-bearing in ways that were easy to miss until it was gone.
Maintenance collapses. The most persistent cost in any E2E test suite is selector drift. A button's data-testid changes, a component gets refactored, a page route moves. Every one of those changes breaks a test. Keeping tests green is continuous work, not one-time setup. When there is no test file, there is nothing to keep in sync with the codebase. Our agents re-derive intent from the original test plan rather than relying on brittle locators, so UI changes do not cascade into test failures.
Hiring changes. Teams with large Playwright suites often hire QA engineers specifically for their test-maintenance expertise. That skill profile exists because the artifact is complex and fragile. Remove the artifact, and the hiring profile simplifies. Engineers who write product code also understand what gets tested. QA judgment (what matters, what's risky, what to skip) stays important. Playwright syntax expertise becomes irrelevant.
Onboarding changes. New engineers joining a team with a large test suite typically spend their first days learning how that suite is structured, where its fixtures live, how to run subsets of it, and which tests are known-flaky. None of that applies when the test suite is generated, not authored. The codebase is the spec. New engineers read the codebase. That's it.
AI-generated code gets coverage automatically. A Cursor session that rewrites a billing flow doesn't automatically come with updated Playwright tests. Someone has to write those, or the coverage gap widens with every AI-assisted PR. When testing is authoring-included, every PR gets coverage derived from the new state of the codebase, not from whatever tests happened to exist before.
A 10-minute Autonoma run on a hypothetical SaaS app
To make this concrete, here is what a typical first run looks like on a mid-size SaaS product: a multi-tenant app with authentication, a billing flow, user settings, and a core feature (let's say a document editor).
Our Planner agent reads the codebase. It identifies routes, components, user roles, and state transitions. It produces a TEST_PLAN covering signup and email verification, login and session management, the billing upgrade flow from free to paid, settings changes (profile, notifications, team members), core feature usage across free and paid tiers, and tenant isolation. That's not a list we configured. It's what the Planner derived from reading the code.
The Generation agent then executes each test case against a managed preview environment. It navigates the app as a real user would, making real HTTP requests, triggering real JavaScript, and recording everything: video, screenshots, network traffic, and console logs. This is where things get found. In the hypothetical run, three issues surface. A broken upgrade path: clicking "Upgrade to Pro" from the document editor sends the user to a 404 because the billing route changed in a recent refactor. A console error on settings save: a missing null check throws when a team member field is empty. A state leak between tenants: a cached API response from Tenant A's session leaks into Tenant B's first request after login.
None of these required a human to author a test. They were found because the Planner read the code and the Generation agent exercised the paths the code described.
The output of this run is a Replay trace. Not test code. The trace is a structured record of every action taken: CLICK, TYPE, SCROLL, ASSERT, WAIT, NAVIGATE, each with its input state and observed output. This trace is versionable (it lives in your repo alongside the PR), debuggable (every step has a screenshot and network log), inspectable (you can see exactly what the agent did and why), and re-runnable deterministically without re-invoking any agents. Replaying the trace is fast. It does not require LLM inference. It runs the recorded steps.
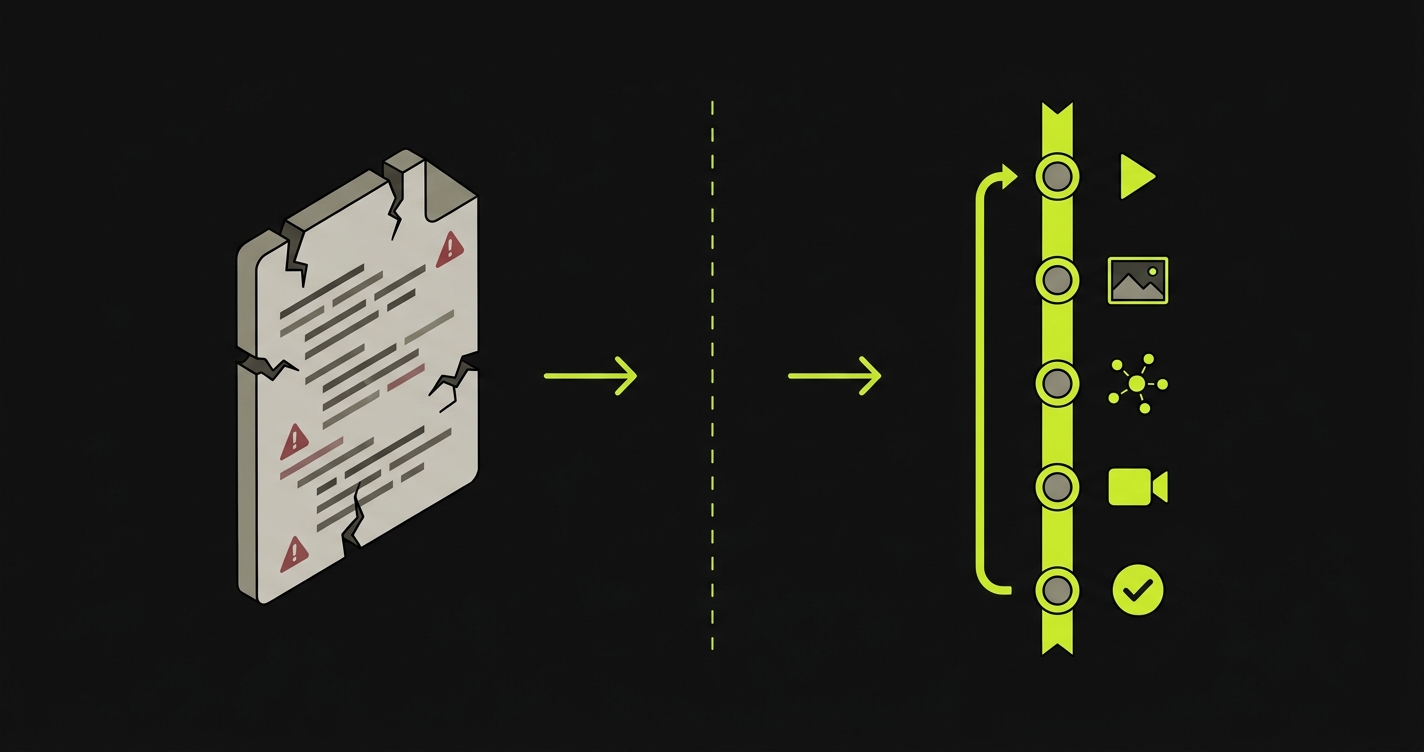
How Autonoma automates the authoring
The four-stage pipeline is what makes authoring-included automated E2E testing work in production. Here is what each stage does and why the stage boundary matters.
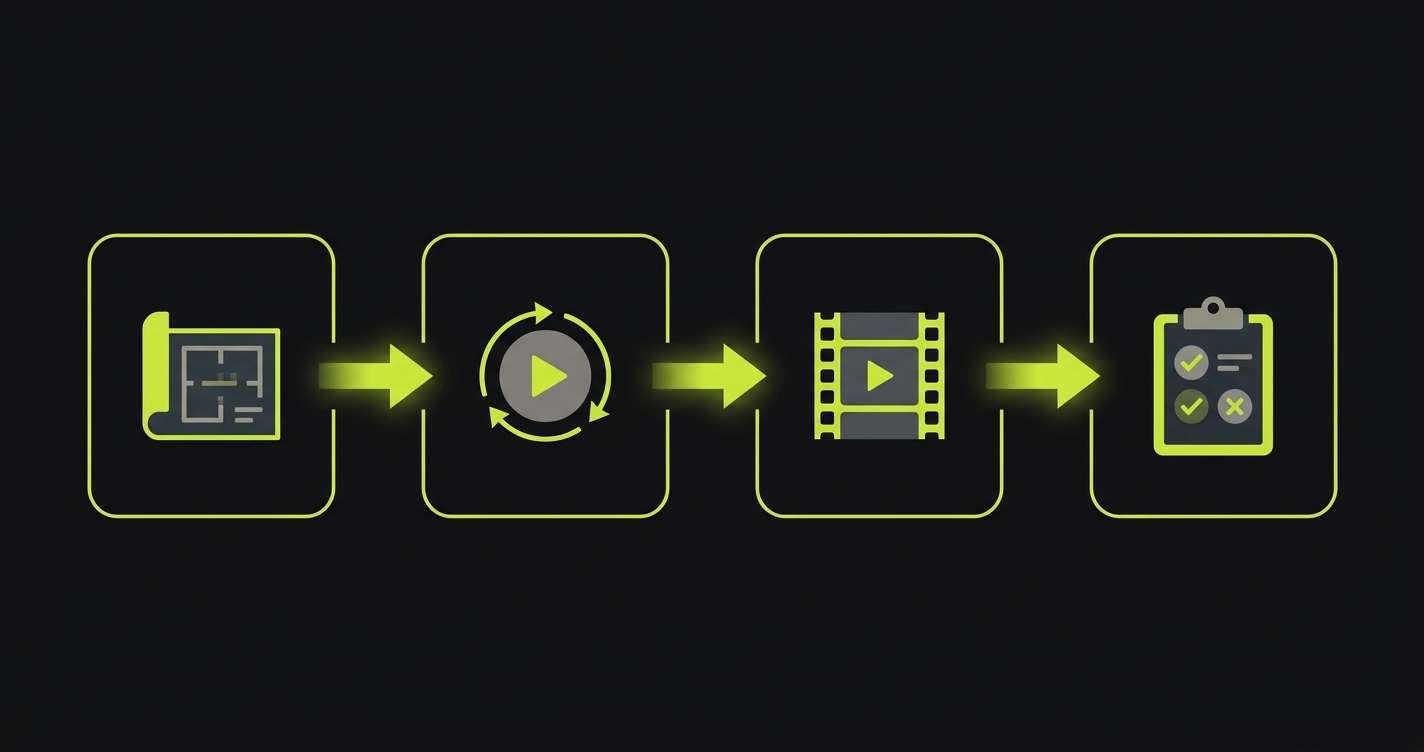
Planning. Our Planner agent reads your codebase statically. It does not click through your app. It reads routes, components, API contracts, and authentication flows. From that reading, it produces a TEST_PLAN: a structured document describing what user flows exist, what state they depend on, and what a correct outcome looks like for each. If a flow requires specific database state (a paid subscription, a team with members, an uploaded file), the Planner generates the setup endpoints needed to create that state before the test runs. No fixture files. No seed scripts you have to maintain.
Generation. The Generation (Automator) agent executes the TEST_PLAN against your running application. It runs on managed preview environments, one per PR, so every branch gets its own isolated test run. The agent exercises each planned flow, recording an EXECUTION_TRACE that captures video, screenshots, network logs, and console output for every step. Verification layers at each step ensure the agent follows the intended path rather than taking random routes.
Replay. The Replay stage re-runs the EXECUTION_TRACE deterministically. No LLM is invoked during Replay. The recorded steps are executed against the same environment, producing a pass or fail for each assertion. Replay is what runs in CI on every subsequent push after the initial Generation run. It's fast, predictable, and agent-free. When the UI changes in ways that affect a flow, the Replay stage detects the mismatch and triggers intent re-derivation: the Planner re-reads the updated codebase and produces a revised TEST_PLAN, then Generation re-executes. The original intent is preserved even when the implementation changes.
Reviewer. The Reviewer agent reads every failure from the Replay run and classifies it. APPLICATION BUG means the app behaved incorrectly relative to its own code's stated intent. AGENT ERROR means the agent made a mistake during Generation that caused a false positive. This distinction is what makes the failure signal trustworthy. A suite that cries wolf on every deploy trains engineers to ignore failures. Autonoma's Reviewer is what keeps the signal clean.
The runtime for all of this is managed preview environments, one per PR. Every branch gets an isolated stack. Tests run there. Results post back to the PR comment. No shared staging environment. No "but it works on my machine."
Where automated E2E testing fits next to your existing stack
Here is how the major options compare on the dimensions that matter for a team evaluating automated E2E testing in 2026. See also our Playwright vs Cypress comparison for a deeper framework-level breakdown.
| Capability | Cypress | Playwright | Mabl | qa.tech | Autonoma |
|---|---|---|---|---|---|
| Writes test code | You do | You do | Recorder generates it | AI generates it | No test code |
| Runs in CI | Yes | Yes | Yes | Yes | Yes, per-PR |
| Self-heals | No | No | Locator-weighted | Partial | Intent re-derivation |
| Works without QA team | No | No | Partial | Partial | Yes |
| Tests AI-generated code | Only if someone writes the tests | Only if someone writes the tests | Only if someone records flows | Partial | Automatically, per PR |
Cypress and Playwright are excellent frameworks. If you have a QA team that writes and maintains test code, they remain strong choices. The gap they cannot close is the authoring gap: someone has to write the tests. Mabl closes the authoring gap partially with its recorder, but the artifact it produces is still a recorded script that breaks when the UI changes in ways the locator-weighting does not anticipate. qa.tech is the closest competitor on the AI-authoring dimension, and it produces test code as its output. That code still needs to live somewhere and still accumulates debt as the codebase changes.
Autonoma produces no test code. The artifact is the Replay trace, derived from the codebase. When the codebase changes, the trace is re-derived. The maintenance loop closes.
The disambiguation is the point. "Automated E2E testing" that automates only execution is half the job. The artifact that sits between your codebase and your confidence, the test file, is the thing that grows brittle, demands maintenance, and falls behind when AI-generated code moves faster than human test authors. We built Autonoma to close that gap with an authoring-included, four-stage pipeline that treats your codebase as the spec and the Replay trace as the output. For a deeper read on what fully autonomous testing looks like at the system level, see our autonomous testing overview.
FAQ
It replaces the need to write Playwright tests, not Playwright as a browser automation layer. Our agents use browser automation internally. What changes is that you no longer author or maintain the test files. Teams that have an existing Playwright suite and QA engineers who own it can keep running it. Autonoma adds authoring-included coverage on every PR without requiring anyone to extend the Playwright suite when the codebase changes.
They keep running. Autonoma does not replace your existing test suite. Our pipeline generates additional coverage from your codebase on every PR. Over time, teams typically find that their manually authored tests cover fewer scenarios than the generated ones, and some choose to deprecate the maintained suite. But that is a choice, not a requirement. Start with Autonoma running alongside your existing tests and compare the coverage and failure signal quality.
Yes. Our pipeline integrates with GitHub Actions, GitLab CI, and most major CI providers. Results post back to the PR as a comment with pass/fail status, a link to the Replay trace, and the Reviewer's failure classification. You can configure the pipeline to block merges on APPLICATION BUG failures and pass on AGENT ERROR classifications.
The artifact is a Replay trace: a structured record of every action the Generation agent took, with its input state, observed output, screenshots, and network logs. The trace is committed to your repo alongside the PR. It is versionable, inspectable, and re-runnable without re-invoking any AI agents. Replay runs are deterministic and fast. When the codebase changes in ways that affect a flow, the trace is regenerated from an updated TEST_PLAN derived from the new code.



