
Autonoma vs QA Wolf is a comparison between two fundamentally different models for eliminating the test-writing burden. QA Wolf is a managed QA testing service: a team of human QA engineers writes, runs, and maintains your tests on your behalf. Autonoma is an AI platform: agents read your codebase, generate tests automatically, and self-heal them as your code changes. Both remove the authorship burden from your developers. Only one scales when AI coding tools make your dev team 10x faster. If you are searching for a QA Wolf alternative or evaluating QA automation tools for a team shipping at AI velocity, this comparison covers model, cost at scale, speed, and coverage in full.
Teams using AI coding tools are reporting something that sounds like a recruiting problem but is actually a QA problem. Feature output has increased significantly per engineer. The engineering headcount stays flat. The test suite does not keep up.
That gap, between how fast code ships and how fast test coverage can be written and maintained, is where most QA automation tools decisions are actually made. Not in a planned evaluation, but under pressure, when a sprint ends and the test suite is three features behind.
QA Wolf closes that gap with human engineers. Autonoma closes it with agents that read your codebase directly. Both work. The difference is what happens to cost and speed as the gap keeps widening, which, for teams adopting AI coding tools, it will.
The Fundamental Model Difference
This is not a features comparison. The difference between these two tools is architectural, and understanding it determines which one fits your situation.
QA Wolf is a managed QA testing service. Their platform now includes AI agents (a Mapping Agent that explores your application and an Automation Agent that converts prompts into Playwright code), which make their human QA team faster at creating and maintaining tests. But the model is still fundamentally managed: a dedicated team of QA engineers uses these AI tools on your behalf, and the throughput of coverage is still bounded by that team's capacity. When new features ship, their engineers write new tests. When your app changes, their engineers update them. The AI makes them faster. It does not remove them from the loop.
Autonoma is AI-as-a-platform for testing. You connect your codebase. Four specialized agents handle the rest. The Planner agent reads your routes, components, and data models, derives test cases from that analysis, and generates the API endpoints needed to set the database into the right state for each test. The Diffs Agent runs on every pull request, reading code diffs to add, deprecate, and maintain test cases as your application evolves. The Executor agent runs the planned tests against a live preview environment, and the Reviewer agent classifies each result as a real bug, an agent error, or a test-plan mismatch.
The human is not in either loop except to review results.
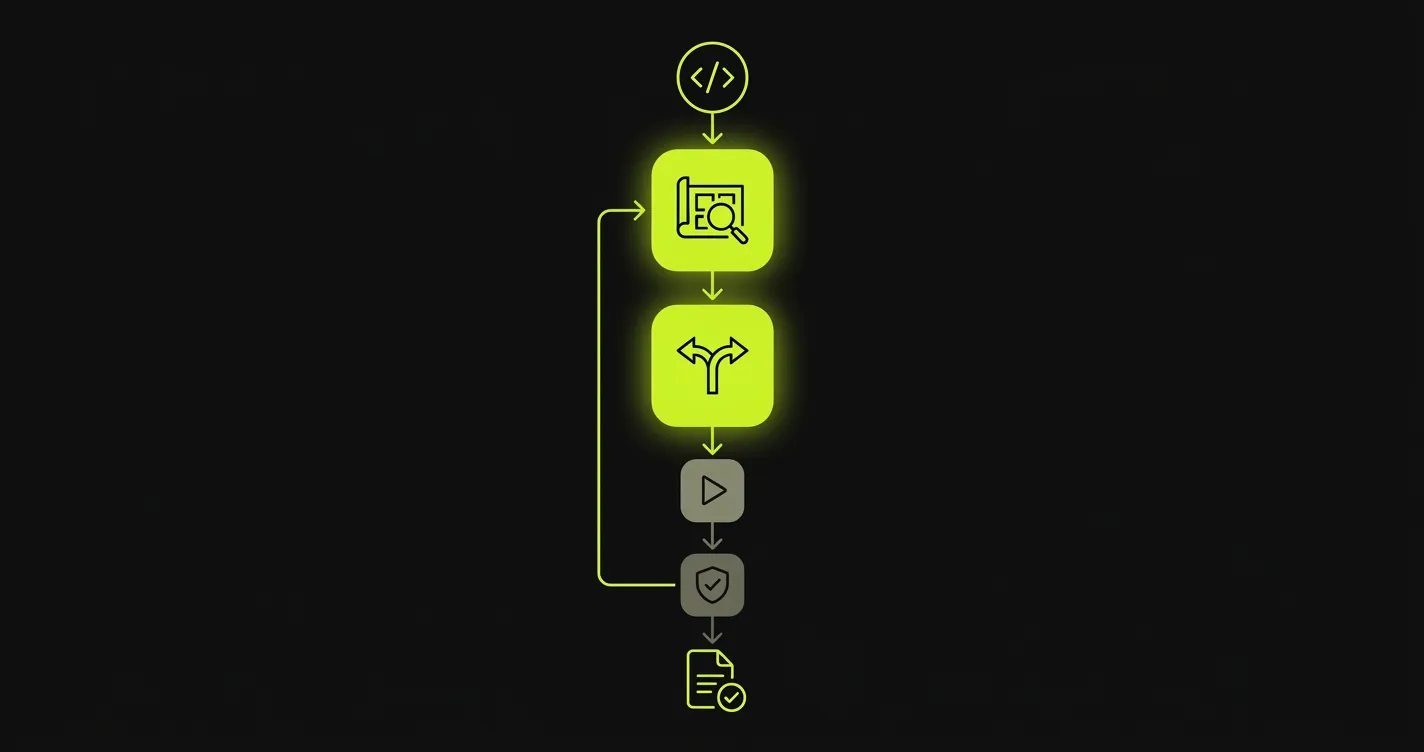
Planner and the Diffs Agent drive test creation and maintenance; Executor and Reviewer run and classify results, feeding back into the loop.
This distinction matters more than any feature checklist. If coverage quality requires human judgment, then coverage speed is limited by human throughput. If coverage quality comes from code analysis, it scales with code.
Cost at Scale
QA Wolf does not publish official pricing, but publicly reported data across G2, Vendr, and competitor analyses (as of early 2026) puts the cost at roughly $40-44 per test per month, with a median annual contract value around $90K. Volume discounts and custom enterprise negotiations are common and would reduce the per-test rate at scale. The model is straightforward: you are paying for human labor, infrastructure, and the QA Wolf platform layer on top. As your test suite grows, the human labor component grows with it. More tests mean more engineers maintaining them. More complex flows mean more specialist time.
Autonoma's cost scales with platform usage, not headcount. The Diffs Agent handles a test suite of 500 tests with the same infrastructure overhead as 50. There is no additional human team to staff.
The cost curves diverge significantly at scale.
| Test Suite Size | QA Wolf (Estimated) | Autonoma |
|---|---|---|
| 50 tests | ~$2,000-2,200/mo ($40-44/test) | Free tier or low-cost starter plan |
| 200 tests | ~$8,000-8,800/mo ($40-44/test) | Growth plan; cost grows with usage, not test count |
| 500 tests | ~$20,000-22,000/mo ($40-44/test) | Scale plan; same infrastructure, more agent runs |
| 1,000 tests | ~$40,000-44,000/mo ($40-44/test) | Enterprise plan; cost does not scale 1:1 with test count |
These estimates apply a linear per-test rate. Volume discounts and custom contract negotiations are common at scale and would reduce these figures. Contact QA Wolf directly for current pricing.
These QA Wolf estimates are based on publicly reported per-test pricing from G2, Vendr, and competitor analyses. QA Wolf does not publish official pricing, and enterprise contracts may vary. The pattern holds regardless of exact numbers: managed human QA is labor-intensive, and labor costs scale linearly. Technology costs scale logarithmically or not at all.
For a team at 50 tests, QA Wolf's cost is defensible. The hands-off experience has clear value. At 500 tests, the cost equation looks different. At 1,000 tests, it becomes a significant line item that buys slower turnaround than an AI platform can deliver.
The manual vs automated testing cost analysis goes deeper on this cost curve and why the crossover point has moved as AI coding tools change how fast codebases grow.
Speed: Where the Model Difference Becomes Concrete
The speed comparison has three distinct dimensions, and they tell different stories.
| Speed Dimension | QA Wolf | Autonoma |
|---|---|---|
| Time to create a new test | Hours to days; engineer reviews, writes, validates | Minutes; Planner derives tests on commit |
| Time to update when code changes | Hours; manual diff review and rewrite | Near-instant; Diffs Agent auto-updates from diff |
| Test execution time | Fast; parallel Playwright execution | Fast; parallel execution with verification layers |
| Coverage for 10 new features | Days to a week; depends on team queue | Hours; Planner reads all new routes simultaneously |
| Handling 50 PRs in a week | Backlog risk; bounded by human throughput | No ceiling; Diffs Agent processes all diffs in parallel |
Execution speed is where QA Wolf holds up well. Their infrastructure runs Playwright tests in parallel at scale, and the actual runtime of tests is not bottlenecked by human engineers. Where human speed becomes relevant is in the before and after: writing new tests for new features, and updating tests when existing features change.
For a team shipping one or two features per week, QA Wolf's turnaround on new tests is acceptable. For a team using AI coding tools to ship ten features per week, it starts to crack. The QA Wolf team queue cannot absorb that volume at the same pace the codebase is changing.
Coverage: Human Judgment vs AI Breadth
This is where QA Wolf has a genuine, defensible advantage that deserves an honest assessment.
Human QA engineers bring context that code analysis does not automatically capture. They know that a particular user type performs a particular sequence that looks unusual from the code but is common in practice. They catch edge cases that emerge from human behavior rather than from the technical specification. They understand business logic nuances that may be buried in comments or tribal knowledge rather than surfaced clearly in route definitions.
QA Wolf's engineers write tests with this judgment applied. The tests reflect not just what the code does but what a thoughtful QA professional believes could go wrong in production.
Autonoma's Planner agent derives tests from what is in the codebase. The Planner handles complex scenario setup automatically, including generating the API endpoints needed to put the database in the right state for each test. It covers breadth efficiently. What it does not bring is human intuition about what users actually do versus what the code says they can do.
The coverage tradeoff in practice looks like this.

QA Wolf catches the subtle, judgment-dependent edge cases that require knowing how your users behave. Autonoma catches everything the codebase describes, across more scenarios and more states than a human team would realistically author in the same time window.
For most teams, the bigger coverage risk is not the judgment-dependent edge case. It is the ten new features that shipped this sprint and have no test coverage at all because the QA Wolf team's queue is backed up. Autonoma covers those ten features immediately.
When Your Dev Team Operates at AI Velocity
This is the question that makes the comparison concrete for 2026.
AI coding tools have changed the throughput equation for engineering teams. A developer using Cursor, Claude, or GitHub Copilot ships features at a meaningfully higher rate than one writing code manually. A small team with AI assistance has the output of a team several times its size.
The QA bottleneck this creates is structural. If your dev team triples its output, and you are using a managed QA service whose throughput is bounded by human engineers, the coverage gap grows every sprint. The service is not broken; it simply cannot scale faster than its team can scale.
This is not a hypothetical. Teams using AI coding tools are already experiencing this. They ship more than their QA processes can absorb. The backlog of untested features grows. Coverage debt accumulates. The QA bottleneck problem is not unique to teams evaluating managed services; it affects every organization where testing throughput has not kept pace with AI-accelerated development. Eventually they face a choice: slow down the dev velocity or accept coverage gaps.
Autonoma was built for the third option. The Planner and Diffs Agent have no human throughput ceiling. As a codebase grows, the agents scale with it. As pull requests accumulate, the Diffs Agent processes diffs without a queue. Coverage does not degrade as velocity increases.
For a fuller look at how AI testing tools differ across architectures, the AI testing tools definitive guide compares 20+ tools across categories including managed services, AI-native platforms, and hybrid approaches.
Where QA Wolf Excels
This comparison would be misleading without an honest account of where QA Wolf is the right choice.
80% automated E2E test coverage in four months is a concrete commitment that QA Wolf makes to customers. That guarantee removes evaluation risk and gives engineering leads a number to bring to a budget conversation. The question for teams at AI velocity is not whether 80% coverage is achievable but whether it remains at 80% as the codebase doubles in size over the next year.
True hands-off operation for the customer is QA Wolf's strongest selling point. When you engage QA Wolf, you are not connecting a repo and reviewing agent outputs. You are delegating the entire QA function to a team of professionals. For a founding team or early-stage startup where QA is a distraction from product work, that delegation has real value.
Human judgment on complex, behavior-dependent flows is where QA Wolf's engineers add value that code analysis alone cannot replicate. If your application has flows where what users actually do diverges significantly from what the code technically allows, QA Wolf engineers bring the contextual understanding to test those real-world paths.
Established Playwright infrastructure means QA Wolf tests run in a mature, battle-tested execution environment. Their infrastructure handles parallelism, reporting, and CI/CD integration without your team needing to configure it.
Accountability and communication comes with a human team. When something is unclear about a test failure or a coverage gap, you have a QA Wolf contact to ask. The AI platform model requires your team to interpret outputs independently.
QA Wolf is a well-run service that solves a real problem for teams in a specific situation: no QA headcount, no desire to build a testing infrastructure, and a development velocity that human engineers can track.
Where Autonoma Excels
Autonoma is the stronger fit as soon as the scaling question enters the picture.
Automatic test generation from code means coverage exists from the moment code is committed, not after a QA team reviews and authors tests. A new feature merged on Tuesday has tests before Tuesday ends. A team shipping 50 PRs a week gets coverage for all 50, not for however many the QA queue can absorb.
Self-healing through the Diffs Agent means test suites do not accumulate maintenance debt. When a component is refactored, the Diffs Agent reads the diff and updates the relevant tests from the source of truth, not from a fragile selector. When a flow is restructured, the Diffs Agent re-derives the test logic from the updated routes. Maintenance does not require a human to review every code change.
Database state handling through the Planner agent removes a step that managed QA services typically require manual coordination on. The Planner generates the endpoints needed to put the database in the right state for each test scenario automatically. No seed scripts, no manual setup documentation handed to a QA team.
Developer workflow integration fits teams where testing is not a separate function. Terminal triggers, PR-level analysis, and IDE integration mean testing happens in the same context as development. For teams without a dedicated QA function, this keeps quality work in the developer's natural workflow.
Cost at scale makes Autonoma increasingly attractive as codebases grow. The cost structure does not have a human labor component that scales linearly with test suite size.
For a comparison with a different category of AI-native testing tool, the Autonoma vs TestRigor comparison covers how AI-native test generation differs from plain English scripting, which is yet another model for eliminating traditional test authorship.
Full Feature Comparison
| Capability | QA Wolf | Autonoma |
|---|---|---|
| Test creation model | Human QA engineers write Playwright tests (AI-assisted) | Planner agent derives tests from codebase automatically |
| New feature coverage | QA team authors tests; turnaround in hours to days | Automatic; Planner reads new code on commit |
| Test maintenance | QA engineers review and update manually | Diffs Agent self-heals from code diffs |
| Database state setup | Requires coordination with QA team or manual seed scripts | Planner generates setup endpoints automatically |
| Human judgment in coverage | Yes; engineers apply contextual knowledge | No; coverage derived from code analysis |
| AI-velocity compatibility | Bounded by human team throughput | No throughput ceiling; scales with codebase |
| Self-healing | AI-assisted; Automation Agent helps engineers update faster | Fully automated; Diffs Agent reads diffs and updates |
| Execution framework | Playwright | AI-driven with verification layers per step |
| CI/CD integration | GitHub Actions, standard CI pipelines | GitHub Actions, GitLab CI, terminal/IDE triggers |
| Pricing model | Managed service contract; scales with complexity | Usage-based; does not scale 1:1 with test count |
| Hands-off for customer | Fully; you delegate to QA Wolf team | Fully; you review agent outputs, not write tests |
| Accountability model | Human team; direct communication channel | Platform; outputs require internal interpretation |
| Best fit | Teams delegating QA entirely; stable dev velocity | Teams at AI velocity; scaling without QA headcount |
The Right Choice for Your Team
The honest answer is that QA Wolf and Autonoma are not competing for exactly the same customer.
A team in the early stages, with a relatively small codebase, a manageable feature velocity, and zero appetite to think about testing infrastructure, might genuinely be better served by delegating to QA Wolf's engineers. The hands-off experience is real, the coverage has human judgment behind it, and the cost at that scale is defensible.
A team shipping features at AI velocity, with a codebase growing faster than any human team can track, is in a different situation. The QA bottleneck will return regardless of which managed service they use. Managed services are bounded by their headcount. Headcount does not scale as fast as AI-assisted feature velocity.
Autonoma was built for that second team. The Planner and Diffs Agent, backed by the Executor and Reviewer, exist because keeping up with AI-generated code requires a system that also operates without human throughput limits. Connect your codebase, let the Planner derive initial coverage, and the suite grows with your codebase rather than waiting for a QA team queue to clear.
If you are evaluating this because your current QA setup, whether internal, managed, or manual, cannot keep pace with your development velocity, the free tier is functional enough to run Autonoma against a real codebase and see whether the Planner's coverage matches your expectations before any commitment. For teams evaluating open-source options specifically, the open-source alternative to QA Wolf comparison covers self-hosted deployment and source-available licensing in detail.
QA Wolf is a managed QA testing service that employs human QA engineers to write, run, and maintain Playwright tests on your behalf. Autonoma is an AI-native testing platform where agents read your codebase and generate tests automatically, with no human authoring involved. QA Wolf's coverage reflects human engineering judgment. Autonoma's coverage is derived from code analysis. Both remove the authorship burden from your developers, but they take opposite approaches: QA Wolf delegates the work to human engineers, Autonoma eliminates the human authoring step through AI agents.
For teams at an early stage with manageable feature velocity and no QA headcount, QA Wolf's managed service provides genuine value. You get professional test coverage without hiring or building infrastructure. The cost becomes harder to justify as the codebase scales, because managed human QA services have labor costs that grow with test suite size and complexity. If your team is shipping at AI coding tool velocity (10+ features per week per developer), the QA Wolf team may not be able to keep pace regardless of the budget, because the bottleneck is human throughput, not willingness to spend.
QA Wolf assigns human engineers to review code changes and update affected tests manually. When your application changes, their team has to identify which tests are affected, rewrite them, and validate. Autonoma's Diffs Agent reads code diffs directly and updates tests from the source of truth. When a component is refactored or a flow is restructured, the Diffs Agent derives updated test logic from the changed code automatically. No human review cycle is needed. For teams shipping multiple PRs per day, this difference in maintenance speed is significant.
This is the core tension. AI coding tools allow small engineering teams to ship at rates that previously required much larger teams. QA Wolf's capacity to write and maintain tests is bounded by their engineering headcount. When your dev team ships 50 PRs in a week via AI coding agents, QA Wolf needs proportionally more of their engineering time to cover it. Autonoma's Planner and Diffs Agent have no such ceiling. They read all new code and all diffs without a queue. Coverage scales with code output, not with human team capacity.
Not completely. QA Wolf engineers bring contextual knowledge about how users actually behave, which may differ from what the code technically allows. They catch edge cases that emerge from real-world usage patterns rather than from technical specifications. Autonoma's Planner derives coverage from what is in the codebase. For teams where the bigger risk is not the subtle behavior-dependent edge case but rather the ten new features that have no test coverage because no one has had time to write tests yet, Autonoma addresses the larger gap. The judgment-based edge cases are valuable, but coverage breadth at scale is usually the more pressing problem.
Human QA engineers review the change, identify affected tests, rewrite them, and validate the updated tests. For teams that ship infrequently, this is manageable. For teams with continuous deployment or high PR volume, the review and update cycle creates a lag between when code ships and when test coverage reflects the new state of the application. During that lag, regressions can reach production undetected. Autonoma's Diffs Agent processes diffs in near real-time, so the test suite reflects code changes without a human review cycle introducing delay.
Yes, especially if your team is small and growing quickly. QA Wolf's value proposition is strong when you want to delegate testing entirely to a managed team without thinking about it. But startups using AI coding tools often hit the velocity ceiling fast: your team ships faster than QA Wolf can keep up, and coverage gaps accumulate. Autonoma lets you scale coverage with your codebase without a proportional increase in QA cost. The free tier is a practical starting point for validating coverage on your actual codebase before committing.
With QA Wolf, database state for complex test scenarios typically requires coordination between your team and the QA engineers, often through seed scripts or documentation about the required state. Autonoma's Planner agent handles this automatically. It generates the API endpoints needed to put the database in the right state for each test scenario, without manual seed scripts or setup documentation. This is one of the less visible but practically significant differences for teams whose tests require specific data states.



