
An autonomous testing platform derives E2E tests directly from your codebase using a multi-agent pipeline, executes them against isolated environments per pull request, and keeps them passing as your code evolves, with no human scripting, no locator glue, and no QA team required.
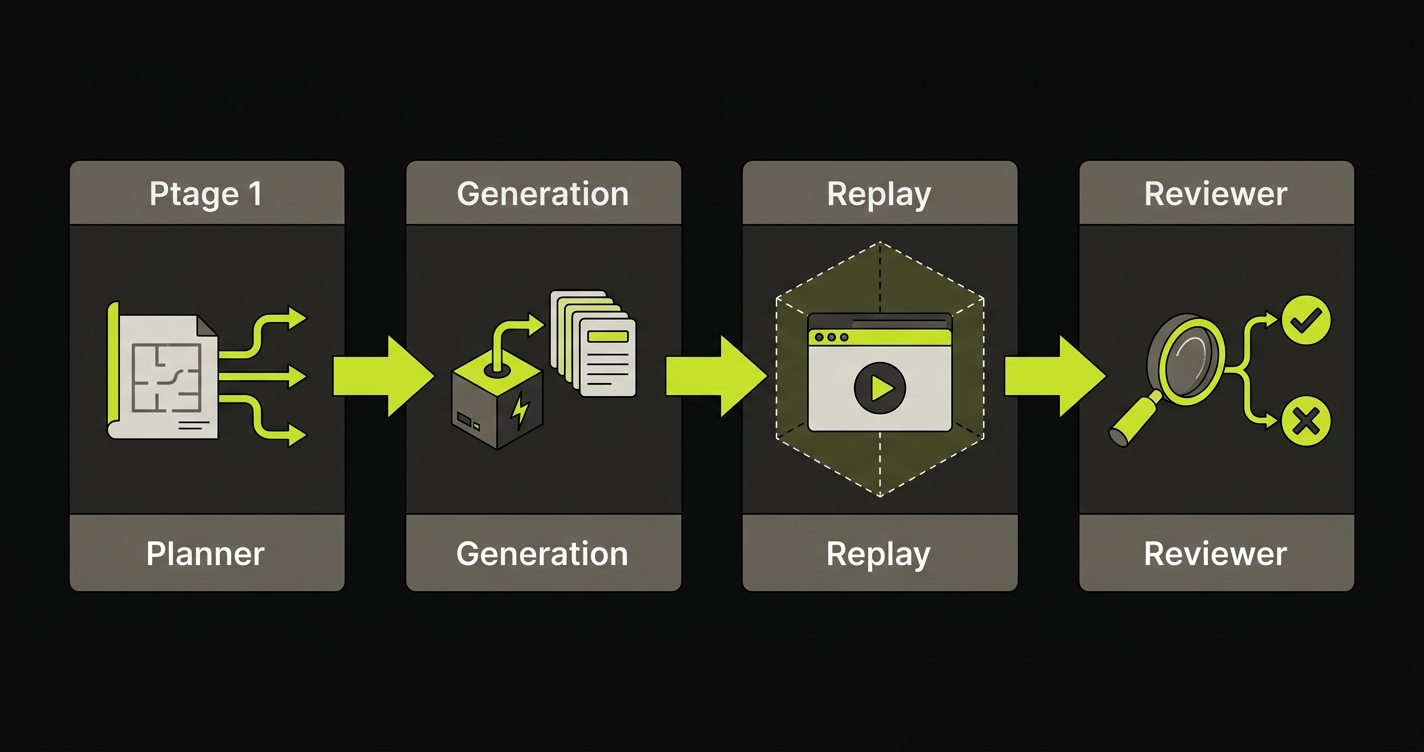
Autonoma is the working answer we built. It is a four-stage pipeline of Planning, Generation, Replay, and Review that runs on top of managed preview environments per pull request. Each stage is handled by a specialized agent. No stage requires a human to intervene. The codebase is the spec, and the agents read it.
That framing might sound familiar if you have followed the autonomous testing conversation over the past two years. The term has been claimed by a long list of tools, most of which are UI recorders with a thin AI layer on top. Before this article explains what we actually built, it is worth being precise about what the category means and where different tools actually land.
What "autonomous testing" means in 2026
The term "autonomous testing" has been stretched to cover five meaningfully different things. Using the same label for all of them obscures the engineering decisions that matter.
Think of testing maturity as a five-tier taxonomy: Manual, Scripted, AI-assisted, Autonomous, and Agentic. Each tier has a distinct mechanism, a distinct failure mode, and a distinct suitability for teams with different constraints.
Manual testing is a human clicking through the application. Coverage is bounded by the tester's time and knowledge. For teams shipping daily with an AI coding agent, a human cannot click fast enough to keep up with the surface area being generated.
Scripted testing is Selenium, Playwright, Cypress. A developer writes test scripts once and runs them in CI. Coverage is good when the scripts were written recently. The failure mode is maintenance: every UI change potentially breaks the selectors, and scripts written against a UI that was designed by a human become actively hostile toward a UI that is continuously rewritten by an AI.
AI-assisted testing is where most vendors currently sit. Mabl, Testim, and testRigor let you record a flow or write a test in plain language, and their AI layer adds resilient locator selection, some form of visual diffing, and suggestions for missing coverage. These tools meaningfully reduce the manual scripting burden, but they still require a human to define which flows matter. The AI assists; it does not plan. This is an important distinction.
Autonomous testing removes the human from the planning and scripting loop entirely. The system decides which flows to test based on what the application does, generates the test cases without a human specifying them, and executes them without a human watching. Autonomy is not a feature, it is a structural property: the system can operate end-to-end without human direction.
Agentic testing is the frontier tier. Agentic E2E means independent agents with distinct roles perceiving their environment, making decisions, taking actions, and adapting based on what they observe. The difference from autonomous testing is the degree of independence and specialization. Each agent has a bounded responsibility and a verification layer. The system does not just run without humans; it runs with the judgment required to handle the non-determinism of real applications.
Most tools in market today operate at the AI-assisted tier. Autonoma operates at the agentic tier. That claim deserves a concrete explanation, which is what the next section provides.
The four-stage pipeline that actually does the work
When a pull request opens against a repository connected to Autonoma, a four-stage pipeline runs. Here is what each stage does.
Planner
The Planner reads the codebase. It maps routes, analyzes component hierarchies, traces user flows through the application graph, and constructs a coverage strategy. This is not a static analysis pass in the traditional compiler sense. The Planner is deriving intent from structure: what is this application designed to let a user do?
The Planner also handles database state setup, which is where most autonomous testing approaches break silently. Testing a checkout flow requires the database to contain a user with items in their cart. The Planner generates the API calls needed to put the database in that state before the test runs. No fixture files. No manual seed scripts. No test data spreadsheets that go stale.
Generation agent
The Generation agent takes the Planner's coverage strategy and produces test cases. These are not test scripts in the Playwright sense. They are structured representations of flows, expected behaviors, and verification checkpoints derived from the Planner's understanding of the codebase.
The Generation agent does not record you clicking through the application. It does not ask you to describe the flow in natural language. Your codebase already contains the description. The Generation agent reads it.
Replay engine
The Replay engine executes test cases against the running application inside a managed preview environment provisioned per pull request. Each PR gets its own isolated full-stack runtime, so a test failure is unambiguous: it is this change, on this branch, not something a colleague's unmerged feature introduced into a shared staging environment.
The Replay engine includes verification layers at each step. It does not take random paths. It derives expected interaction sequences from the Generation agent's output and verifies behavior against the Planner's expected state. This is what makes the system consistent rather than probabilistic.
Reviewer
The Reviewer classifies results. A test failure can mean two different things: the application behavior is wrong (a regression), or the application structure changed in a way that requires the test to be updated (implementation drift). Treating both as failures produces noise. Treating both as acceptable produces false confidence.
The Reviewer distinguishes between them. Behavioral regressions are surfaced as blocking failures. Implementation drift triggers intent re-derivation, where the Reviewer works with the Planner to update the test case to reflect the new structure, then verifies that the behavioral expectation is still met. This is what self-healing test automation looks like when it is done with intent rather than heuristic locator fallback.
Comparison: where the named tools land
The five-tier taxonomy maps to market tools differently than vendor marketing suggests. Here is an honest placement.
| Tool | Works without a QA team | Tests AI-generated apps | Self-heal mechanism | Time-to-first-coverage |
|---|---|---|---|---|
| Autonoma | Yes. No test scripts needed. | Yes. Reads the codebase directly. | Intent re-derivation. Replans from code. | Minutes after codebase connection. |
| Mabl | Partially. Needs flow recording. | Partially. Breaks on structural rewrites. | Locator weighting and fallback. | Hours. Requires manual flow setup. |
| Testim | Partially. Needs flow recording. | Partially. Selectors break on AI rewrites. | Heuristic locator stabilization. | Hours. Requires manual test authoring. |
| QA Wolf | No. Requires human QA engineers. | Partially. Engineers write tests per PR. | Manual update by their QA team. | Days. Human-written per feature. |
| testRigor | Partially. Needs natural language spec. | Partially. Spec must be written first. | Locator-free, but spec must be maintained. | Hours. Requires plain-language authoring. |
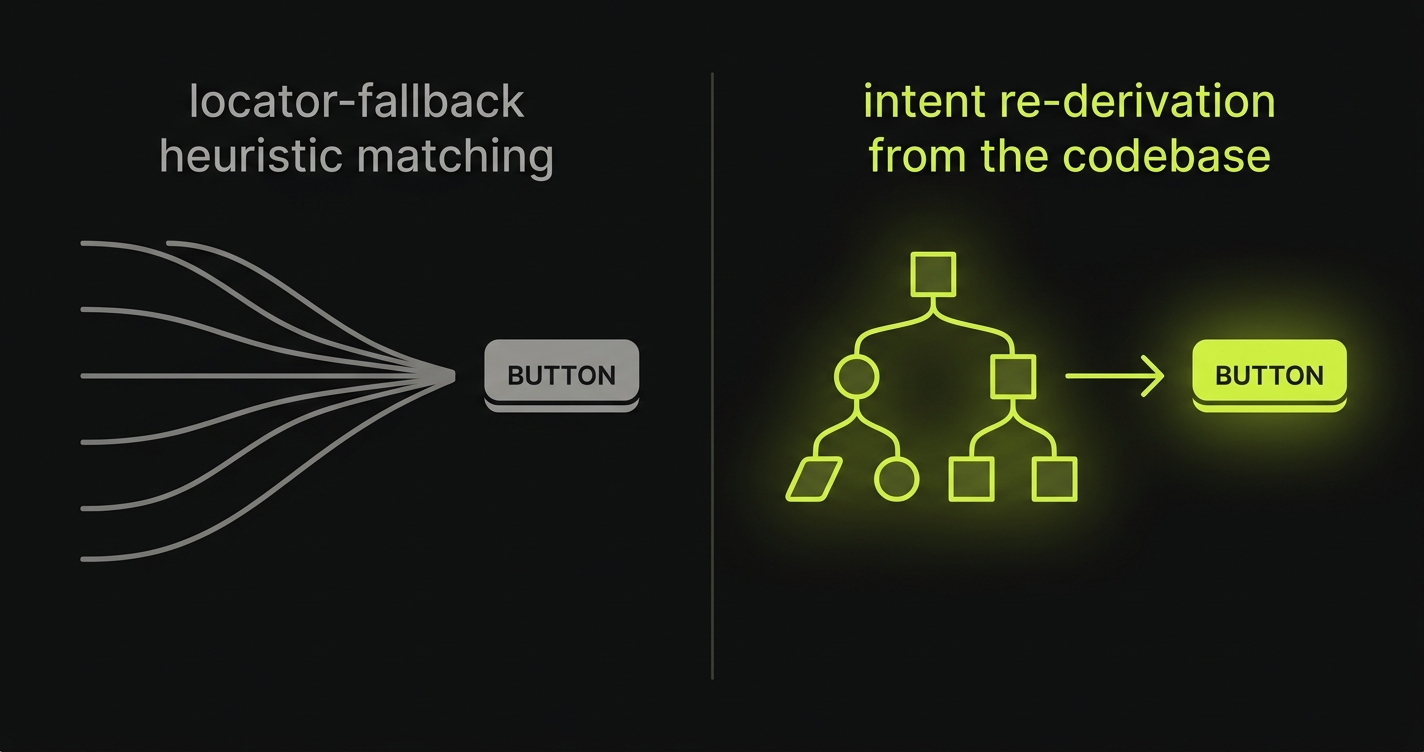
The discriminating column is self-heal mechanism. Locator weighting means the tool tries multiple ways to find the same element when a selector breaks. It is effective for minor UI tweaks. It breaks when a component is restructured or removed, because there is no selector that resolves. Intent re-derivation means the Planner re-reads the codebase and reconstructs which element serves the same functional role in the updated application. It works on structural rewrites because it was never attached to a specific selector in the first place.
Self-healing: the honest version
Self-healing is one of the most over-claimed capabilities in the testing tool market. The honest version requires a precise answer to two questions: what should heal silently, and what should not?
The answer to what should heal silently is narrow: implementation changes with no behavioral impact. A button moved from the left side of a form to the right. A class name changed for styling reasons. An element given a new test ID. These are selector-level changes that do not affect what the application does. If a test fails on these, it is the test that is wrong, not the application. Healing is correct.
The answer to what should never heal silently is equally clear: behavioral changes. A payment flow that now skips the confirmation step. An email field that no longer validates format. A route that redirects where it used to render. If these cause a test failure, that failure is a signal. Silencing it defeats the purpose of having tests.
Locator-weighting self-heal, used by Mabl and Testim, is good at the first category. It struggles with the second because it operates at the selector level. It does not have a model of what the application is supposed to do. It only knows whether it found the element.
Intent re-derivation operates at the behavioral level. The Reviewer identifies that a test is failing, sends the failure context and the updated codebase to the Planner, and the Planner determines whether the failure represents a structural change to the application or a behavioral regression. If structural: the test is updated, the behavior is re-verified, and the PR passes. If behavioral: the failure is surfaced to the developer as a blocking issue. The distinction is not heuristic. It is derived from the same code model that produced the original test.
How Autonoma covers autonomous testing
In practice, this is what happens when a developer on a team without a dedicated QA function opens a pull request.
The PR triggers a managed preview environment. That environment is a full-stack isolated runtime: the same services, same database schema, same environment variables as production, running in isolation. The Planner reads the diff and the surrounding codebase. It identifies which flows are affected by the change and derives the test scenarios required to verify them. The Generation agent produces the test cases. The Replay engine executes them inside the preview environment, where every failure is attributable to this branch and nothing else. The Reviewer classifies results and either surfaces regressions or triggers intent re-derivation for structural changes.
All of this runs without a QA engineer specifying what to test. No locator glue. No test scripts. No fixture setup. The developer opens the PR, the pipeline runs, and they get back a result: the affected flows pass, or a specific behavioral regression was found.
This is what the automated E2E testing category is moving toward. The managed preview environment is the execution substrate, and the four-stage pipeline is the intelligence layer on top of it. Neither works without the other. A four-stage pipeline with no isolated environment produces tests that fail for reasons unrelated to the change being reviewed. An isolated environment with no autonomous pipeline still requires a human to write the tests.
The combination is what we call an autonomous testing platform: the infrastructure and the intelligence working together, triggered by the developer workflow, with no human in the loop between PR open and test result.
Who autonomous testing is built for
The five-tier taxonomy resolves into two clear audiences for autonomous testing in 2026. Both share a structural characteristic: the testing surface is growing faster than a human can test it.
Teams without QA are the first audience. Engineering-only organizations, early-stage startups, small product teams where every engineer is shipping features. These teams have historically operated without formal testing because setting up and maintaining a test suite requires time they do not have. An autonomous testing platform is the only architecture that provides meaningful E2E coverage to a team in this situation, because it does not require anyone to write tests, maintain tests, or understand testing frameworks. The codebase is the input and coverage is the output.
Teams shipping AI-generated code are the second audience, and the one the category was genuinely rebuilt to serve. When a developer uses an AI coding agent to ship features, the code surface can change substantially in a single session. Traditional test maintenance models assume a human wrote the code and another human can inspect the changes to update tests accordingly. Neither assumption holds in an AI-generated codebase. The Planner reads the new structure directly, derives what changed, and updates coverage accordingly. The symmetry is complete: AI generates the code, the autonomous testing platform generates and maintains the tests.
These two audiences overlap more than they diverge. Most teams shipping AI-generated code are also teams without dedicated QA. The autonomous testing platform is the single architectural answer to both constraints.
What autonomous testing won't do
Category precision requires honesty about scope. An autonomous testing platform covers the E2E behavioral layer. It is not a substitute for:
Unit testing remains a developer responsibility. The autonomous testing platform verifies that user flows produce the right behavioral outcomes. It does not verify that individual functions return correct values for edge-case inputs. These are different tests for different purposes.
API contract testing is a distinct layer. Verifying that your API adheres to a published contract, or that a downstream service receives the correct request shape, requires dedicated tooling. An autonomous testing platform exercises the API indirectly through the application flows it tests, but it is not a Postman replacement.
Load and performance testing is a separate discipline. The pipeline tests functional correctness under normal conditions. It does not simulate concurrent users or measure latency under load.
Security testing requires specialized scanners. The pipeline does not attempt to enumerate attack vectors or verify authentication bypass conditions.
Being precise about what the platform does not cover is not a weakness. It is a prerequisite for using it correctly. Teams that deploy an autonomous testing platform get behavioral E2E coverage without the overhead of scripting and maintaining it. That is a meaningful constraint lifted. The other testing disciplines remain, and they should.
FAQ
Yes, with precision about what 'autonomous' means. If the claim is that a platform can record flows for you or stabilize selectors without human help, that has been real for several years. If the claim is that a platform can derive which flows to test from your codebase without any human specification, generate test cases, execute them in isolated environments, and maintain them as the code changes, that is also real in 2026. Autonoma does the second thing. Most tools on the market do the first thing. The distinction matters because the first does not help teams without QA, and the second does.
It replaces the scripting, execution, and maintenance work that occupied most of what a QA engineer's time went toward in a traditional web application team. It does not replace QA judgment about what constitutes acceptable product behavior, how to handle edge cases that the application was not designed for, or how to communicate quality risks to stakeholders. Teams without QA get meaningful E2E coverage without hiring. Teams with QA get their QA engineers back for the work that requires human judgment rather than script maintenance.
Selenium and Playwright are browser automation frameworks. They do not decide what to test, generate test cases, or maintain themselves when your code changes. Someone has to write the scripts, run them, debug them when selectors break, and update them when flows change. An autonomous testing platform does all of those things. You connect your codebase and get coverage back. The underlying execution layer may use browser automation internally, but the engineering burden that frameworks impose on the developer is removed.
Yes. AI-generated code is the primary use case we rebuilt the category to serve. The platform reads your codebase, not a test script someone wrote before the code was generated. When an AI coding agent rewrites a component, the Planner re-reads the updated structure and derives what changed. Coverage updates to reflect the new code. There is no stale test suite to debug and no selectors written against a previous UI version to fix. The symmetry is structural: AI generates the code, the autonomous testing platform generates and maintains the tests.
Self-healing works correctly only when the system can distinguish between implementation drift and behavioral regression. Implementation drift is a selector-level change with no behavioral impact: a class name changed, an element moved, a test ID updated. This should heal silently. A behavioral regression is a change that affects what the application does: a flow that now skips a step, a field that no longer validates, a route that redirects incorrectly. This should never heal silently. Tools that heal by heuristic locator weighting are good at the first category and blind to the second. Intent re-derivation handles both correctly because it operates from a model of what the application is supposed to do, not from a model of where an element lives in the DOM.



