
Self-healing test automation describes any system that recovers a broken test without human intervention. Three mechanisms exist: locator-weighting (score DOM nodes by attribute similarity), visual-diff (pixel or perceptual comparison), and intent re-derivation (ask whether the recovered element serves the same role in the flow). Every major vendor on the current SERP implements only the first or second. Autonoma ships the third.
Every vendor marketing "self-healing tests" in 2026 is selling the same thing: locator-fallback weighting. A CSS selector breaks, an ML model scores nearby DOM nodes, and the test silently continues on the closest match. That mechanism was novel in 2019. It has been table stakes for four years. What none of those vendors address is what happens when the closest match is the wrong element and a real bug ships green. That failure mode has a name. We call it a silent heal.
Autonoma was built to solve the problem that follows a silent heal. This article publishes the three-mechanism taxonomy, plots the named competitors honestly inside it, and explains why Generation 1 self-healing (locator-weighting) is structurally incapable of eliminating the false-positive surface that matters most. If you are looking for a broader overview of how self-healing test automation fits into a testing strategy, that article covers the adoption side; this one covers the mechanism.
Why every SERP result for self-healing tests is the same article
Search "self healing test automation" and click the top ten results. Mabl, Testim, Functionize, BrowserStack, LambdaTest, Katalon, testRigor, Provar, Applitools, Perfecto. Each article will tell you some variant of the same story: AI watches your test run, learns which DOM attributes are stable, and falls back gracefully when a selector breaks. The mechanism is not wrong. It solves a real problem. Selector instability is responsible for a large fraction of test maintenance burden.
The problem is that none of those articles disambiguate the mechanism from the outcome. They say "self-healing" and mean "locator-fallback with better weighting." They do not say what happens when the weighting is wrong. They do not define what it would mean for the test to heal into the wrong element. They do not surface the failure mode where the test passes, the developer merges, and the bug ships.
That is a silent heal. And it is the failure mode that locator-weighting, by design, cannot catch.
The three-mechanism taxonomy
Self-healing mechanisms differ not in degree but in kind. Here are the three that exist, what each one can and cannot repair, and which vendors implement each.
Locator-weighting
Locator-weighting is the mechanism almost every vendor implements. When a test step fails because the targeted element cannot be found, the system scores all candidate DOM nodes against a weighted set of attributes: element type, ID, class, text content, ARIA role, position. The node with the highest score becomes the new target. If the score exceeds a threshold, the test heals and continues. The locator is saved for the next run.
What it can heal: cosmetic redesigns. A button moves two pixels. A class name is renamed. A wrapping div is added. The element is still there; its attributes are mostly unchanged. Locator-weighting finds it.
What it cannot heal: semantic changes. A form is restructured and two buttons swap roles. A primary CTA is replaced by a secondary one in the same layout position. A feature is renamed and the surrounding copy changes. In these cases, locator-weighting will find an element that scores well and heal to it. Whether that element serves the same role in the flow is not a question locator-weighting asks.
Who implements it: Mabl (ML-ranked DOM attribute weighting plus visual fallback), Testim (Smart Locators: a trained model that scores DOM elements by stable attributes), Katalon (ranked locator strategy chain from XPath to attribute to image). These are honest Gen-1 implementations. They are effective within their domain and should not be dismissed. Their limit is that the domain excludes semantic changes.
Visual-diff
Visual-diff systems compare what the application looks like rather than what the DOM contains. Applitools is the canonical implementation. The system captures a baseline screenshot and compares subsequent runs using perceptual or pixel-level diffing. Functionize uses a hybrid of locator-weighting plus visual-diff, which is why it is often marketed as more sophisticated than pure-locator tools.
What it can heal: cosmetic regressions. Misaligned elements, incorrect colors, truncated text. It catches visual bugs that locator-weighting ignores entirely.
What it cannot heal: a renamed-and-moved button whose visual appearance is identical to the original. Applitools sees the same pixels and passes. The button's function has changed; its rendering has not. Visual-diff has no mechanism to detect that.
Honest placement: Applitools is often lumped into "self-healing" SERPs because of its visual-AI positioning. That is a category error. Applitools is a visual verification layer. It does not heal tests in the locator sense. It catches visual regressions. Paired with a locator system, it adds a dimension. Alone, it does not address locator failures. Functionize, which pairs both, is a Gen-1.5 hybrid: better coverage than pure locator-weighting for cosmetic changes, but still not equipped for semantic changes.
Intent re-derivation
Intent re-derivation is the third mechanism. It is meaningfully different in structure from the first two. When a test step fails, instead of asking "which DOM node is most similar to the one I was targeting?", the system asks "which DOM node serves the same role in this user flow that the original step was designed to exercise?"
Answering that question requires two things: a representation of the original intent (not just the original selector) and a model capable of evaluating whether a candidate element satisfies that intent given the current DOM and application context. Locator-weighting has neither. Visual-diff has neither.
testRigor sits closest to this mechanism among the existing vendors, but in a shallow implementation. testRigor re-resolves its natural-language step descriptions against the current DOM at run time ("click the submit button" resolves fresh on each run). That eliminates locator staleness by design. The limit is that the resolution is single-step and shallow: the system evaluates each step in isolation without a cross-step intent model. It cannot evaluate whether the resolved element makes sense in the context of the surrounding flow.
Full intent re-derivation, as we implemented it in Autonoma, requires a multi-step intent model. The original intent of each step is stored as a natural-language description plus structured data, derived from the Planner agent's codebase reading. When the Replay stage fails, the Reviewer agent reads the original intent, examines the new DOM, and reasons about whether any candidate element actually serves that intent in the updated application. This is not a similarity score. It is a semantic judgment.
The silent-heal failure mode
The silent false-positive surface is where locator-weighting's structural limit becomes a product risk. Here is the mechanism.
A test step records: click element with ID btn-submit-order. The DOM element is a button labeled "Submit Order" on the right side of a checkout form. The developer ships a redesign: the button is renamed to "Place Order" and moved to a sticky bottom bar. A secondary button labeled "Save Draft" is added in approximately the position the original occupied.
Locator-weighting runs. It cannot find btn-submit-order. It scores candidates. The "Save Draft" button, now positioned where "Submit Order" was, scores well on position and element type. "Place Order" is new, with a different ID and different class. The weighting may favor "Save Draft" over "Place Order." The test clicks "Save Draft" instead of "Place Order." The test passes.
A draft was saved. An order was not placed. The checkout flow is broken. The test is green.
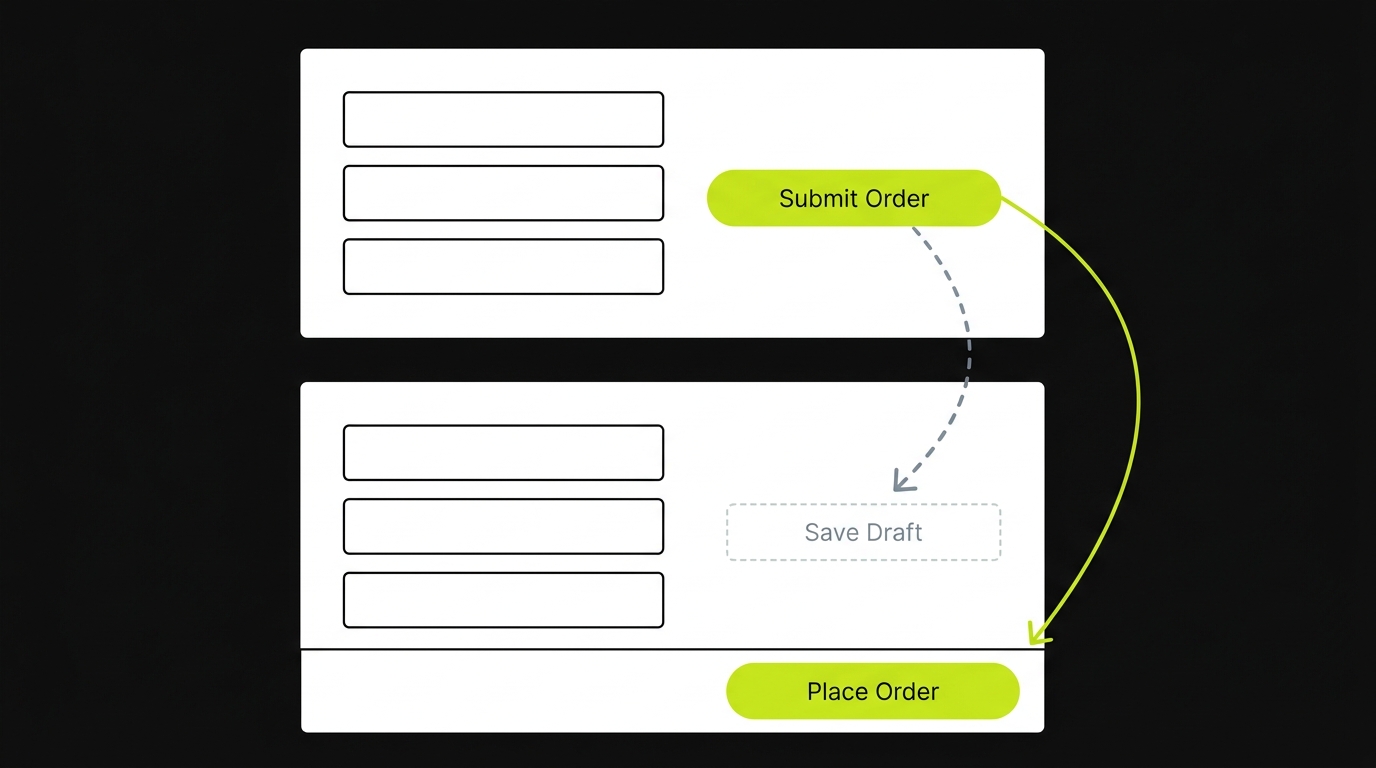
That event is a silent heal. The test healed correctly in the locator sense (it recovered from a broken selector) and incorrectly in the behavioral sense (it exercised the wrong action). The false-positive surface is the probability that a locator-weighting recovery produces this outcome. For cosmetic changes, the probability is low. For semantic changes like the one above, it is non-trivial and unquantifiable without an intent layer.
What makes this failure mode particularly expensive is that it is invisible in the test report. A silent heal does not appear as a warning. It does not annotate the passing test with "this selector was recovered." The developer sees green. The PR gets merged. The bug reaches production. Discovery happens through a user report or a revenue dip, not through the test suite that was supposed to prevent it.
The frequency of silent heals scales with your deployment velocity. A team shipping once a week might encounter one silent heal per quarter. A team shipping AI-generated features multiple times per day is shipping structural UI changes continuously, which means the locator-weighting system is making recovery decisions continuously, each of which carries a non-zero probability of producing a false positive. At that velocity, the compounding risk of locator-weighting self-healing is no longer theoretical.
The silent-heal failure mode is the mechanism behind a broader pattern. We have written about why E2E tests can pass while the product is broken as a category of false confidence. Silent heals are one of the structural contributors to that category.
How Autonoma self-heals
The pattern this article has documented is locator-weighting's inability to distinguish structural change from behavioral change. Recovering from a broken selector is straightforward. Determining whether the recovered element actually serves the purpose of the original step is the hard problem, and it requires reasoning capacity that locator-weighting does not have by design.
Autonoma's pipeline addresses this at the architecture level. The four-stage pipeline (Planning, Generation, Replay, Review) stores intent at the generation phase, not just at the execution phase. When the Generation agent produces a test case, each step is represented as structured data plus a natural-language description of what the step is exercising and why it matters in the flow. "Click the primary CTA in the checkout form to submit the order" is not metadata. It is the test step. The selector is derived from it, not the other way around.
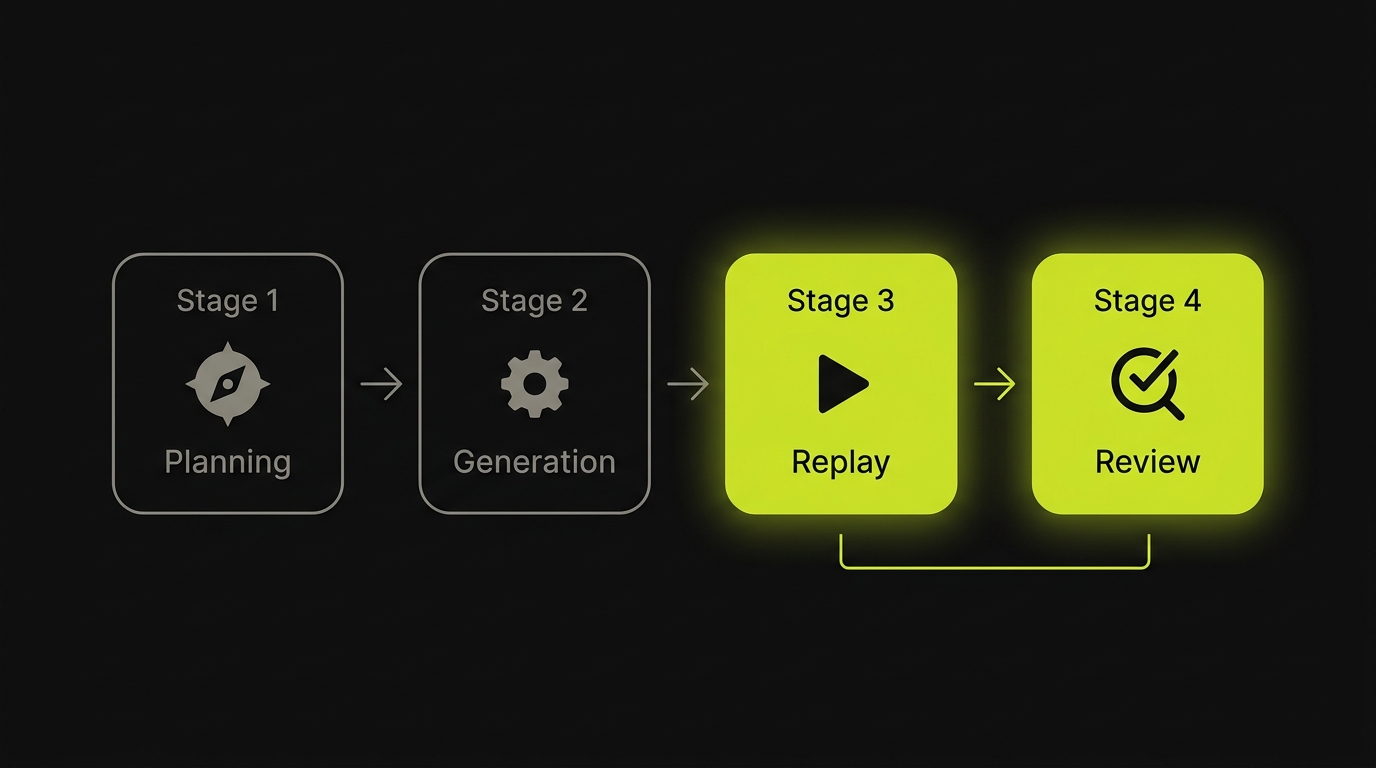
The Replay stage re-executes that trace deterministically. When a Replay step fails because the targeted element is not found, the Replay stage does not attempt recovery on its own. That is by design. Replay is not an agentic testing layer; it is a deterministic execution layer. Its job is to run the recorded trace faithfully and fail loudly when the trace cannot be executed as recorded.
Recovery is the Reviewer agent's responsibility. The Reviewer reads the Replay failure, retrieves the natural-language intent of the failed step, examines the new DOM, and reasons about whether any candidate element satisfies that intent in the updated application context. "Click the primary CTA in the checkout form to submit the order" is evaluated against the new DOM. "Place Order" in the sticky bottom bar is identified as the primary submit action. "Save Draft" is identified as a secondary action. The Reviewer heals to "Place Order." If no candidate satisfies the intent with sufficient confidence, the Reviewer surfaces a structured artifact flagging the step as ambiguous rather than silently healing.
That structured artifact is the false-positive surface control. The output of every Reviewer decision is auditable. Whether the Reviewer healed or flagged is visible in the test report. This is what Generation 2 self-healing looks like: not just recovery, but accountable recovery.
Competitor comparison
| Tool | Mechanism | Heals renamed-and-moved button | Flags silent false-positives |
|---|---|---|---|
| Autonoma | Intent re-derivation via Reviewer agent | Yes, via intent matching | Yes, structured artifact per decision |
| Mabl | ML-ranked locator weighting + visual | Partially (visual layer helps) | No explicit false-positive surface |
| Testim | Smart Locators: stable-attribute scoring | Rarely (pure locator) | No |
| Functionize | Locator weighting + visual-diff hybrid | Partially (visual helps on cosmetic) | No intent layer |
| Katalon | Ranked locator strategy chain | Rarely (XPath, attribute, image) | No |
| Applitools | Visual-diff (not locator-based) | No (same pixels, different function) | No (visual only) |
| testRigor | Natural-language re-resolution (single-step) | Often (no hardcoded selectors) | Partial (no cross-step model) |
A note on testRigor: it is the most honest competitor in this comparison. Because it never stores a selector and resolves the natural-language step fresh on each run, it sidesteps the core locator-staleness problem. Where it falls short is cross-step intent modeling. A step that says "click the submit button" resolves correctly in isolation. Whether "the submit button" in step 7 is consistent with the flow established by steps 1 through 6 is a question single-step resolution does not answer. testRigor is a Gen-1.5 system in the taxonomy: it removes locator staleness as a failure mode, but it does not have an intent model. A renamed-and-moved button will generally resolve correctly because the natural-language description is not attached to a position. A button whose semantic role has changed (primary submit renamed to secondary abort) is not something the single-step model can detect.
A note on Applitools: the visual-diff mechanism is genuinely useful and genuinely different. Applitools catches a class of regressions that locator-based tools miss entirely. Characterizing it as self-healing is imprecise because it does not address locator failures. Characterizing it as irrelevant is also wrong, because the regressions it catches are real. It belongs in the stack as a visual verification layer, not as a substitute for an intent layer.
The honest picture from this comparison is that the industry is solving a 2019 problem well. Locator-weighting has matured. It reduces the maintenance burden of scripted tests significantly relative to naive XPath selectors, and that reduction is real. The problem it does not solve, and was never designed to solve, is the semantic change. For teams running high-frequency deployments on top of AI-generated code, semantic changes are the norm, not the exception. That is the regime where Generation 1 self-healing creates false confidence at scale.
FAQ
Only the locator-flaky subset. Self-healing addresses the case where a selector breaks because the DOM changed. Flakiness rooted in async timing, network instability, or environment state is a different category of problem entirely. A test that fails intermittently because the backend is slow will not be fixed by any self-healing mechanism, because the locator itself is fine. For a deeper breakdown of what actually causes flakiness, the [flaky tests](/blog/flaky-tests) article covers the full taxonomy.
Yes. This is the silent false-positive surface. When a locator-weighting system cannot find the original element, it scores the remaining DOM nodes by attribute similarity and picks the closest match. If the closest match is the wrong element, the test passes with a behavioral regression hidden inside it. Intent re-derivation minimizes this by asking whether the resolved element matches the original purpose of the step, not just its attributes. The Reviewer agent in our pipeline produces an auditable decision for every recovery, so a silent heal is structurally prevented.
Auto-locator re-resolves a selector against the current DOM using attribute weighting or ML scoring. It answers: what element is most similar to the one I was targeting? Intent-driven self-healing asks a different question: does the element I resolved actually serve the same role in the user flow that the original step was designed to exercise? The first is a DOM matching problem. The second is a semantic reasoning problem. You can solve DOM matching with a model trained on attribute co-occurrence. You need a cross-step intent model to solve the semantic version.
Self-healing test automation is any system that recovers a broken test without human intervention. The recovery happens through one of three mechanisms: locator-weighting (score DOM nodes by attribute similarity), visual-diff (pixel or perceptual comparison), or intent re-derivation (ask whether the resolved element serves the same role in the flow). Most vendors marketing self-healing implement only the first.
There is no single best tool. The right choice depends on which mechanism matches your failure modes. For high-frequency UI redesigns where elements move and rename, intent re-derivation handles semantic shifts that locator-weighting silently mishandles. For pure pixel regressions, visual-diff is the right layer. Most production stacks need a tool from more than one category, not a single tool claiming to do all three.
No. Self-healing reduces maintenance for selector-level changes; it does not address tests that exercise the wrong intent, tests that pass against a broken backend, or tests that need rewriting when a feature is replaced. The reduction is meaningful for cosmetic UI churn, but it does not eliminate the work of reviewing whether the test still asks the right question of the application.



