
Automated E2E testing is the practice of using software to verify complete user flows across a deployed application, from the browser through the backend, without human intervention. The category has gone through three distinct generations: record-and-replay tools like Selenium IDE (2004), coded frameworks like Cypress and Playwright (2017-2020), and AI-native platforms that generate and maintain tests from your codebase automatically (2023-present). This article surveys the landscape, compares the four most significant tools (Selenium, Cypress, Playwright, and Autonoma), and includes a practical decision framework by team profile, a section on e2e testing in CI/CD, and guidance on running deployment testing automation against preview environments.
The year Selenium was created, the average web application had a few dozen pages and a deployment cycle measured in months. Today, AI coding tools ship hundreds of changed files per day and every pull request generates an ephemeral preview environment. The mismatch between the pace of code output and the pace of test authorship is the defining QA problem of 2026.
E2E testing has gone through three generations of tooling in response to this pressure. Each generation reduced the maintenance burden inherited from the one before. Understanding where each tool sits in that arc, and which problems each generation actually solved, is the prerequisite for making a sensible tool choice.
What Is Automated E2E Testing?
Automated end-to-end testing is the practice of validating a complete user flow against a running application without human intervention. Where unit tests verify isolated functions and integration tests verify that services connect correctly, E2E tests exercise the entire stack from the user's perspective: open a browser, log in, complete a checkout, verify the confirmation email arrived. Every layer in between, including the UI, the API, the database, and any third-party integrations, is exercised in a single test run.
In an automated E2E test, a script (or, increasingly, an AI agent) drives the browser, asserts on outcomes, and reports results. The key metric is coverage per deployment: how much of your application's critical behavior is verified before a change reaches production, and how reliably can that verification scale as the codebase grows?
This is why automated E2E testing is a distinct category from unit or integration testing. It is the last line of defense against regressions that only surface in the full running application. A unit test cannot catch a bug that occurs because the payment service returns a slightly different JSON structure than the cart expects. An E2E test catches it because it actually completes the transaction.
The E2E Testing Evolution Framework
Every generation of E2E tooling emerged because the previous generation imposed a maintenance cost that eventually outweighed its benefits. The story is not that each tool replaced the previous one. It is that each generation solved one specific problem the previous generation created.
Generation 1 (record-and-replay) reduced manual testing labor. You demonstrated a flow once, the tool recorded it, and it replayed it automatically. The problem it created: tests were fragile. Any UI change, a moved button, a renamed class, a restructured form, broke the recording.
Generation 2 (coded frameworks) solved the fragility problem by giving developers control. Instead of recording a literal interaction, engineers wrote tests against stable element locators and structured selectors. Tests survived UI changes better because humans could write intentional, resilient assertions. The problem it created: a significant maintenance surface. Test code is code. It needs to be written, reviewed, and updated every time the application changes.
Generation 3 (AI-native) is solving the maintenance surface problem. Instead of recording a flow or writing a test, you connect your codebase and agents derive what should be tested from the code itself. Tests self-heal when the code changes because the agents re-derive them from the current state, not from a previously recorded session.
Generation 1: Selenium and the Record-and-Replay Era
Selenium started in 2004 inside ThoughtWorks. Jason Huggins built it to automate testing of a web application he was working on. The name came from the toxicity of selenium to mercury, a jab at a competing tool called Mercury Interactive. The project eventually became the Selenium WebDriver project, standardized under the W3C as the WebDriver specification, and is now the foundation of browser automation across the industry.
Selenium's longevity is remarkable. Twenty-two years after its creation, it powers test suites at some of the largest enterprises in the world. The reasons are structural: Selenium supports every major browser (Chrome, Firefox, Safari, Edge, IE), every major programming language (Java, Python, C#, Ruby, JavaScript), and has integrations with every test management platform in the enterprise stack. For organizations with compliance requirements tied to specific browser versions, or with legacy test infrastructure built over a decade, Selenium is not a choice, it is an inherited commitment.
The honest assessment of Selenium for new projects is harsher. Setting up a Selenium grid for parallel execution is a non-trivial infrastructure problem. Selenium tests are notorious for flakiness caused by timing issues, because WebDriver sends commands over HTTP to a separate browser process and the synchronization between command and state is inexact. The developer experience is significantly worse than what Generation 2 tools offer.
Still, Selenium remains the most-used browser automation framework in enterprise environments, and dismissing it because it is old misunderstands why it has lasted.
Generation 2: Playwright and Cypress, the Coded-Test Golden Age
In 2017, a small Austin startup called Cypress released a testing framework that was conspicuously different from Selenium in one key way: it ran inside the browser, not alongside it. Instead of controlling a browser via HTTP commands, Cypress executed test code in the same JavaScript runtime as the application under test. This eliminated an entire class of timing and synchronization problems.
Cypress's developer experience became its defining feature. The interactive test runner with time travel debugging, where you can hover over any step in a completed test and see the DOM state at that moment, changed what it felt like to write and debug tests. JavaScript teams adopted it rapidly. By 2021, Cypress was the dominant E2E framework for JavaScript applications.
The architectural choice that made Cypress fast also created its most significant limitation. Because Cypress executed inside the browser, it was constrained by same-origin policy, making tests that involved multiple domains (OAuth flows, third-party payment providers, cross-subdomain navigation) difficult. Cypress v12 introduced experimental multi-origin support and subsequent versions have improved it, but the constraint shaped how Cypress tests were designed for years. For deeper coverage of what Cypress offers today, the Cypress documentation is the authoritative source.
Playwright arrived in 2020 from Microsoft, built by some of the engineers who had worked on Puppeteer at Google. Where Puppeteer was Chrome-only, Playwright was built from the start to support Chromium, Firefox, and WebKit (Safari) through a unified API, using the Chrome DevTools Protocol for Chromium and a purpose-built protocol adapter for WebKit. Multi-browser support without changing test code was the core differentiator.
Playwright also introduced auto-waiting: instead of requiring engineers to manually insert waits and expect-to-be-visible assertions, Playwright's locator API automatically waits for elements to be actionable before interacting with them. Combined with built-in test isolation (each test gets a fresh browser context by default), parallel execution, and a first-class TypeScript API, Playwright became the default recommendation for new projects by 2023.
The Playwright documentation has become one of the best in the testing ecosystem. For teams wiring up CI/CD specifically, our Playwright GitHub Actions guide covers the full setup from localhost testing through dynamic preview URL workflows.
Both tools are open source. Both are excellent. The choice between them is genuinely situational.
Cypress wins for JavaScript teams with single-origin applications who prioritize developer experience and want an exceptional interactive debugging environment. Playwright wins for teams that need cross-browser coverage, handle multi-origin flows, want native parallel execution, or are building CI-first workflows where the headless runner matters more than the interactive one.
Generation 3: AI-Native Testing
The Generation 2 tools solved fragility. They did not solve maintenance. A well-maintained Playwright suite for a medium-complexity application might have hundreds of test files, organized into page objects and fixtures, with custom helpers for common flows. When the application changes, those tests change too. Someone has to update them. That someone is usually an engineer, often a senior one, and the time spent maintaining tests is time not spent building features.
This is the problem AI-native testing is designed to solve. The category is defined by a few capabilities working together: tests are generated from code analysis (not from human recordings or natural language descriptions), they run against the deployed application, and they self-heal when the application changes, because the agents re-derive the test logic from the current codebase rather than from a frozen snapshot.
Autonoma is the most mature platform in this category as of 2026. The architecture uses four agents, split into a primary pair and a secondary pair. The Planner agent, one of the two primary agents, reads the codebase, including routes, components, and data models, and derives the test cases that should exist. It also handles database state setup automatically, generating the endpoints needed to put the application in the right state for each test scenario. The Diffs Agent, the other primary agent, runs on every pull request and adds, deprecates, or otherwise maintains test cases based on what actually changed in the code diff, which is how the suite stays current without manual upkeep. On the secondary side, the Executor agent runs the planned tests against a live preview environment, and the Reviewer agent classifies each result as a real bug, an agent error, or a mismatch between the test plan and the application.
The honest trade-offs for Generation 3 are worth stating plainly. AI-native testing is a younger category than Playwright or Cypress. The verification layers in these platforms are still maturing. Teams with highly complex legacy test requirements, specific assertion patterns, or compliance-mandated test documentation formats may find the AI generation output does not match their exact specifications without configuration. Autonoma is open source under the Business Source License (BSL 1.1), which converts to Apache 2.0 in 2028, so teams that want to self-host or inspect the runtime can do so; the managed platform on top of it is what Autonoma sells commercially.
The direction of travel is clear. Every generation of E2E tooling has reduced the amount of human effort required to maintain test coverage. AI-native testing is the next point on that curve.
Automated End-to-End Testing Tools: Side-by-Side Comparison
| Tool | Generation | Language | Browser support | Test authoring | Self-healing | Preview env support | CI/CD integration | Maintenance burden | Open source |
|---|---|---|---|---|---|---|---|---|---|
| Selenium | Gen 1 | Java, Python, C#, Ruby, JS | All browsers + IE | Manual (code) | None | Possible, config-heavy | Strong, any CI | High | Yes |
| Cypress | Gen 2 | JavaScript / TypeScript | Chromium, Firefox, WebKit (limited) | Manual (code) | None | Good, requires URL wiring | Strong, native GitHub Actions | Medium | Yes |
| Playwright | Gen 2 | JS/TS, Python, Java, C# | Chromium, Firefox, WebKit | Manual (code) | None | Excellent, URL-configurable | Excellent, GitHub Actions native | Medium | Yes |
| Autonoma | Gen 3 | No code required | Chromium (Playwright-backed) | AI-generated from codebase | Yes, codebase-aware | Purpose-built | GitHub Actions + Vercel Checks | Near-zero | No (built on Playwright) |
E2E Testing in CI/CD: Where Automation Meets the Pipeline
Before preview environments enter the picture, there is a more fundamental question: where do automated E2E tests belong inside a CI/CD pipeline, and what does a reasonable pipeline actually look like? The short answer is that E2E tests sit at the end of the pre-deploy stages, after unit and integration tests have passed, and before the change is promoted to production.
A typical modern pipeline looks like this. A pull request opens. The CI system runs linting, static analysis, and unit tests first, because they are fast and catch the cheapest errors. Integration tests run next, typically against locally spun-up service dependencies or containerized databases. If those pass, the code deploys to a preview environment or a shared staging target, and E2E tests run against the deployed application. Only after E2E tests pass does the pipeline allow the change to merge and deploy to production.
The practical complications start with runtime. E2E tests are slower than unit tests by an order of magnitude or more. A Playwright suite covering a medium-complexity SaaS application can easily run for ten to thirty minutes end to end. Teams handle this in a few common ways: splitting tests into a PR-required subset (fast critical-path coverage) and a nightly full suite (deeper but slower), parallelizing tests across multiple CI runners or shards, and quarantining flaky tests into a separate job so they do not block merges while they are being fixed.
Test data management is the second recurring challenge. E2E tests need the application in a specific state (a user account that exists, a product in the catalog, a cart with an item), and that state needs to be reset or isolated between runs so tests do not interfere with each other. Approaches range from fixture-based seeding (load a known data snapshot before each run), to per-test database transactions that roll back after completion, to API-level setup where tests call endpoints to create the required state at the start of each scenario.
The third challenge is reporting. When an E2E test fails in CI, the engineer needs enough signal to diagnose the failure without rerunning locally. That means screenshots or video of the failing interaction, the full DOM state at failure, and ideally a trace file that captures the network and console activity. Playwright's built-in trace viewer solves this well; Selenium and Cypress have their own equivalents. The goal is a single link in the PR that shows exactly what went wrong, not a stack trace with no context.
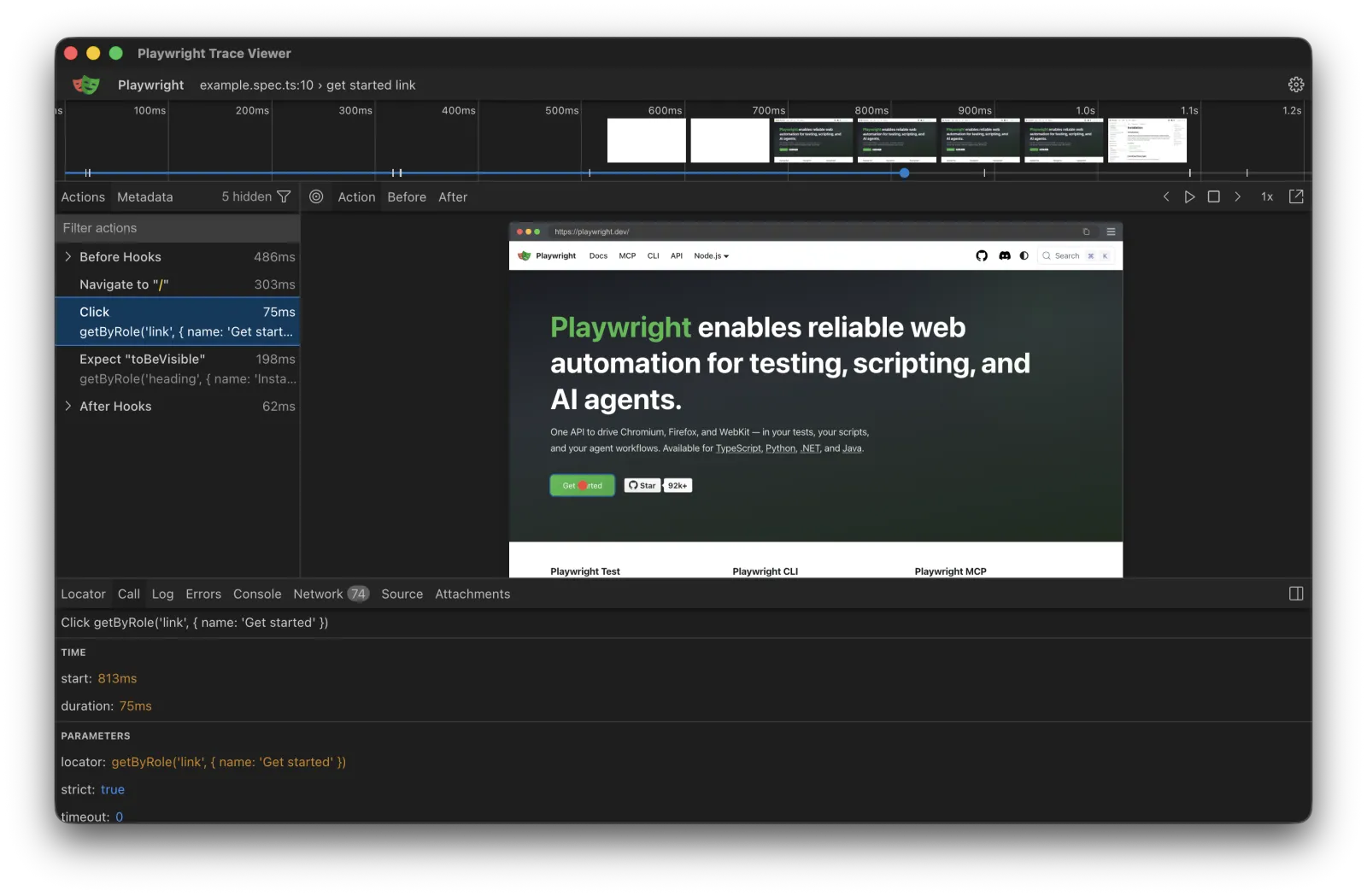
This is the general shape of automated E2E testing in CI/CD. The specific complication for modern teams is that the target of the tests keeps moving, because every pull request deploys to a unique URL. That is what preview environments solved, and what automated E2E has to adapt to.
E2E Testing on Preview Environments: Where Automation Meets Deployment
Preview environments changed how E2E testing fits into the deployment lifecycle. When Vercel popularized per-PR ephemeral deployments around 2020, the concept spread rapidly. Today, Netlify, Railway, Render, and most modern deployment platforms support some form of preview environment: a unique URL, generated per pull request, that reflects exactly the code in that branch.
The appeal for E2E testing is obvious. Instead of running tests against a shared staging environment that may be out of sync with the branch under review, you run them against the exact code the reviewer is evaluating. Catch the regression before merge, not after.
The challenge is that preview environments are dynamic. The URL does not exist when the pull request opens. The deployment takes time. The address changes with every PR. Each generation of E2E tooling handles this differently.
Selenium can be configured to point at a preview URL, but the operational overhead is substantial. You need CI/CD scripts that wait for the deployment to become ready, extract the URL from the deployment platform's API, pass it to the test runner, and clean up afterward. For teams already running Selenium grids, adding preview environment support means new infrastructure work. It is achievable, but it is not something Selenium was designed for.
Playwright handles preview environments well, provided you wire up the URL correctly. The standard pattern is to trigger a GitHub Actions workflow on the deployment_status event, wait for the deployment to become ready, extract the URL, and pass it as BASE_URL to the Playwright test runner. This works cleanly on Vercel, which fires the event reliably. On other platforms, you need polling scripts that query the deployment API. Our Playwright GitHub Actions guide shows all three levels in full, including the deploy-wait logic. For E2E testing on preview environments more broadly, the e2e testing preview environments guide covers platform-specific patterns in depth.
Autonoma is the only tool in this comparison built with preview environments as a first-class workflow. Connect the platform to your deployment provider, and Autonoma runs against every preview URL automatically. There is no GitHub Actions YAML to author, no deploy-wait polling to maintain, no URL extraction logic. The agents receive the preview URL when the deployment completes and run the test suite against it. The results post back to the pull request as a deployment check. This is the workflow we built Autonoma around, and it is the reason preview environment support is listed as "purpose-built" in the comparison table rather than "good, requires URL wiring."
Choosing the Right Tool: Decision Framework by Team Profile
The comparison table is useful for understanding differences. It is less useful for making a decision, because the right tool depends more on team context than on feature checkboxes. Here is how we think about it.
Enterprise teams with compliance requirements or existing investment in legacy browsers land on Selenium, often without a real choice. If your organization requires testing on Internet Explorer 11 (still a requirement in certain regulated industries), Selenium is the only option. If you have an existing Selenium suite with ten years of tests and institutional knowledge built around it, the migration cost to Playwright exceeds the benefit for most teams. The answer is not "Selenium is better" but "the switching cost is too high given what you already have." Selenium's enterprise integrations and multi-language support also matter for large organizations where the QA team writes in Java while the development team writes in Python.
JavaScript-first teams building single-origin applications who value developer experience above all else should use Cypress. The interactive test runner is genuinely better than anything else available for debugging test failures. The time travel debugging, the real-time reloads, the clear failure messages: these matter when junior engineers are writing and maintaining tests. The cross-origin limitation matters less if your application is genuinely single-origin (no OAuth redirects, no third-party payment flows, no cross-subdomain navigation). Cypress's GitHub Actions integration is also strong. See our Playwright E2E testing guide for a deeper comparison of Playwright and Cypress side by side.
Modern teams with cross-browser requirements, complex user flows, or a CI-first workflow should default to Playwright. It is the strongest Generation 2 framework for teams starting fresh. The multi-browser support is not just theoretical: WebKit coverage catches Safari-specific bugs that affect a meaningful percentage of users on most consumer-facing applications. The parallel isolation model makes test suites fast. The TypeScript API is excellent. And the ecosystem around Playwright for GitHub Actions is mature enough that most CI/CD problems you will encounter have documented solutions.
Teams that want E2E coverage without the ongoing cost of writing and maintaining tests should look at Autonoma. This is the most important distinction to make honestly. If your team has no QA engineers and developers are already stretched, the promise of Generation 2 tools (write great tests, get great coverage) runs into a practical constraint: someone has to write them. Autonoma removes that constraint by generating tests from your codebase. The trade-off is that you are trusting AI agents to determine what should be tested. For teams where the alternative is no E2E coverage at all, that trade-off is usually the right one.
The through-line across all four profiles is maintenance burden. Every team that adopts E2E testing eventually confronts the cost of keeping tests current as the application changes. The tools that minimize that cost without sacrificing coverage quality will win in the long run. That is the direction all three generations of E2E tooling have been moving, and it is the reason AI-native testing is where the category is heading.
Picking between Playwright, Cypress, and AI-native? We've seen each play out, happy to compare notes. Grab 20 min with a founder
FAQ
Integration testing verifies that individual components or services work correctly when connected to each other. E2E testing verifies that a complete user flow works correctly from the user's perspective, including the UI, backend, database, and any third-party services. Integration tests run in isolation with mocked boundaries at the edges; E2E tests run against the real, deployed application. The practical difference: an integration test confirms your payment service talks correctly to your order service; an E2E test confirms a user can actually complete a purchase and receive a confirmation email.
Playwright is the strongest fit for CI/CD-first teams. Its parallel test execution, built-in retry logic, and clear HTML reports integrate cleanly with GitHub Actions, GitLab CI, and most modern pipelines. For teams running automated E2E tests against preview environments specifically, an AI-native layer like Autonoma eliminates the URL-extraction and deploy-wait complexity that makes Playwright-in-CI brittle at scale. Our Playwright GitHub Actions guide covers all three CI levels in detail.
Not universally, and that is not quite the right framing. AI-native testing platforms like Autonoma generate and maintain tests that run on top of frameworks like Playwright. The AI layer removes the need for humans to write and maintain test code; the framework layer still handles browser control and assertion execution. For new codebases, AI-native generation can replace the human authoring step entirely. For existing Playwright or Selenium suites, the most practical path is augmenting with AI generation for new test coverage, not discarding what already exists.
The approach differs by tool generation. With Playwright, you trigger a GitHub Actions workflow on the deployment_status event, wait for the deployment to become ready, extract the preview URL, and pass it as BASE_URL to your test run. This requires careful handling of deploy timing and platform-specific API differences. With Autonoma, you connect the platform to your deployment provider and it runs automatically against every preview URL with no YAML to manage. The e2e testing preview environments guide covers both paths with platform-specific examples.
Both are excellent Generation 2 frameworks with genuinely different strengths. Cypress offers the best developer experience for JavaScript teams building single-origin applications: time travel debugging, an exceptional interactive test runner, and a fast feedback loop. Playwright has broader cross-browser support (Chromium, Firefox, WebKit), native parallel execution, and handles multi-origin flows cleanly. For teams starting fresh in 2026, Playwright is the default recommendation for most new projects, particularly those requiring cross-browser coverage or CI-first deployment workflows. Our Playwright E2E testing guide covers the comparison in more depth.
The leading AI-native testing platforms are production-ready for most web applications. Autonoma is running on production codebases with real CI/CD pipelines, generating tests from code analysis and self-healing as those codebases change. The honest caveat: AI-native testing is a younger category than Playwright or Cypress, and the verification layers these platforms use are still maturing. Teams with highly complex legacy requirements or compliance-mandated test documentation may find a hybrid approach more pragmatic initially, using AI generation for new tests while keeping existing scripted tests in place.



