
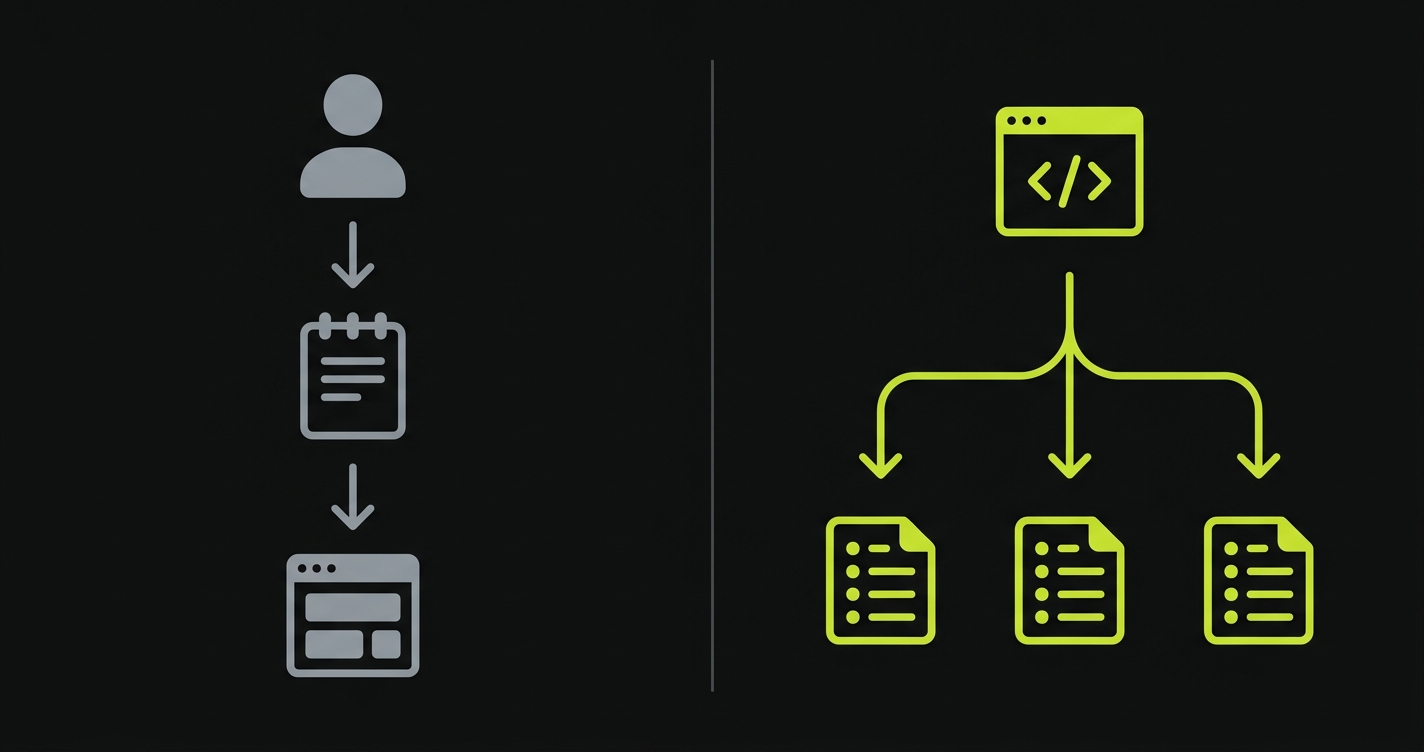
Autonoma vs TestRigor is a comparison between two very different takes on codeless test automation. TestRigor is a codeless test automation platform that uses plain English scripting: a human writes instructions like "click the login button" or "enter 'user@example.com' into the email field," and the AI interprets and executes them. Autonoma takes the opposite approach: no one writes anything. Agents read your codebase, derive test cases from your routes and components, execute them, and self-heal when code changes. If you are evaluating codeless test automation and wondering whether plain English scripting can keep pace with AI-generated code, this comparison covers test creation, maintenance, learning curve, and velocity compatibility in full.
The backlog builds up quietly. A new feature ships on Monday. The test for it gets written by Thursday, if QA has capacity. Another feature ships on Tuesday. That one waits until next week. By the time the sprint is over, the test suite covers last sprint's application, not this one. Nobody panics because it has always been this way.
Then the team adopts an AI coding tool. Features that took a week now take an afternoon. The backlog does not build quietly anymore. It compounds. Plain English test scripting helps, because removing the syntax barrier means QA can write tests faster. But writing faster is still writing. Someone still has to translate every new route and component into a test description.
That is the problem we built Autonoma to solve, and why teams searching for a TestRigor alternative are increasingly asking a different question. Not "how do we make test authorship easier?" but "what if the codebase wrote its own tests?" TestRigor answered the first question well. This comparison is about whether the first question is still the right one to ask.
How Each Tool Creates Tests
The creation experience is where the philosophical split between these two tools becomes concrete.
TestRigor's Plain English Approach
TestRigor tests look like this:
open "https://app.example.com/login"
enter "user@example.com" into "Email"
enter "password123" into "Password"
click "Sign In"
check that page contains "Welcome back"That is readable by anyone. A product manager can understand it. A business analyst can write it. A QA engineer without developer experience can own a full test library in this format. This is TestRigor's clearest strength and the reason teams adopt it.
The plain English layer is more expressive than it looks. TestRigor supports conditional logic, loops, email and SMS validation (built-in mailbox integration), file uploads, and multi-step flows with complex assertions. The syntax is constrained but deliberately so, and within its constraints it covers most real-world E2E scenarios well.
The catch is that someone still writes every test. Every flow that needs coverage requires a human to sit down, describe the steps in TestRigor's plain English format, and push it to the test suite. When new features ship, someone adds new tests. That authorship loop does not close on its own. For a deeper dive into this paradigm difference, see our codeless test automation vs AI testing breakdown.
How We Built Autonoma Differently
When we designed Autonoma, the starting premise was that your codebase already describes your application. Routes define the flows. Components define the interactions. Data models define the state. The spec is already written. It is called source code.
So we built agents that read it. The Planner agent analyzes your codebase: routes, components, authentication gates, data models. It derives test cases from that analysis. A checkout flow with three steps generates tests for each step and the failure scenarios in between. A new API endpoint gets test cases planned for it. The Planner also handles database state setup automatically, generating the endpoints needed to put the application in the right state for each scenario without manual seed scripts.
The Diffs Agent runs on every pull request, reading code diffs to add, deprecate, and maintain test cases as the application evolves. When a component gets refactored, the Diffs Agent reads the diff and updates the relevant tests. Together, Planner and Diffs Agent are the primary pair behind Autonoma's test coverage. Two secondary agents carry out the execution layer: the Executor runs the planned tests against a live preview environment with verification at each step, and the Reviewer classifies each result as a real bug, an agent error, or a test-plan mismatch.
The result: no one writes a test description. No one writes a test script. The test suite exists because the codebase exists. We built it this way because we watched teams drown in test maintenance the moment AI coding tools accelerated their output.
Learning Curve and Time to Value
Both tools position themselves as accessible, but accessible to whom, and how quickly?
| Persona | TestRigor | Autonoma |
|---|---|---|
| Non-technical QA analyst | 1-2 days to first tests. Plain English is learnable; edge cases need practice. | No authoring needed. Role shifts to reviewing generated tests. |
| Developer with QA hat | Under a day. Simple syntax, CI/CD setup in hours. | Under 30 minutes. Connect repo, agents generate suite. |
| Engineering lead evaluating | 1-2 day PoC. Needs someone to author tests. | Connect repo, results in under an hour. No authoring. |
| Business analyst / product | 2-3 days with guidance. Accessible but requires app knowledge. | Not involved in creation. Reviews generated test descriptions. |
TestRigor's learning curve is genuinely low. The syntax requires no programming knowledge. For a QA team that wants to own a test library without developer dependency, TestRigor's onboarding story is strong.
Our "learning curve" with Autonoma is closer to a setup task than a learning exercise. There is no syntax to internalize because there is nothing to write. The time investment is in connecting the repository and validating that the generated tests accurately reflect intended behavior. That validation step matters, but it is different in kind from learning a new scripting paradigm.
Maintenance When Your UI Changes
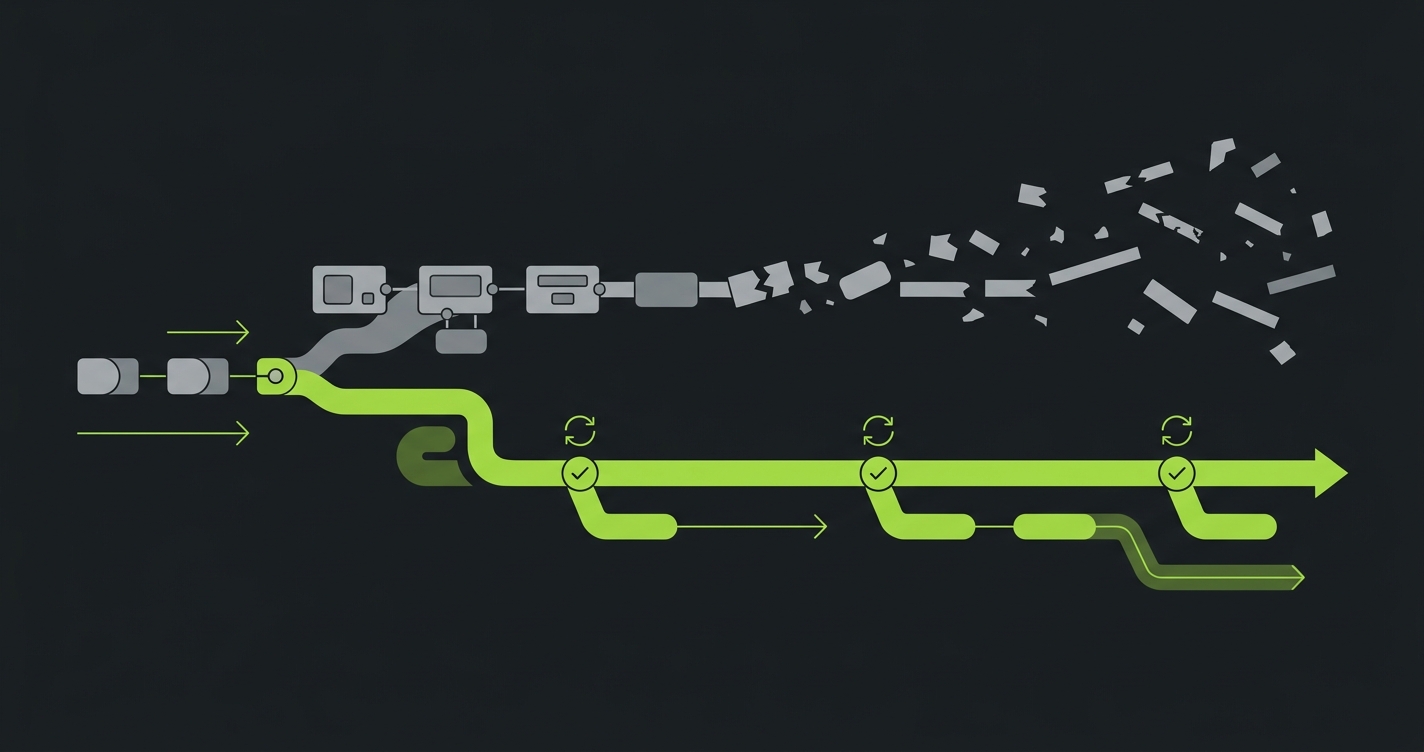
This is where the comparison gets most relevant for teams using AI coding tools. AI-generated code changes frequently. Components get refactored. Routes get renamed. Entire flows get restructured. The maintenance burden of a test suite under these conditions is enormous.
TestRigor describes tests in plain English, which means tests reference the application by what users see, not by CSS selectors or XPath. "Click the login button" is more resilient than $('#login-btn').click(). When a button's class changes, a TestRigor test often survives because the AI still finds "the login button" by its visible text and context.
This is a genuine advantage over traditional script-based frameworks. TestRigor breaks less often on surface-level UI changes than Selenium or Cypress.
Where TestRigor does break is on semantic changes. If the login button text changes from "Sign In" to "Log In," the test that says "click 'Sign In'" now needs updating. If a multi-step checkout flow gets reorganized into a single-page checkout, the sequence of plain English steps describing the old flow no longer matches reality. Someone has to review and rewrite those tests.
This is exactly the scenario we designed the Diffs Agent for. When code changes, our Diffs Agent reads the diff against the codebase. It updates tests based on what changed in the source, not based on whether the UI broke a selector. A restructured checkout flow produces a diff in the route definitions and component tree. The Diffs Agent updates the test logic from that diff. The application's behavior is the ground truth, and the ground truth is in the code.
For teams shipping features at AI velocity, this distinction is not minor. A team using AI coding tools might merge ten pull requests in a day. Each one could touch components and flows. In TestRigor, each change that affects a test's plain English description requires a human to review and update that description. With Autonoma, our Diffs Agent handles it automatically on every pull request, because it reads the same codebase the developers just changed.
Maintenance Cost at Scale
| Scenario | TestRigor | Autonoma |
|---|---|---|
| Button label renamed | Test breaks if script references old label | Diffs Agent reads diff, updates automatically |
| Multi-step flow restructured | Each affected step needs manual review and rewrite | Diffs Agent re-derives tests from updated routes/components |
| New feature via AI coding agent | No test until someone authors in plain English | Planner generates test cases from new code automatically |
| 50 PRs merged in a week | QA must review each PR's impact, update scripts | Diffs Agent processes diffs, fills coverage gaps automatically |
| DB state required for test | Manual seed data setup or custom scripts | Planner generates setup endpoints per scenario |
The maintenance equation changes at scale. A test suite of 20 flows in TestRigor is manageable. At 200 flows, the overhead of reviewing and updating plain English scripts after each sprint compounds. At 500 flows with AI-generated code shipping daily, it becomes a full-time job.
We built Autonoma for that last scenario. The Diffs Agent does not get slower as the test suite grows. Coverage does not require a proportional QA headcount.
AI-Code Velocity Compatibility
This is the central question for teams evaluating testing tools in 2026.
AI coding tools (Cursor, GitHub Copilot, Claude, and others) have fundamentally changed how fast features get built. AI coding tools have fundamentally changed development velocity. GitHub's Copilot research measured ~55% faster task completion, and engineering teams widely report that AI-assisted developers ship features at a significantly accelerated pace. Pull requests accumulate faster. Code surfaces expand faster. Coverage gaps appear faster.
TestRigor's plain English paradigm was designed for a world where QA analysts could keep pace with development velocity. That world has changed. When a team ships 50 PRs in a week through AI assistance, a QA analyst authoring plain English scripts simply cannot write fast enough to maintain coverage.
This is not a criticism of TestRigor's design. Plain English is an elegant solution to the problem it was designed to solve. The problem has outrun the solution.
We built Autonoma for this environment specifically. Our Planner agent's test derivation from source code does not have a human throughput ceiling. It reads new code as fast as new code is committed. Coverage scales with code output, not with QA authorship bandwidth.
For the AI testing tools definitive guide covering the full landscape, including where plain English scripting still wins, that post goes into depth across the full category. For a different dimension of this comparison, the automated code review vs testing post covers how these activities interact when AI generates both the code and the tests.
Where TestRigor Has Genuine Strengths
This comparison would be incomplete without crediting what TestRigor does well.
Non-technical test ownership is TestRigor's clearest advantage. A business analyst or QA professional without developer skills can own a meaningful test library in TestRigor. The plain English syntax is learnable in hours. For organizations where QA is a distinct function staffed by non-developers, TestRigor's authoring experience is well-designed.
Complex assertion logic in plain English is more expressive than it looks. TestRigor handles conditional assertions, loops, and multi-step verifications in a format that non-developers can read and write. This is harder to replicate with other codeless tools.
Built-in email and SMS testing is a practical differentiator. TestRigor has native support for email and SMS inbox validation, which covers authentication flows (email confirmation, SMS OTP) without additional tooling. This is a common testing need and one that most frameworks handle poorly without custom integrations.
Cross-browser and cross-device testing is well-supported in TestRigor, with execution across browser configurations managed by the platform.
For teams where QA is staffed by non-technical analysts who need to own test authorship, and where the application changes at a pace that plain English can track, TestRigor is a well-built tool for that use case. It is included in our best codeless test automation tools roundup for good reason.
Where We Built Autonoma to Win
Every architectural decision behind Autonoma traces back to one observation: the teams we talked to were not struggling to write tests. They were struggling to write tests fast enough. If you are searching for a TestRigor alternative because authorship itself has become the bottleneck, this is the core of what we built differently.
Zero authorship overhead. We eliminated the writing step entirely. Coverage exists from the moment code is connected. There is no ramp period of writing scripts. There is no backlog of untested features waiting for a QA analyst to have time. The Planner reads the code and the coverage exists.
Self-healing maintenance. We built the Diffs Agent because we watched teams spend more time fixing broken tests than writing new features. Test suites do not require a proportional increase in QA effort as the codebase grows. Tests update when code changes, on every pull request. A team of two engineers can maintain coverage over a codebase that would require a dedicated QA team with manual scripting tools.
Developer-workflow integration. We designed Autonoma for teams where testing is a shared responsibility, not a dedicated QA function. Terminal and IDE triggers, PR-level test analysis, and integration with the coding loop mean testing happens in the development context rather than in a separate tool.
AI-velocity compatibility. This is the architectural bet that defines Autonoma. When AI coding tools are producing 10x the code output compared to manual development, only a testing layer that also operates without a human throughput ceiling can keep pace. We built for that world because it is already here.
For a comparison with a different category of tool, the QA Wolf comparison covers a managed service model where human QA engineers run tests on your behalf, which is a different tradeoff between automation and human judgment. For teams evaluating open-source options specifically, our open source alternative to TestRigor comparison covers self-hosting and pricing.
Codeless Test Automation: Full Approach Comparison
| Capability | TestRigor | Autonoma |
|---|---|---|
| Test creation method | Human writes plain English scripts | Agents derive tests from codebase automatically |
| Test creation speed | Fast for skilled users; bottleneck is human bandwidth | Instant; no human authorship required |
| Non-technical authorship | Yes, strong support for non-developers | Not applicable (no authorship) |
| Self-healing | Partial; element-level resilience, not semantic | Full; Diffs Agent reads code diffs |
| New feature coverage | Manual; someone must author tests for new features | Automatic; Planner reads new routes and components |
| Database state setup | Manual seed scripts required | Planner generates setup endpoints automatically |
| Email/SMS testing | Native built-in support | Covered through API and flow testing |
| CI/CD integration | GitHub Actions, Jenkins, and others | GitHub Actions, GitLab CI, terminal/IDE triggers |
| Assertion expressiveness | High; conditional logic and complex assertions in plain English | AI-determined; complex scenarios covered through code analysis |
| Learning curve | Low (hours to days); plain English syntax | Near zero; setup is configuration, not syntax learning |
| AI-code velocity compatibility | Limited by human authorship throughput | No human throughput ceiling; scales with codebase |
| Maintenance model | Manual review required for semantic changes | Fully automated via Diffs Agent |
| Pricing model | Per-user and per-execution pricing | Usage-based with free tier |
| Free tier | Trial period available | Functional free tier available |
The Right Choice Depends on Your Team Profile
Whether you frame it as TestRigor vs Autonoma or the other way around, both tools are genuinely codeless, but in different senses of the word.
TestRigor is codeless in that you do not write code. You write plain English. That is meaningfully different from Selenium, and the distinction matters for QA teams staffed by non-developers. If your organization has QA analysts who need to own test coverage without developer support, TestRigor's plain English paradigm gives them the authoring capability they need.
We designed Autonoma to be codeless in a more complete sense. You do not write anything. The test suite is derived from the codebase itself. If your goal is to eliminate the authorship step entirely, not just make it easier, that is the architectural difference we built around.
The profiles diverge clearly across a few key questions. If your QA team is non-technical and needs to own test authorship, TestRigor fits. If your team ships through AI coding tools at a pace where manual authorship creates coverage gaps, that is precisely the problem we built Autonoma to solve. If you need built-in email/SMS inbox testing as a core requirement, TestRigor's native support handles it cleanly. If you need coverage that grows automatically with every pull request without anyone scheduling authoring time, that is what we built the Planner agent to deliver.
The Verdict: Is Autonoma the Right TestRigor Alternative?
The plain English paradigm is elegant. TestRigor executed it well, and for the era it was designed for, it is a significant improvement over script-based testing. The problem is that "the era it was designed for" ended when AI coding tools arrived.
Test suites need to grow as fast as code does. Plain English scripts authored by humans cannot keep that pace. The throughput ceiling is a human QA analyst's working hours. AI-generated code does not operate within those hours.
That is why we built Autonoma the way we did. If you are evaluating us as a TestRigor alternative because your codebase is growing faster than your test suite, the codebase-first architecture is our direct answer to that gap. Connect your repo, let the Planner derive initial coverage, and see how quickly the suite reflects your actual application surface. Our free tier is functional enough to validate the architecture on a real codebase before any commitment.
TestRigor requires a human to write each test in plain English: describing clicks, inputs, and expected results in natural language that the AI interprets. Autonoma eliminates the authorship step entirely. The Planner agent reads your codebase and derives tests from your routes, components, and data models automatically. Both are codeless in the sense that no one writes test code, but TestRigor still requires someone to author test descriptions, while Autonoma generates them from the source.
Yes, TestRigor's plain English syntax is one of its clearest strengths. A QA analyst without developer experience can write productive tests in hours. If your team includes non-technical QA professionals who need to own a test library independently, TestRigor's authoring experience is designed for exactly that. Autonoma does not have an equivalent authoring interface because test creation is automated. The tradeoff is that Autonoma requires no authoring at all, while TestRigor makes authoring accessible to non-developers.
This is the core challenge. TestRigor's test creation throughput is bounded by how quickly a human can write plain English scripts. When AI coding tools are generating features significantly faster than manual development, the authorship bandwidth becomes a bottleneck. New features go untested until someone adds the corresponding plain English scripts. Autonoma's Planner agent has no such ceiling because it reads the code directly and derives coverage automatically, without a human writing speed constraint, and the Executor runs those tests against a live preview environment as soon as they exist.
TestRigor's approach is element-level resilience: it finds UI elements by their visible text and context rather than brittle CSS selectors, so surface-level UI changes (class renames, layout shifts) often do not break tests. Where it falls short is semantic changes: if a button's label changes, or a flow is restructured, the plain English description needs manual updating. Autonoma's Diffs Agent reads code diffs on every pull request and updates tests based on what changed in the source, which handles both selector-level and semantic changes automatically.
Yes, and this is a genuine TestRigor differentiator. Built-in inbox integration for email and SMS validation is native to the platform, which makes authentication flows (confirmation emails, OTP SMS) easier to test without custom tooling. Autonoma covers these flows through API and end-to-end testing, but TestRigor's native inbox support is more convenient for teams where email and SMS testing is a high-frequency need.
The core capability that TestRigor cannot replicate is automatic test generation from codebase analysis. When new features ship, Autonoma's Planner derives tests for them without any human authoring the test descriptions. Database state setup is also automated through the Planner's endpoint generation, removing a manual infrastructure step that TestRigor leaves to the team. And the Diffs Agent's code-diff-driven self-healing covers semantic changes that TestRigor's element-level resilience does not.
Autonoma fits this profile better. When developers are doing their own QA, the overhead of authoring plain English scripts in TestRigor adds time to an already-stretched workload. Autonoma's automated test generation means developers get coverage without an authoring step. Connect the repo, the Planner generates the initial suite, and the Diffs Agent keeps it current. For a small team where QA is a shared responsibility, eliminating the authorship overhead is more valuable than making authorship easier.
For teams that want to eliminate test authorship entirely rather than simplify it, yes. TestRigor makes writing tests easier. Autonoma makes writing tests unnecessary. If the primary driver is speed, if your codebase is growing faster than your QA bandwidth can track, or if your team does not have dedicated QA analysts to own plain English scripts, Autonoma is the stronger fit. The free tier lets you validate the architecture on your own codebase before committing.
TestRigor can test applications that contain AI-generated code, but it does not automatically adapt to the pace of AI-assisted development. When AI coding tools generate new features or refactor existing ones, someone still needs to write or update the corresponding plain English test scripts manually. The mismatch is not in capability but in throughput: TestRigor's test creation speed is limited by how fast a human can write scripts, which becomes a bottleneck when AI tools are generating code at significantly accelerated development velocity.
It depends on your team profile. If your QA team is non-technical and needs to own test authorship directly, TestRigor's plain English scripting is the most accessible codeless option. If your team uses AI coding tools and needs coverage that scales automatically without manual authorship, Autonoma's codebase-first approach eliminates the writing step entirely. For a comprehensive comparison across the full category, see our codeless test automation tools roundup.
TestRigor uses per-user and per-execution pricing. Exact costs depend on team size and test volume, and are available through their sales team. Autonoma uses usage-based pricing with a functional free tier that allows you to validate the architecture on a real codebase before any financial commitment. The cost comparison should factor in QA authorship time: TestRigor requires ongoing human effort to write and maintain tests, while Autonoma's automated generation eliminates that labor cost.



