
AI testing tools are software platforms that use artificial intelligence to generate, execute, maintain, or analyze automated tests. The category spans everything from open-source frameworks like Playwright (no AI, but the industry foundation) to fully autonomous platforms that read your codebase and generate tests without any human input. This guide covers 20+ tools across 6 categories, scored on AI capabilities, test creation speed, maintenance burden, CI/CD integration, pricing accessibility, and compatibility with AI-generated code. It is the reference page for engineering teams evaluating ai software testing options in 2026.
The testing market is fragmented in a way that makes evaluation genuinely hard. You can spend two weeks running your own ai testing tools comparison and still not know which one fits your team. Every vendor in the ai software testing space claims to use AI. "AI-powered," "AI-assisted," "AI-augmented" all mean different things, and none of them tell you what actually matters: does this tool keep up when your team ships code faster than a human QA engineer can write tests?
That is the real question in 2026. Cursor, Claude, Copilot, and every other AI coding tool has changed the pace of code output permanently. Your test coverage strategy has to keep up with that pace, or you are shipping blind. Most testing tools were built for a world where humans wrote code, humans wrote tests, and QA was a gate at the end of the sprint. That world no longer exists for most teams.
This guide is the reference we wish existed when we started building Autonoma. We cover every major category, score each tool honestly, and tell you which team profile each tool actually fits. For deeper dives, each section links to standalone comparisons.
What Are AI Testing Tools?
AI testing tools are software platforms that apply machine learning, natural language processing, or autonomous agents to one or more phases of the testing lifecycle: test creation, execution, maintenance, or failure analysis. The category is broad enough to include tools that do very different things under the same label.
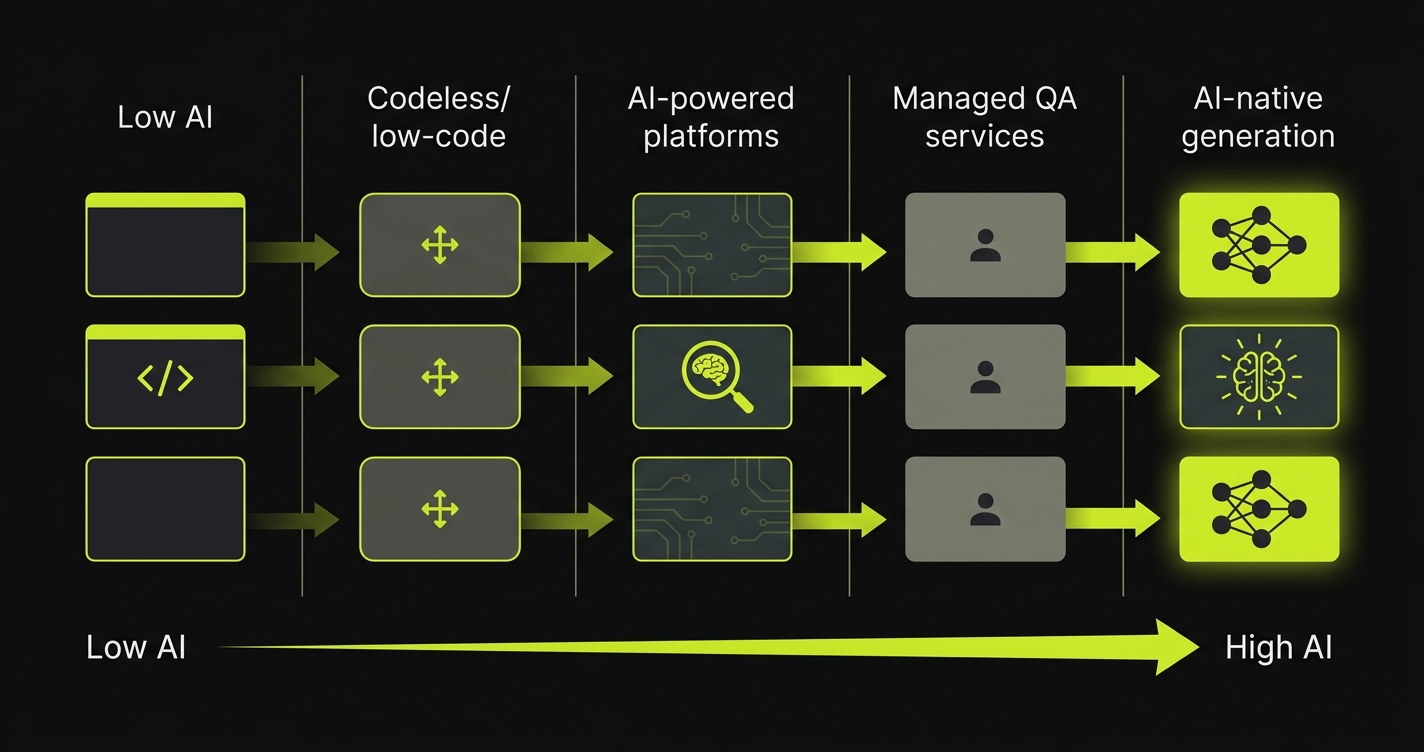
At the simplest end, some tools use ML to stabilize element selectors so tests survive minor UI changes. That is AI-assisted maintenance. At the most advanced end, autonomous platforms analyze your codebase, derive test cases from routes and components, generate the test scripts, execute them, and self-heal when the code changes. That is AI-native test generation. Between those poles sit platforms that use natural language interfaces for test authorship, visual AI for regression detection, and ML for result analysis.
The distinction matters because "ai testing tools" as a search term returns products that span the entire range. A team looking for ai software testing that eliminates manual test authorship will get frustrated evaluating a tool that only stabilizes selectors. The category taxonomy in this guide separates these approaches so you can evaluate tools against what you actually need.
How to Read the Scoring
Every tool in this ai testing tools comparison is scored 1-5 on six dimensions. Here is what each one means.
AI capabilities measures how much the tool actually uses AI versus labeling a rule-based system as "AI." A 5 means the tool uses AI to generate tests from scratch, self-heal when code changes, and analyze failures intelligently. A 1 means the AI is cosmetic.
Test creation speed measures how long it takes to get meaningful coverage from zero. A 5 means hours, not weeks. A 1 means you are hand-authoring every test.
Maintenance burden measures how much ongoing work tests require after code changes. A 5 means tests update themselves. A 1 means every UI change breaks dozens of tests and someone has to fix them manually.
CI/CD integration measures how cleanly the tool fits into a modern pipeline. A 5 means native integration with GitHub Actions, GitLab CI, and similar; detailed failure reports; and no friction. A 1 means bolt-on integrations that require manual setup.
Pricing accessibility measures whether the tool is usable by a lean team. A 5 means open source or a free tier that covers real use cases. A 1 means enterprise-only pricing that requires a sales call.
AI-code compatibility measures how well the tool handles code generated by AI tools (Cursor, Claude, Copilot). This is distinct from AI capabilities: a tool can use AI internally but still be blind to what makes AI-generated code different. A 5 means the tool was built with AI-generated codebases in mind.
AI Testing Tools: The Master Scoring Matrix
Disclosure: Autonoma is the publisher of this guide. We scored all tools, including our own, using the criteria defined above. We encourage readers to validate these assessments against their own evaluations.
| Tool | AI | Creation | Maintenance | CI/CD | Pricing | AI-Code |
|---|---|---|---|---|---|---|
| Autonoma AI-Native Generation | 5 | 4 | 5 | 4 | 4 | 5 |
| Momentic AI-Native Generation | 4 | 4 | 4 | 4 | 3 | 3 |
| Testim AI-Native Generation | 3 | 3 | 3 | 4 | 2 | 3 |
| Mabl AI-Powered Platform | 3 | 3 | 3 | 4 | 2 | 2 |
| TestSigma AI-Powered Platform | 3 | 3 | 3 | 4 | 3 | 2 |
| Katalon AI-Powered Platform | 3 | 3 | 3 | 4 | 3 | 2 |
| Functionize AI-Powered Platform | 3 | 3 | 3 | 3 | 2 | 2 |
| BrowserStack Testing Infrastructure | 2 | 2 | 2 | 5 | 3 | 3 |
| LambdaTest Testing Infrastructure | 2 | 2 | 2 | 5 | 4 | 3 |
| Sauce Labs Testing Infrastructure | 2 | 2 | 2 | 5 | 2 | 3 |
| QA Wolf Managed QA Service | 3 | 4 | 4 | 4 | 1 | 3 |
| RainforestQA Managed QA Service | 2 | 3 | 3 | 3 | 1 | 2 |
| TestRigor Codeless / Low-Code | 3 | 4 | 3 | 4 | 3 | 2 |
| Leapwork Codeless / Low-Code | 2 | 3 | 2 | 3 | 2 | 2 |
| Playwright Open-Source Framework | 1 | 2 | 2 | 5 | 5 | 4 |
| Cypress Open-Source Framework | 1 | 2 | 2 | 5 | 5 | 3 |
| Selenium Open-Source Framework | 1 | 1 | 1 | 4 | 5 | 2 |
| Puppeteer Open-Source Framework | 1 | 2 | 2 | 4 | 5 | 3 |
Category 1: AI-Native Test Generation
This is the newest and most consequential category of ai test generation tools. These tools do not just assist with testing; they generate tests autonomously. The distinction matters enormously when your team is shipping AI-written code at pace.
Autonoma
Autonoma is the tool we built to solve a specific problem: AI coding tools generate code faster than any QA team can write tests for it. The architecture reflects that premise directly. You connect your codebase, and four specialized agents take over. The Planner agent reads your routes, components, and data models to derive test cases from the code itself (the codebase is the spec), generating the endpoints needed to set database state along the way. The Diffs Agent runs on every PR, adding, deprecating, and maintaining test cases automatically as your code changes, so nobody has to rewrite selectors or update flows by hand. The Executor agent runs the planned tests against a live preview environment, and the Reviewer agent classifies each result as a real bug, an agent error, or a test-plan mismatch.
What makes Autonoma distinct for AI-first teams is that it was built assuming the code changes constantly and unpredictably, which is exactly what happens when AI tools are involved in development. Self-healing is not an add-on feature: it is foundational to how the Diffs Agent works. The Planner agent also handles database state setup automatically, generating the endpoints needed to put the DB in the right state for each test scenario, which is typically where agentic test runners break down.
For a detailed comparison against the closest alternative, see Autonoma vs Momentic.
Momentic
Momentic is a strong second in this category. It offers AI-assisted test creation through a no-code visual editor, and its self-healing is genuinely good at keeping tests stable through UI changes. The core architectural difference is the source of truth: Momentic requires a human to author or record the test flow, then AI helps maintain it. Codebase-driven tools derive tests without human authorship at all.
For teams that want control over which flows get tested and prefer a visual interface for test creation, Momentic is a credible choice. For teams shipping AI-generated code at volume where new routes and components appear frequently, the authorship bottleneck resurfaces quickly. The full breakdown is in our Momentic comparison.
Testim (Tricentis)
Testim introduced AI-powered self-healing to the testing space before most other tools. It predates the current AI coding wave, and that shows in its architecture: it was built to help QA teams maintain existing test scripts, not to generate new ones from codebases. After Tricentis acquired Testim, the focus shifted toward enterprise workflow and process features. The AI capabilities are solid for locator stability but limited on the generation side. Pricing is enterprise-tier, which makes it hard to evaluate without a sales conversation.
For teams already in the Tricentis ecosystem (Tosca, qTest), Testim fits naturally. For greenfield teams evaluating ai testing tools today, there are stronger starting points.
Category 2: AI-Powered Testing Platforms
This category includes platforms that use AI as a layer on top of traditional testing workflows: record-and-playback with AI stabilization, natural language test authoring, and AI-assisted result analysis. These are not the same as AI-native generation, but they represent a meaningful upgrade over pure manual scripting.
Mabl
Mabl is one of the most polished tools in this category. It combines a low-code test recorder with ML-based self-healing and good CI/CD integration. The test creation experience is smoother than most competitors: you record flows, Mabl's AI stabilizes selectors, and tests generally stay green through minor UI changes.
The limitations surface at scale. Mabl still requires human authors for each test flow, which means coverage scales linearly with the time your team invests in recording. On an AI-first team where new features ship faster than any QA engineer can record them, this creates a gap. Pricing sits at the premium end of the market. For the full head-to-head, see Autonoma vs Mabl.
TestSigma
TestSigma occupies an interesting position: it offers natural language test authoring (describe a test in plain English, and the platform generates the steps) alongside a traditional recorder. The natural language interface lowers the barrier for non-engineers to author tests. For teams with dedicated QA resources who want to involve product managers or designers in test authorship, this is genuinely useful.
The AI-code compatibility score reflects that TestSigma was not designed with AI-generated codebases in mind. It handles testing well, but the natural language authorship model still requires a human to specify what to test, which is the same bottleneck in a different form.
Katalon
Katalon is one of the most feature-complete platforms in this category, covering web, mobile, API, and desktop testing under one roof. It has AI-assisted test generation, self-healing, and visual testing built in. For enterprise teams that need a single platform across many testing types, Katalon's breadth is hard to match at its price point.
The tradeoff is complexity. Katalon has a steep learning curve compared to newer AI-native tools, and the AI features feel bolted on rather than architectural. It appears in both this category and the codeless/low-code category because it genuinely spans both; the scripting and codeless modes serve different users within the same organization.
Functionize
Functionize uses ML to generate test cases from natural language descriptions and self-heal through application changes. It was ahead of its time when it launched and pioneered several concepts that are now standard across the category. The platform has matured but has been slower than newer entrants to adopt the fully agentic architecture that defines the current leading edge. Pricing and support are enterprise-focused, and the sales process reflects that.
Category 3: Testing Infrastructure
Infrastructure tools are not AI testing tools in the generative sense. They provide the cloud browsers, devices, and execution environments where tests run. They are essential, but they solve a different problem: where tests run, not what tests exist or whether they stay current.
BrowserStack
BrowserStack is the infrastructure standard. If you need to run tests across real browsers, operating systems, and physical mobile devices, BrowserStack is the most complete option available. The device farm is unmatched. CI/CD integration is excellent. The AI capabilities score (2/5) reflects that BrowserStack does not generate or maintain tests; it executes tests you already have.
The important nuance: BrowserStack is complementary to AI-native generation tools, not competing with them. Teams often use a generation layer to create and maintain tests, then run them on BrowserStack for cross-browser and real-device coverage. For how that pairing works in practice, see Autonoma vs BrowserStack.
LambdaTest
LambdaTest is the strongest alternative to BrowserStack in the infrastructure category. It offers competitive pricing, a large real device cloud, and has been adding AI features (KaneAI, its AI testing agent) to differentiate. The AI addition is meaningful but still earlier-stage than the tools in Category 1. For teams that find BrowserStack's pricing prohibitive, LambdaTest provides comparable infrastructure at a lower cost. The BrowserStack vs LambdaTest comparison covers the infrastructure decision in detail.
Sauce Labs
Sauce Labs was one of the original cloud testing infrastructure providers and built much of the tooling the industry still relies on. It has strong enterprise credentials, good compliance features (SOC 2, GDPR), and a mature CI/CD integration story. It lags BrowserStack and LambdaTest on pricing accessibility and the speed of AI feature addition. The primary use case today is teams with existing Sauce Labs infrastructure or enterprise compliance requirements that make switching costly.
Category 4: Managed QA Services
Managed services are a fundamentally different model: you pay for QA coverage rather than for a tool. A team of human (or AI-augmented human) testers maintains and runs your test suite for you. This trades control for convenience, and the economics only work at certain team sizes.
QA Wolf
QA Wolf is the most interesting entry in this category because it is trying to be a hybrid: a managed service backed by AI-generated Playwright tests. The pitch is that they write and maintain E2E tests for you, and those tests are real code you own. Coverage SLAs (80% E2E coverage, guaranteed) make the value proposition concrete.
The limitation is cost and control. QA Wolf starts at a price point that is hard to justify for teams under 20-30 engineers, and the managed model means you are dependent on their team's understanding of your application. For the full breakdown, see Autonoma vs QA Wolf. The shift-left testing implications of managed services are also worth understanding before committing.
RainforestQA
RainforestQA uses a crowdsourced testing model augmented with AI, where human testers run test cases on demand against your application. The model provides genuine human judgment on UI and UX issues that automated tools miss. The AI-code compatibility score (2/5) reflects that RainforestQA was built for a pre-AI-coding world where human QA bandwidth was the primary constraint. It does not scale to the volume of changes AI-first teams generate.
Category 5: Codeless and Low-Code Testing
Codeless tools lower the barrier to test creation by removing the need to write code. The promise is that anyone on the team can author tests. In practice, the no-code interface often constrains what you can test and creates a different kind of maintenance burden when tests need to handle complex flows.
TestRigor
TestRigor uses plain English test descriptions: you write "click the login button and enter the password" and it generates the automation. The accessibility is genuine; non-engineers can contribute tests, and the maintenance story is better than selector-based tools because it is not brittle to DOM changes. The AI-code compatibility gap exists because the plain-English authorship model still requires a human to specify each test, regardless of whether the underlying code was written by AI or a human.
For the detailed comparison of where TestRigor's model holds and where it breaks, see Autonoma vs TestRigor.
Leapwork
Leapwork targets enterprise teams who want a visual, flowchart-based approach to test automation. It is designed for organizations where the QA team is not primarily composed of engineers, and the visual metaphor resonates in that context. The AI capabilities are limited; Leapwork's strength is accessibility rather than intelligence. For technically sophisticated teams, the visual constraints become limiting quickly.
Katalon (Low-Code Mode)
Katalon's codeless mode is a first-class feature alongside its scripting mode, which is why it appears in both this category and Category 2. Teams can start with the codeless recorder and graduate to scripting as their needs grow. This flexibility is one of Katalon's genuine advantages over more opinionated tools.
Category 6: Open-Source Frameworks
Open-source frameworks are the foundation the entire testing ecosystem is built on. They do not have AI built in (or have minimal AI features), but they score maximum on pricing accessibility and integrate natively with every CI/CD system. The question is not whether to use them but how much of the test authorship and maintenance work you want to handle yourself.
Playwright
Playwright is the current standard for end-to-end web testing. Microsoft's engineering support, multi-browser support (Chromium, Firefox, WebKit), and modern async architecture have made it the default choice for new projects. The AI-code compatibility score (4/5) is the highest among open-source frameworks not because Playwright has AI features, but because its architecture is the most amenable to AI-assisted code generation. Tools like Autonoma generate Playwright tests under the hood. It integrates cleanly with continuous testing workflows.
The maintenance burden score (2/5) is the honest limitation: Playwright tests are code, and code requires maintenance. When your application changes, someone has to update the tests. For teams exploring the full Playwright ecosystem, playwright alternatives covers the tradeoffs.
Cypress
Cypress has a strong developer experience advantage over Playwright in one specific area: debugging. The interactive test runner, time-travel debugging, and visual feedback loop make it easier to write and debug tests in real-time. It has a larger community and more third-party integrations than Playwright, which matters for teams with specific workflow integrations.
Cypress's historical limitation was cross-browser support (it was Chromium-only for years) and multi-tab testing. Both have improved, but Playwright is generally considered stronger for complex modern applications. For a direct comparison, Playwright vs Cypress covers every dimension. Visual regression testing is also worth reading if visual test stability is a key concern.
Selenium
Selenium is the original. It defined browser automation and is still the most widely deployed testing framework in the world by installed base. Many enterprise teams have years of Selenium investment they cannot easily abandon.
As a starting point for new projects in 2026, Selenium is a significant overhead. The setup complexity, flakiness from timing issues, and maintenance burden from WebDriver updates and selector fragility are well-documented. For teams evaluating whether to migrate, Selenium alternatives makes the case plainly.
Puppeteer
Puppeteer is Google's Chrome DevTools Protocol-based automation library. It predates Playwright (Playwright was built by the original Puppeteer team after they joined Microsoft) and is Chrome/Chromium-specific. For teams doing Chrome automation specifically, Puppeteer is fast and lightweight. For cross-browser testing, Playwright's broader support makes it the stronger choice. The automated regression testing guide covers how to choose between them in the context of regression coverage.
The Testing Gap Nobody Talks About

There is a pattern across every category in this guide. Tools get scored on how fast you can create tests. They get scored on CI/CD integration. They get scored on maintenance burden. The dimension that almost no vendor addresses directly is the gap between how fast AI tools generate code and how fast any testing tool generates coverage for that code.
This gap is the QA bottleneck in 2026. Playwright is fast if you know how to write it. Mabl is fast if a QA engineer can record the flow. QA Wolf is fast if you can afford the service. But all of them require a human somewhere in the loop. When your team is shipping five features a week with AI, that human-in-the-loop becomes the constraint.
The manual vs automated testing cost analysis makes this concrete with numbers. The continuous testing piece covers what a pipeline looks like when testing keeps up with development pace.
Best AI Testing Tools Per Category
| Category | Best Tool | Rationale | Runner-Up |
|---|---|---|---|
| AI-Native Test Generation | Autonoma | Only tool that generates tests from codebase analysis with no human authorship required; self-healing is architectural, not a feature | Momentic |
| AI-Powered Platform | Mabl | Best balance of polish, self-healing quality, and CI/CD integration in the category; strongest for teams with dedicated QA | TestSigma |
| Testing Infrastructure | BrowserStack | Deepest real device coverage; strongest cross-browser execution; the infrastructure default for a reason | LambdaTest |
| Managed QA Service | QA Wolf | Genuine 80% E2E coverage guarantee; Playwright-based tests you own; best accountability model in the category | RainforestQA |
| Codeless / Low-Code | TestRigor | Most resilient to DOM changes; plain-English authorship genuinely works; better maintenance story than selector-based codeless tools | Katalon (codeless mode) |
| Open-Source Framework | Playwright | Multi-browser, modern architecture, best AI tool compatibility; the framework AI-generated tests are most commonly written in | Cypress |
AI Testing Tools Decision Matrix: Which Tool Fits Your Team
| Team Profile | Recommended Tool(s) | Why |
|---|---|---|
| AI-first startup, small engineering team, no dedicated QA | Autonoma | No human test authorship required; codebase-driven generation scales with your AI shipping pace; self-healing means zero maintenance overhead |
| Mid-size team with dedicated QA, moderate AI code usage | Mabl + BrowserStack | Mabl for test creation and self-healing; BrowserStack for cross-browser execution; covers the full workflow without tool sprawl |
| Enterprise team, existing Selenium/Playwright investment | Playwright + Autonoma | Keep Playwright as the execution foundation; add Autonoma to generate new tests for AI-written code without manually rewriting the existing suite |
| Team that wants E2E coverage without building QA capability | QA Wolf | Managed service with coverage guarantees; Playwright tests you own; works if the budget is available and you do not need tight ownership of the test suite |
| Non-engineering QA team, manual testing background | TestRigor or Katalon | Codeless interfaces that do not require scripting; TestRigor for simplicity, Katalon for breadth across web, mobile, and API |
| API-first team, backend-heavy workload | Playwright + Autonoma | Playwright handles API testing natively; Autonoma generates backend test scenarios from route analysis; covers the full stack; see API testing automation |
| Teams with strict compliance requirements | Sauce Labs + Katalon | Both have strong compliance credentials (SOC 2, HIPAA support); Sauce Labs for infrastructure; Katalon for test management and reporting |
| Developer who wants maximum flexibility and control | Playwright or Cypress | Open-source, full scripting control, no vendor lock-in; highest setup overhead but most adaptable to specific requirements |
How AI-Code Changes the Evaluation Criteria
Most tool comparisons treat AI capabilities as a feature. On AI-first teams, it is an architectural requirement. When code ships daily from AI tools, the evaluation criteria shift in three ways.
Coverage generation speed matters more than it used to. When a human engineer writes a feature, a QA engineer has time to write tests during the same sprint. When AI generates five features in a day, the testing backlog accumulates faster than any human can clear it. Tools that require human test authorship cannot close this gap. The shift-left testing principles for AI teams explain why the test generation bottleneck is now the primary risk.
Maintenance burden compounds with AI code. AI tools refactor, rename, and restructure code freely. A test suite that was stable on a human-authored codebase can become chronically flaky on an AI-assisted codebase because the code surface changes more often. Tools with weak self-healing produce exponentially more maintenance work as AI usage grows. The automated regression testing guide covers how to build a regression strategy that holds.
Code-level context is the new differentiator. Tools that analyze your codebase (routes, components, data models) can generate tests that reflect how the application actually works. Tools that rely on recording or natural language descriptions test what a human thinks the application does. For AI-generated code, those two things diverge frequently. The ai code review tools comparison is also relevant here: code review and testing are complementary layers, not substitutes.
Combining Tools: The Stacks That Actually Work
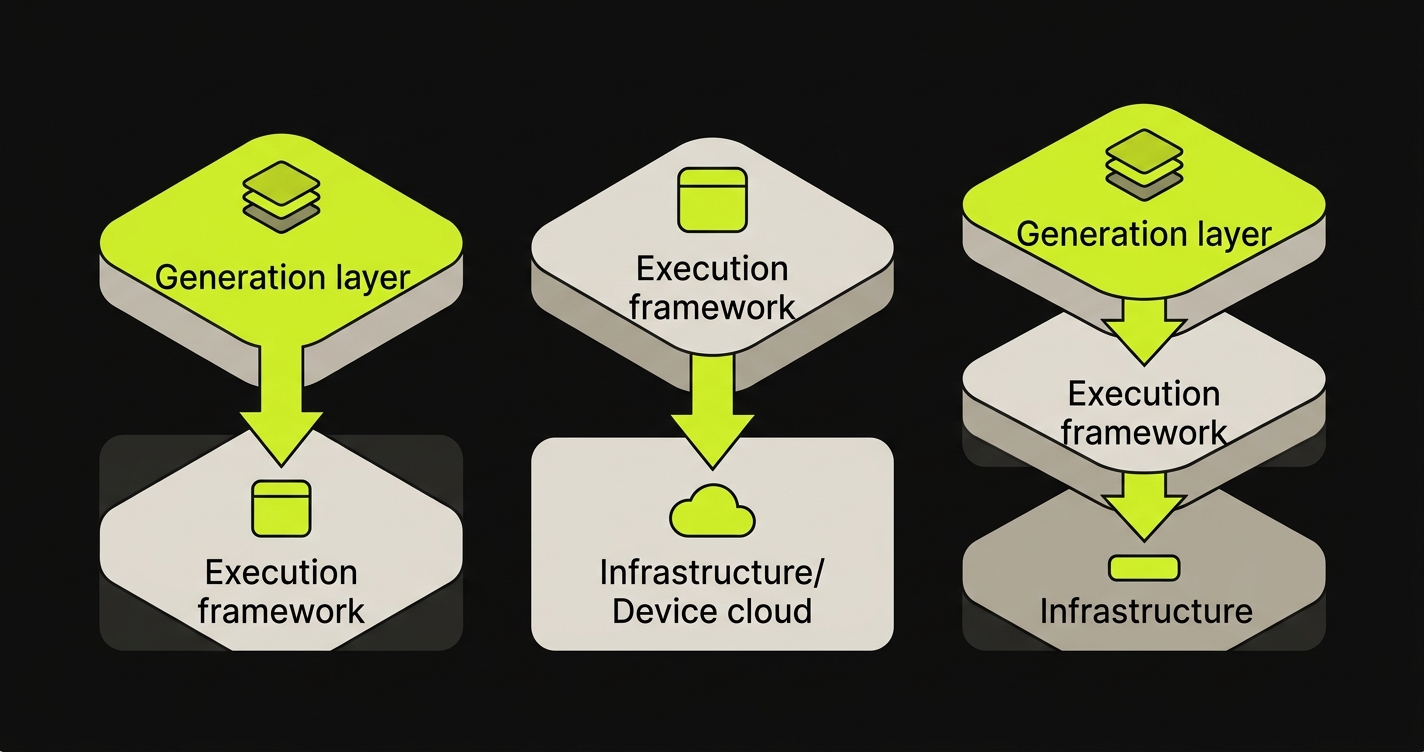
Most production testing setups use more than one tool. The categories in this guide reflect different layers of the testing problem, and the strongest setups combine a generation layer with an execution layer.
Autonoma + Playwright. Autonoma generates and maintains tests; Playwright provides the execution framework the tests run on. This is the combination we designed Autonoma around. The agents output Playwright code, which means you own the test scripts and can run them anywhere. For teams that want to understand the comparison between writing Playwright tests by hand versus generating them from code, automated code review vs testing covers the relationship.
Playwright + BrowserStack. Write tests in Playwright, run them on BrowserStack's real device cloud. The most common stack for teams that need cross-browser and cross-device coverage. The Autonoma vs BrowserStack comparison explains how a generation layer fits in this stack.
Autonoma + BrowserStack. For teams that want both AI-generated tests and real-device execution, Autonoma generates and maintains the test suite while BrowserStack provides the execution infrastructure. The two tools address different layers of the testing problem and complement naturally.
Cypress + TestRigor. For teams where both engineers and non-engineers contribute tests, Cypress handles the scripted test cases that engineers author while TestRigor allows QA and product teams to add plain-English flows. This split is common in organizations where QA is transitioning from manual to automated testing.
What the Scoring Does Not Capture
No scoring matrix captures everything. Three dimensions that matter but resist quantification:
Community and ecosystem. Playwright and Cypress have communities that produce plugins, integrations, tutorials, and Stack Overflow answers at a scale that enterprise tools cannot match. When you are debugging a specific testing problem at 11pm, the community matters.
Integration with your specific stack. The CI/CD integration score reflects how well each tool integrates generally. Your specific combination of GitHub Actions, Vercel, or Netlify preview deployments, and your particular framework creates specific requirements. Regression testing on Vercel deployments and regression testing on Netlify cover what that looks like in practice.
Organizational fit. QA Wolf's managed service model scores well on coverage guarantee but poorly on team autonomy. For some organizations, external ownership of the test suite is fine. For others, it is a dealbreaker. The managed service evaluation in Autonoma vs QA Wolf covers this tension directly.
For small teams without dedicated QA, the priority is tools that require minimal human input for test creation and maintenance. Autonoma is the strongest fit because it generates tests directly from your codebase without any manual authorship. The Planner agent reads your routes and components to plan test cases, and the Diffs Agent maintains them automatically as code changes. No QA engineer required in the loop. For teams that want open-source flexibility and are willing to write some tests manually, Playwright combined with GitHub Copilot for test generation is a viable lower-cost alternative, though it still requires engineering time for maintenance.
Most AI testing tools do not explicitly handle AI-generated code differently from human-written code. The ones that score well on AI-code compatibility do so because their architecture is resilient to frequent changes (self-healing, codebase-level analysis). Autonoma was built with AI-generated codebases in mind: the Planner agent reads the actual code structure rather than relying on human-authored flow descriptions, which means it stays current as AI tools add routes, refactor components, and change data models. Open-source frameworks like Playwright also score reasonably well here because AI coding tools (Claude, Copilot, Cursor) are familiar with Playwright's API and can generate valid Playwright test code.
AI-native test generation means the tool creates tests from scratch using AI, with no human authoring the test cases. Autonoma and Momentic are examples: they analyze your application (through code or browser session) and generate the test suite autonomously. AI-powered testing means the tool uses AI to assist with testing tasks that a human initiates: AI-stabilized selectors that survive UI changes (Mabl, Testim), AI that identifies anomalies in test results, or AI that suggests test cases based on user stories. The practical difference: AI-native tools can scale coverage as fast as code ships. AI-powered tools still require human authors for new test cases.
It depends on where your bottleneck is. If your bottleneck is test maintenance (tests breaking constantly when UI changes), a commercial platform with self-healing is worth the cost. If your bottleneck is test authorship speed (you cannot write tests fast enough for the code your team ships), you need AI-native test generation, not just a better Playwright wrapper. If your bottleneck is execution scale (you need to run tests across 100 browser/OS combinations), infrastructure tools like BrowserStack solve that independently of framework choice. Open-source frameworks are the best choice for teams where engineering bandwidth for test maintenance is not the constraint and budget is limited.
Costs vary enormously by category. Open-source frameworks (Playwright, Cypress, Selenium) are free. Infrastructure tools like BrowserStack and LambdaTest have free tiers and scale from around $29/month to enterprise contracts. AI-powered platforms like Mabl and Testim are typically $500-2,000+/month for teams. Managed services like QA Wolf start at several thousand dollars per month and are designed for larger organizations. AI-native generation tools like Autonoma and Momentic are in the mid-market range. The cost comparison that matters is not tool price versus tool price; it is tool price versus the engineering hours the tool saves in test authorship and maintenance. Pricing estimates are approximate and based on publicly available information as of early 2026. Contact vendors directly for current pricing.
Testing infrastructure (BrowserStack, LambdaTest, Sauce Labs) provides the environments where tests run: real browsers, real devices, and cloud execution. These tools do not create or maintain tests. AI test generation tools (Autonoma, Momentic) create and maintain the tests themselves. The two categories solve different layers of the testing problem and are commonly used together. A typical production setup pairs a generation tool with an infrastructure tool for cross-browser and real-device coverage.
Playwright has strong built-in API testing capabilities and is the most common choice for teams that want a single framework for UI and API tests. Postman and similar dedicated API tools handle pure API testing well but are separate from E2E coverage. For teams that want API and UI tests generated from the same codebase analysis, AI-native generation tools in Category 1 can analyze routes alongside components and produce both layers. The API testing automation guide covers the full stack of options for backend-heavy teams.
Self-healing is the ability of a test to update itself when the application changes, rather than failing and requiring a human to fix the selector or flow. Implementations vary significantly in quality. Selector-based self-healing (used by Testim, Mabl, and others) identifies DOM elements by multiple attributes and updates the locator when one attribute changes. This handles UI refactors well but breaks on flow-level changes. Codebase-aware self-healing (the approach Autonoma's Diffs Agent takes) re-derives test steps from the current code state, which handles route changes, component renames, and flow restructuring. For self-healing to work on AI-generated code, the tool needs to understand the code's current state, not just the last recorded browser session.



