
AI E2E testing (also called AI end-to-end testing) means using AI to write, run, or assert against browser-driven user-flow tests. The label hides six structurally different products that vendors and buyers routinely confuse: AI-assisted authoring (an AI writes test code that you maintain), autonomous codebase-first testing (an agent reads the codebase, owns the preview environment, the test data, and the replay loop), runtime-exploration tools (an agent crawls a deployed app for surface-level flows), natural-language spec executors (humans write and maintain plain-English specs that an agent runs), generated test pipelines (a tool produces Playwright workflows from observed traffic for the customer to review and own), and visual-AI assertions (a diffing layer on top of an existing E2E framework). Calling all of them "autonomous" is the marketing convenience that makes evaluations stall. Only the codebase-first category is genuinely autonomous end to end; the rest are better interfaces around human-owned test work.
The confusion is real and expensive. Teams evaluate Playwright with Copilot against Autonoma against Applitools as if they solve the same problem. They don't. We built Autonoma as the codebase-first autonomous implementation of AI E2E testing, and watching teams put it in the same evaluation bucket as runtime explorers, natural-language spec runners, and traffic-derived test generators is the single biggest reason evaluation cycles fail to reach a clear conclusion. This post draws the lines.
The six things people mean by "AI E2E testing"
The phrase "AI E2E testing" has become a catch-all. Every vendor in the QA space has added "AI-powered" to their homepage. Cutting through that requires a taxonomy with six categories at the same level, not a single "autonomous testing" umbrella with sub-flavors.
IDE co-pilots (Cursor, Copilot) sit inside AI-assisted authoring. Session recorders (Meticulous, Replay.io) are a tooling layer beneath any of the categories, not a category of their own.
| Category | Who writes the test | Who maintains it | Replaces existing E2E suite | Buyer profile |
|---|---|---|---|---|
| AI-assisted authoring | Developer with LLM assist | Developer | No (faster authoring on top) | Devs who own a Playwright suite |
| Codebase-first autonomous (Autonoma) | Agent reads the codebase | Agent re-derives on every PR; managed preview env and test data | Yes | Teams without a maintainable suite, vibe-coded apps |
| Runtime-exploration agents (qa.tech) | Agent crawls the deployed app | Agent re-explores; no per-PR diff awareness | Partial (surface flows only) | Teams that cannot or will not grant code access |
| Natural-language spec execution (Momentic) | Human writes plain-English specs | Agent retries the spec; humans maintain the spec list and environment | Partial | Dev teams that want to own the spec list |
| Generated Playwright workflows (Checksum) | Tool generates flows from observed traffic | Customer reviews and maintains the suite | Partial | Teams that want generated Playwright as a starting point |
| Visual-AI assertions | Developer or QA (existing framework) | Developer or QA | No (assertion layer on top) | Visual-consistency-critical teams |
AI-assisted authoring (Cursor, Copilot, Claude + Playwright)
AI-assisted authoring is the use of an LLM-powered editor or copilot to generate Playwright or Cypress test code that a developer reviews, commits, and maintains.
Here, the AI is a writer. You open your editor, describe what you want to test, and an LLM generates Playwright or Cypress code. You review it, fix the selectors, commit the file, and own it from that point forward.
This is not meaningfully different from writing tests yourself. The bottleneck in E2E testing was never "can I type fast enough?" It was "who reads the entire codebase to know which flows to cover?" and "who keeps the test suite passing when the UI changes next sprint?" AI-assisted authoring does not answer either question. It writes the first draft of your future maintenance burden. You still own everything that makes E2E testing expensive.
The buyers here are developers who already know Playwright and want to skip the boilerplate. It is a productivity gain, not a structural shift in how testing works. If you close your editor, the tests stop being written.
Autonomous codebase-first testing (Autonoma)
This is the only category in the taxonomy that is genuinely autonomous end to end. A codebase-first platform reads the application source on every PR (routes, API handlers, component trees, data models, auth flows) and derives the test plan, the database state each scenario needs, the preview environment to run against, and the replay schedule from the code itself.
Autonoma is the example we built. The Planner agent generates the plan from the codebase. A managed preview environment is provisioned per PR, including seeded test data via the Environment Factory SDK. The Generation agent executes the plan against that environment by intent rather than selector. The Replay agent runs the full accumulated suite on every PR so regression coverage compounds. The Reviewer agent classifies failures as real regressions or environmental noise and posts findings to the PR.
The defining property: the codebase is the spec, and the vendor owns the lifecycle. There is no human-maintained list of natural-language test descriptions, no recording session, no customer-built preview environment, and no customer-managed seed data. When the UI or data model changes, the next run re-derives from the new code state. This is the category that autonomous testing describes in full.
Autonoma's four-stage pipeline:
- Planner. Reads the codebase and derives the test plan, including the database state each scenario requires.
- Generation. Executes the plan against the managed preview environment, navigating by intent rather than selector.
- Replay. Re-runs the full suite on every PR so regression coverage accumulates rather than resets.
- Reviewer. Classifies failures as real regressions or environmental noise and posts findings to the PR.
Runtime-exploration tools (qa.tech)
Runtime-exploration tools crawl a deployed application and infer flows by navigating the UI. They do not read the codebase. Conceptually they sit closer to a smarter session recorder than to an autonomous testing platform: the agent observes the surface of a running deploy and produces coverage on what it can reach.
The advantage is that integration is light. You point it at a staging URL and the agent starts mapping pages and actions, without granting code access. The limitations are structural. Code paths gated by state, permissions, feature flags, or seeded data the agent cannot create stay invisible. There is no per-PR diff awareness because the agent never sees the code change that just landed, and the customer still owns the staging environment the agent runs against.
This is a convenient surface crawler, not an end-to-end autonomous testing platform. It can click through the app you point it at; it cannot understand the code change, seed the state it needs, or know which hidden flows the UI never exposed. Lumping it together with codebase-first testing collapses the difference between "the agent knows what changed and what data the scenario needs" and "the agent clicks around the staging deploy you are already running."
Natural-language spec execution (Momentic)
Natural-language spec executors take test cases that humans write in plain English and run them with an LLM-driven browser agent. Momentic's agentic AI actions are stronger than literal click recording because the agent re-derives how to satisfy a step when the UI shifts.
This category is not autonomous testing. The customer authors every spec, decides which flows to cover, maintains the spec list as the app evolves, and supplies the environment the agent runs against (Momentic documents the environment requirements the customer is responsible for). What you get is a more resilient test runner. The QA function (deciding what to test, writing it down, keeping the environment and data ready) stays with your team.
Generated test pipelines (Checksum)
Generated test pipelines observe production or staging traffic and produce automated test flows (typically Playwright) for the customer to review and adopt. The output is a generated test suite plus a managed pipeline to run it.
This is closer to "AI-generated authoring at scale" than to "an agent owning the lifecycle." Coverage is shaped by what the system has observed in traffic, not by reading the codebase, and ongoing maintenance still depends on the customer's environment, review cadence, and decisions about which generated flows to keep. Calling this autonomous testing without that asterisk is the kind of framing that makes buyers think they are evaluating Autonoma when they are not.
Visual-AI assertions (Applitools, Percy, Chromatic)
Visual-AI assertions are AI-powered visual diffing layers that flag meaningful visual regressions inside an existing E2E framework, ignoring rendering noise like anti-aliasing and font shifts.
Here, AI is the assertion engine, not the runner. You still write your own E2E test scripts. At specific checkpoints in those scripts, Applitools captures a screenshot and compares it against a baseline using a model trained to ignore rendering noise while catching real visual regressions.
The AI component is sophisticated and genuinely useful. But the test still has to exist. Someone still writes the Selenium or WebDriver script that drives the browser to the right state. The coverage problem is yours. The visual assertion is theirs.
The buyers are teams with mature E2E suites who are drowning in false positives from pixel-level diffing tools, or teams where visual consistency is the primary regression risk (design systems, heavily branded checkout flows).
Why the disambiguation matters when buying
Mixing these categories in an evaluation leads to apples-to-oranges verdicts. A team evaluating Applitools as an alternative to Autonoma will find Applitools "cheaper per test" because it does not write the tests. A team evaluating Copilot as an alternative to agentic E2E testing will find Copilot "more flexible" because it lets you write anything, ignoring that "anything" means "you maintain everything."
The right framing: decide first what problem you are solving.
If the problem is "we have a good Playwright suite but our visual assertions have too many false positives," visual-AI assertions are the answer. The codebase-first, runtime-exploration, and natural-language categories are not.
If the problem is "we do not have a meaningful E2E suite, the codebase changes weekly, and we do not have time to build or maintain one," autonomous codebase-first testing is the answer. Runtime exploration tools, natural-language spec executors, and traffic-derived test generators all leave a meaningful chunk of the lifecycle (environment, data, spec list, scope decisions) with your team.
If the problem is "we want developers to write tests faster in Playwright," AI-assisted authoring is the answer. Nothing else in the taxonomy is built for that.
Where teams get confused is the middle case: they have a partial Playwright suite, it is brittle, it takes engineering time to maintain, and coverage is below 40%. That is the case where autonomous codebase-first testing replaces something that was never really working, rather than replacing a healthy existing suite. It is also the case where natural-language spec runners and runtime explorers make the team feel productive without removing the maintenance burden.
Another confusion pattern: teams evaluate price per test. Visual-AI assertion tools can look cheap because they are incomplete: the expensive part, writing and maintaining the tests that reach the visual checkpoint, is still yours. Autonomous codebase-first testing only looks expensive if you ignore the engineering time currently spent writing, debugging, and maintaining test code, plus the preview-environment and seed-data infrastructure other categories expect you to keep running.
The strongest signal that a team is in the wrong category is when they describe their evaluation as "which tool writes better Playwright tests." That framing collapses every category into one. It treats test authoring as the only variable, ignoring who manages the environment, who maintains the data state, who decides what to cover, and who evaluates results when a PR fails at 2 AM.
The right question to start with is simpler: does your team currently have and maintain a working E2E suite? If yes, you are in the market for improvements to that suite (visual assertions, better selectors, faster runs). If no, or if the suite exists but nobody trusts it, you are in the market for a replacement model, not a better toolset on top of a broken one. If the suite exists but nobody trusts it, stop shopping for a nicer tool on top of the same broken operating model. You are in the market for a replacement model.
A concrete AI E2E run, end to end
Let me walk through what actually happens when Autonoma runs on a PR. This is not a marketing description. This is the four-stage pipeline.
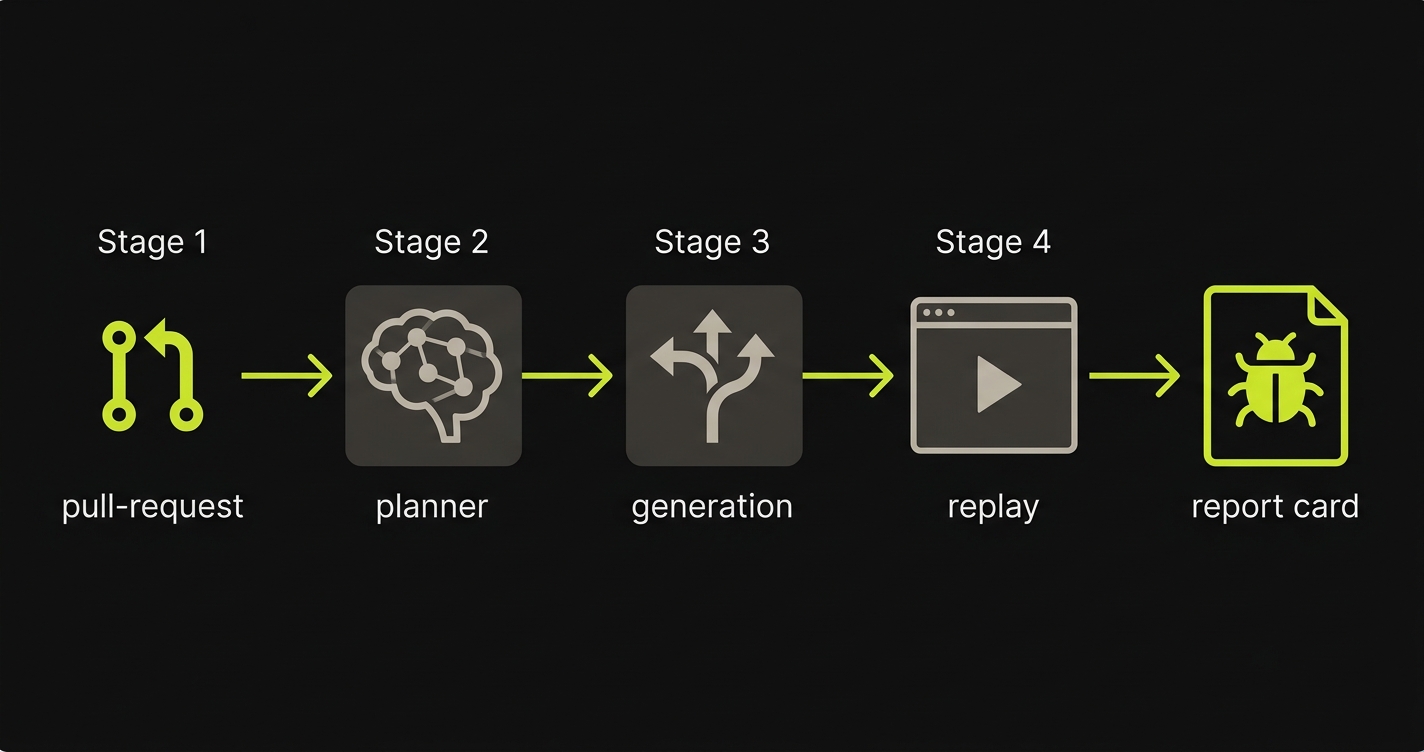
A developer opens a PR. The changed files are diffed against the previous state. Autonoma's pipeline starts automatically.
Stage 1: Planner. The Planner agent reads the codebase: routes, API handlers, React component trees, database models, authentication flows. It produces a structured test plan that covers the flows most likely to be affected by the changeset. It also identifies what database state each test scenario requires and generates the endpoints needed to put the database in that state.
Stage 2: Generation. The Generation agent executes the test plan against the PR's preview environment. It navigates the app by intent, not by selector. It fills forms, triggers transitions, and validates that the expected state is reached. If a UI element has moved or been renamed, the agent re-derives how to reach it.
Stage 3: Replay. The Replay agent runs the full suite against the changeset, not just the new flows. Regression coverage from previous PRs gets replayed. If something that worked in the last build now fails, Replay surfaces it.
Stage 4: Reviewer. The Reviewer agent evaluates all results. It distinguishes between a genuine regression (the checkout button does not submit the form) and environmental noise (a third-party widget took 200ms longer than usual). Real failures post back to the PR as a comment with reproduction details. Noise is filtered.
The total time from PR open to results posted is measured in minutes, not hours. No human writes or reviews test code. If the PR is clean, the agent reports that. If there is a real bug, the agent reports that with enough detail for the developer to fix it without context-switching to a QA backlog.
This is what automated E2E testing looks like when the agent owns the full lifecycle.
How Autonoma covers AI E2E testing
The pain point we built against is specific: teams that ship faster than they can write tests. When developers use Cursor or Claude to write features in hours, the test-writing bottleneck is no longer a minor inconvenience. It becomes the thing that blocks safe deployment. You cannot hand off "write 30 new E2E tests for this PR" to an LLM in your editor because the tests it writes will break on the next PR.
Autonoma's architecture solves this by separating test intent from test implementation. The codebase holds the intent (routes, components, flows). Our agents derive the tests from that intent on every run. There is no test artifact to maintain. When the code changes, the next run re-derives from the new codebase state.
The four stages work together as a verification pipeline, not as independent scripts. The Planner's DB-state handling feeds the Generation agent so flows that require authenticated state or seeded data work without manual fixture setup. The Replay agent preserves coverage from previous runs so regression risk accumulates rather than resets each sprint. The Reviewer agent learns over time which patterns in your app tend to produce environmental noise, reducing false positive rates as the suite matures. Each stage includes internal verification layers so agents do not take random paths through the app.
We designed this specifically for the teams shipping AI-generated code: companies using Cursor, Bolt, or v0 at production scale where the code volume is high and the test-writing capacity does not scale with it. For those teams, autonomous codebase-first testing paired with the right tooling is the only approach that keeps up.
How the AI E2E testing platforms compare in 2026
The table below covers the six platforms most commonly evaluated in this space. The columns reflect the questions we hear most often from teams doing evaluations.
| Tool | Generates coverage from | Owns preview env + test data per PR | Re-derives on UI change | No human-maintained spec list |
|---|---|---|---|---|
| Autonoma | Codebase | ✓ (managed + Environment Factory SDK) | ✓ (per-PR re-derivation) | ✓ |
| qa.tech | Runtime exploration | ✗ (customer-owned env) | Partial | ✓ |
| Momentic | Human-written NL specs | ✗ (customer-owned) | Partial | ✗ |
| Checksum | Observed traffic, generated Playwright | ✗ | Partial | Partial |
| QA Wolf | Human engineers (managed service) | ✓ (managed) | Human-reviewed | ✗ (staffed service) |
| Mabl | Low-code recorder | ✗ | Selector heal only | ✗ |
| Applitools | N/A (assertion only) | ✗ | Visual diff only | ✗ |
The columns capture the parts of the lifecycle a vendor actually owns. Most "AI testing" tools sell test execution. Autonoma is the only entry that owns codebase-first plan derivation, the per-PR preview environment, seeded test data and database state, the replay loop across PRs, and false-positive review as one integrated platform. The rest leave one or more of those pieces for the customer to wire up. For a deeper side-by-side evaluation across more dimensions including pricing, OSS support, and team profile fit, see AI testing platforms compared.
What AI E2E testing still can't do
The boundary is human judgment, not test maintenance. Autonoma does not replace product sense, exploratory judgment, or business rules that exist nowhere in the code. It replaces the repeatable E2E labor teams keep pretending they have time to maintain.
Honest accounting matters here. Autonomous codebase-first testing does not replace all human judgment in a QA process.
It does not define your acceptance criteria. The Planner derives flows from your codebase, but it cannot know that "the checkout button must stay green on the confirmation screen" unless that constraint exists in the code somewhere. Purely business-rule validation that is never expressed in code is still a gap.
It does not replace exploratory testing. Agents follow derivable paths. Creative adversarial testing, edge cases that emerge from real-world user behavior, accessibility nuances that require contextual understanding: these remain human territory.
It does not audit third-party integrations independently. If your Stripe integration changes behavior because Stripe's API changed, the agent will surface that as a test failure, but it cannot interrogate Stripe's changelog to explain why.
These gaps are real. They are also narrower than most critics assume. The 80% of regression testing that is deterministic, flow-based, and codebase-derivable is exactly what autonomous codebase-first testing covers. The remaining 20% is where humans remain essential. The mistake is using the 20% as a reason to avoid the 80%.
Where AI E2E testing is heading
The six categories will continue to diverge, not converge. AI-assisted authoring will get better at generating idiomatic, maintainable Playwright code for developers who want to own their test suite. Visual-AI assertions will get better at structural and semantic diffing, moving beyond pixel comparison toward understanding what a UI is supposed to communicate. Runtime explorers will get better at navigating dynamic apps but will keep hitting the same ceiling of state, permissions, and seeded data they cannot create. Natural-language spec executors will keep improving at the execution layer while the customer keeps owning the spec list, environment, and data underneath. Generated-test pipelines will keep producing more Playwright code for customers to review and maintain.
Autonomous codebase-first testing is on a different trajectory. As codebases increasingly contain AI-generated code, the assumption that a human has read and understood every flow before writing a test, set up the environment, and seeded the data becomes untenable. A platform that owns the codebase-derived plan, the preview environment, the test data, the replay loop, and the false-positive triage is the only one that can read a 50,000-line codebase changed by Cursor in 48 hours and produce meaningful regression coverage the same day. Vibe coding and autonomous codebase-first testing are converging: the agent that writes the code and the platform that tests it operate as a paired system, with verification happening continuously rather than at review time.
The teams that get ahead are the ones that recognize this shift now and stop treating "AI E2E testing" as a single purchase decision. Know which category your current problem lives in, and buy the tool built for that category. For the broader landscape of E2E testing tools (including frameworks and platforms outside the AI category), the category-level overview goes deeper.
Frequently asked questions
For teams in the AI-assisted authoring category, no: Playwright is still the underlying runner and AI just helps write the scripts faster. For teams adopting autonomous codebase-first testing, yes, in the sense that you no longer write or maintain Playwright scripts. The agent generates and replays flows without you authoring test files. Playwright may or may not be the underlying browser automation layer depending on the vendor, but that detail is invisible to your team. Note that runtime-exploration tools, natural-language spec executors, and traffic-derived test generators do not eliminate Playwright maintenance the same way: in those products, either a human still owns the spec list or the customer still owns the generated test code.
Only autonomous codebase-first testing actually does this. A Planner agent reads your codebase (routes, components, API definitions, database models) and derives the test plan without human input. The codebase is the spec. AI-assisted authoring in an editor can reference codebase context, but it still requires a human to prompt it, review the output, and commit the result. Runtime-exploration tools (like qa.tech) infer flows from a deployed app rather than from code, so they cannot reason about code paths gated by state, permissions, or seeded data. Natural-language spec executors (like Momentic) and traffic-derived test generators (like Checksum) do not derive coverage from the codebase at all.
The flakiness risk depends on the approach. AI-assisted authoring produces Playwright tests with the same flakiness profile as any hand-written Playwright test: selector brittleness, timing issues, environment-specific failures. Agent-based products vary widely. Systems without verification layers can take inconsistent paths through the app, which introduces flakiness. Agent systems that include verification at each step produce deterministic paths. A Reviewer agent that distinguishes environmental noise from real failures reduces the effective false-positive rate even when environmental conditions vary. Runtime-exploration tools that crawl a shared staging environment inherit whatever state and noise that environment carries. Natural-language spec executors and traffic-derived generators also depend on the customer-managed environment they run against.
Yes, but only the autonomous codebase-first category is architecturally designed for it. Autonoma triggers on every PR open or push event, runs against a managed preview environment provisioned for that PR, and posts results back to the PR comment before merge. Runtime-exploration tools can run on a schedule against a shared staging deploy but have no per-PR diff awareness. Natural-language spec executors and traffic-derived generators run when the customer wires them into CI, against an environment the customer manages. Keeping tests that run only on release branches or staging deploys is exactly the pattern autonomous codebase-first testing replaces.
AI-assisted test writing is one of six categories of AI E2E testing, not a synonym for it. AI-assisted writing uses an LLM in your editor to generate Playwright or Cypress code that you then commit and maintain. The other categories are autonomous codebase-first testing (an agent owns the test plan, the preview environment, the test data, and the replay loop), runtime-exploration tools (an agent crawls a deployed app for surface-level flows), natural-language spec execution (humans write and maintain plain-English specs that an agent runs), generated test pipelines (a tool produces Playwright workflows from observed traffic for the customer to own), and visual-AI assertions (a diffing layer on top of an existing E2E framework). Calling all of those autonomous is the marketing convenience this article is built to undo.
Cursor is an AI-assisted authoring tool, which is one of the six categories of AI E2E testing. It can help a developer write Playwright or Cypress tests faster by generating a first draft from a natural-language description. It does not run those tests, manage the environment, manage the data, maintain the suite when the UI changes, or evaluate results. Cursor pairs with an autonomous codebase-first platform or a managed-service vendor when teams want a complete E2E loop. Treating Cursor as a complete AI E2E testing platform is the category error this article is built around.
There is no single best tool because the categories solve different problems, and the agentic camp itself is not one thing. For teams shipping AI-generated code at high velocity with no maintained test suite, codebase-first autonomous platforms like Autonoma are the best fit because the test plan, preview environment, test data, and replay loop are all derived from the codebase on every PR. Runtime-exploration tools like qa.tech autonomously crawl the running app but cannot reason about code paths gated behind state or permissions. Natural-language spec executors like Momentic still require humans to write and maintain a spec list and to own the environment and data setup. AI-assisted authoring tools (Cursor, Copilot) are the answer for teams with a healthy Playwright suite who want faster authoring. Visual-AI assertions (Applitools, Percy, Chromatic) layer on top of an existing suite for teams whose primary risk is visual regression. Treating all autonomous-sounding tools as interchangeable is the most common evaluation mistake.



