
Shift left testing is the practice of moving quality assurance activities earlier in the software development lifecycle, catching bugs during development rather than after deployment. In the traditional model, a developer writes code, writes tests for that code, and gets fast feedback before anything reaches production. This works because the developer who wrote the code is also the one writing the tests: they understand the intent, the edge cases, and the failure modes. AI code generation breaks this assumption fundamentally. When an LLM generates the implementation, the developer reviewing it may understand what it does at a surface level, but not why specific branches exist, what invariants the logic relies on, or which inputs will cause it to fail. Writing tests for code you didn't fully author is a different cognitive task than testing code you built yourself. This article examines what this shift means for shift left testing strategy, introduces a framework for thinking about the gap, and covers the tooling landscape from open-source frameworks to AI-native testing platforms built for this new reality.
Fifty pull requests per day. That is not a future projection. That is what high-performing teams using AI coding assistants are shipping today. The test suite covering those fifty PRs? Growing at roughly the pace it always has, because humans still write the tests.
The math is brutal. A QA team that historically kept pace with ten PRs per day is now facing a five-to-one coverage deficit, and the gap compounds every sprint. Shift left testing was the solution to the old bottleneck, getting quality feedback earlier in the cycle rather than drowning QA at the end. But shift left was designed for a world where code velocity and human cognition moved at comparable speeds.
They no longer do. The data from AI-velocity teams tells a consistent story: test coverage as a percentage of shipped code is declining even as teams invest more in testing infrastructure. Understanding why requires looking at what shift left testing actually assumes about who is writing the code.
What Shift Left Testing Actually Means
Before examining what breaks, it helps to be precise about what shift left testing is.
The term comes from visualizing a software development timeline as a horizontal axis, with requirements on the left and production on the right. "Shifting left" means moving testing activities toward the requirements end: writing tests before or during development rather than after. The logic is straightforward. A bug caught in development costs significantly less to fix than a bug caught in production. IBM's Systems Sciences Institute research from the 1990s estimated a 100x cost ratio between the two. More recent data from NIST puts the ratio closer to 30x when accounting for modern development practices. Either figure makes the case clearly.
In practice, shift left testing means unit tests written alongside feature code, integration tests part of the pull request rather than a post-merge activity, and automated regression testing running in CI before any code reaches staging. It means QA engineers embedded in sprint planning rather than sitting at the end of the pipeline.
The practices are well-understood. The tooling is mature. Playwright, Cypress, pytest, and dozens of others make it relatively straightforward to write tests close to development. For a decade, the hard part of shift left testing was cultural, not technical: convincing developers to write tests at all.
AI code generation introduced a technical hard part.
How AI Code Generation Breaks the Shift Left Assumption
Here is the assumption embedded in every shift left testing methodology: the developer writing the tests understands the code being tested.
This assumption is load-bearing. It is what makes developer-authored tests valuable. A developer who built a payment processing function knows that the currency conversion happens before rounding, not after. They know that a zero-amount charge should return a specific error code rather than succeed silently. They know which state combinations are impossible and don't need to be tested. That tacit knowledge shapes the test suite in ways that matter. Tests written with deep understanding of the implementation catch the right failures.
AI code generation severs this link. When a developer prompts an AI coding agent to implement a payment processing module, what comes back is structurally correct code that handles the specified requirements. What the developer gets is not equivalent to code they wrote themselves. They have a review relationship to the code rather than an authorship relationship. The difference is significant.
In a review relationship, you verify that the code appears to do what was asked. In an authorship relationship, you know why each line exists, what alternatives were considered and rejected, and what the code will do when inputs stray from the happy path. A developer who reviews AI-generated code thoroughly can develop something close to authorship understanding. But this takes time, and in teams using AI for velocity, that time is often the first thing sacrificed.
The downstream effect on testing is measurable. Tests written for AI-generated code by developers who didn't fully internalize the implementation tend to cluster around the happy path. They test the behavior that was specified in the prompt. They miss the edge cases that a human author would have encountered while writing and would have naturally included in the test suite.
This is not a criticism of developers or of AI tools. It is a description of an epistemic gap that is structurally created by the separation between code generation and code understanding. Acknowledging the gap is the first step to designing around it.
Autonoma bridges this gap by running independently of the coding agent — it reads your codebase from the outside, generates behavioral tests for the flows that matter, and catches the failure modes that the AI that wrote the code cannot see.
The Shift Left Paradox
Working with engineering teams that have adopted AI coding tools heavily has made the pattern clear enough to name.
Traditional shift left looks like this: developer writes code, developer writes tests for that code, CI gives fast feedback, bugs are caught in development. The loop is tight because the same mind holds the implementation knowledge and the test authorship. Shift left works as intended.
AI-assisted shift left looks like this: AI writes code, developer reviews code (partial understanding), developer writes tests (based on partial understanding), CI gives feedback, some bugs are caught. The loop is slower and less complete because the test author's understanding is shallower than an author's understanding would be. This is still better than shift-right testing, but it is not what shift left testing was designed to deliver.
AI-native shift left is the emerging model: AI writes code, AI generates tests from the code (full structural understanding), CI gives instant feedback, human validates results. The loop is tight again because the same type of system holds both the implementation and the test generation. The human role shifts from test authorship to test validation.
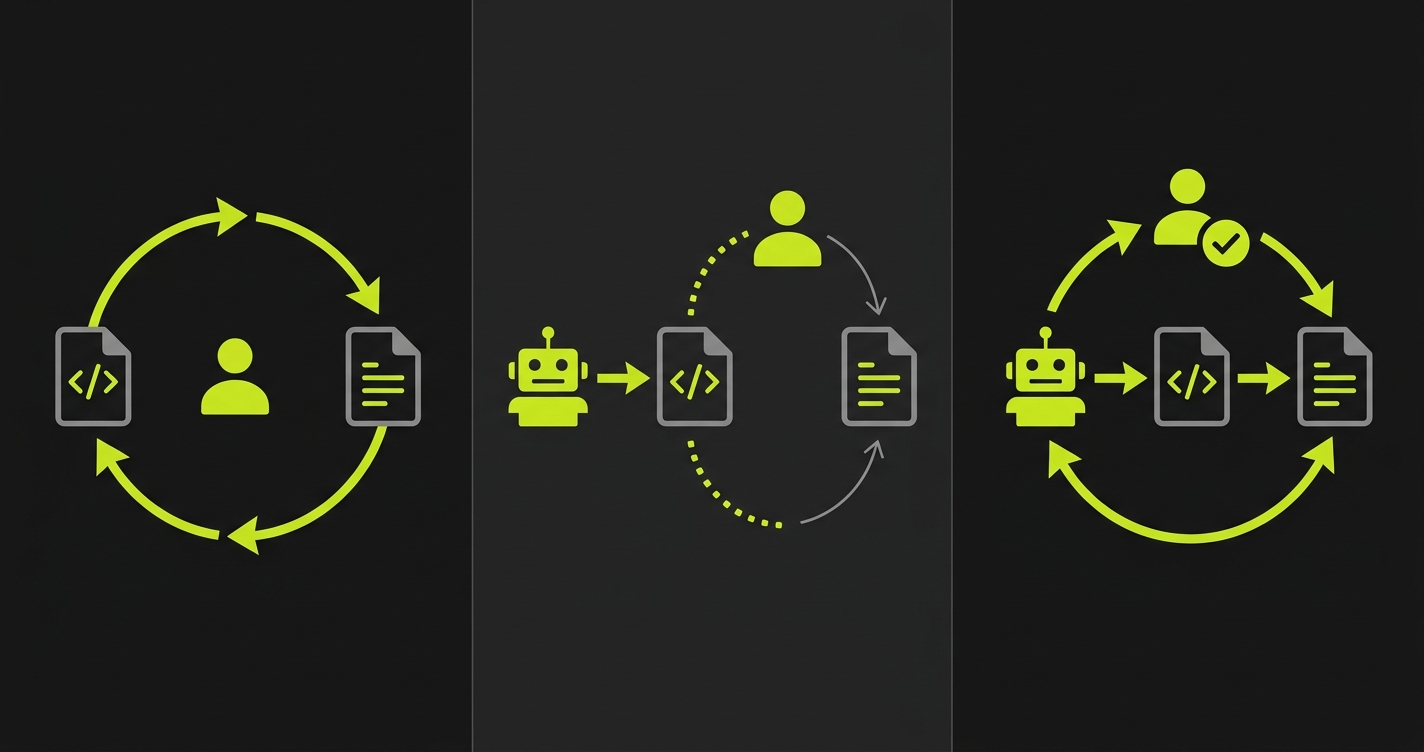
The paradox is this: the tool that creates the understanding gap (AI code generation) is also the tool best positioned to close it (AI test generation). A system that reads your codebase to generate tests has structural access to the same information the code generator had. It can infer invariants from type signatures, edge cases from conditional branches, and state requirements from data models, in ways that a human reviewer working under time pressure often cannot.
This is not a hypothetical. It is the architectural rationale for why continuous testing tooling is evolving to read codebases rather than record user sessions or wait for human-authored test scripts.
Tool Landscape: Where Each Category Fits
The market for shift left testing tools predates AI code generation, and most of the established tools were designed for a world where human developers write the code they test. Understanding where each category excels, and where it strains, is necessary for building a strategy that works at AI velocity.
| Tool | Test Creation Speed | AI Code Compatibility | Maintenance Burden | CI/CD Integration | Pricing Tier |
|---|---|---|---|---|---|
| Playwright | Slow (manual authoring) | Good (code-based, readable) | High (selector drift) | Excellent (native) | Free / Open Source |
| Cypress | Slow (manual authoring) | Good (JavaScript-native) | High (selector drift) | Excellent (native) | Free / Open Source |
| pytest | Moderate (fixtures help) | Excellent (API/unit focus) | Moderate (logic-based) | Excellent (native) | Free / Open Source |
| BrowserStack | Slow (manual authoring) | Neutral (infrastructure only) | High (on your team) | Good (via Automate) | Paid (from $29/mo) |
| LambdaTest | Slow (manual authoring) | Neutral (infrastructure only) | High (on your team) | Good (via HyperExecute) | Paid (from $15/mo) |
| Mabl | Moderate (low-code) | Weak (recording-based) | Moderate (auto-healing limited) | Good (CI plugins) | Paid (enterprise pricing) |
| Autonoma | Fast (AI-generated from code) | Native (codebase-first) | Minimal (self-healing) | Excellent (CI-native) | Free / Open Source |
Open-Source Frameworks: Still the Foundation
Playwright and Cypress are not going away, nor should they. For teams with existing test suites, they represent years of accumulated coverage. For teams starting fresh, they are the most flexible foundation available.
The honest assessment: both frameworks require human authoring. When your team is shipping 50 AI-generated PRs per week, human authoring becomes the constraint.
For Playwright, a minimal setup in CI looks like this:
# Install Playwright
npm init playwright@latest
# Run tests in CI
npx playwright test --reporter=github// Example: Playwright test for an AI-generated auth flow
import { test, expect } from '@playwright/test';
test('authentication flow - happy path', async ({ page }) => {
await page.goto('/login');
await page.fill('[data-testid="email"]', 'user@example.com');
await page.fill('[data-testid="password"]', 'correct-password');
await page.click('[data-testid="submit"]');
await expect(page).toHaveURL('/dashboard');
});
test('authentication flow - invalid credentials', async ({ page }) => {
await page.goto('/login');
await page.fill('[data-testid="email"]', 'user@example.com');
await page.fill('[data-testid="password"]', 'wrong-password');
await page.click('[data-testid="submit"]');
await expect(page.locator('[data-testid="error-message"]')).toBeVisible();
});For Cypress, the equivalent setup is similarly lightweight:
# Install Cypress
npm install cypress --save-dev
# Open interactive runner
npx cypress open
# Run headless in CI
npx cypress run// Example: Cypress test for the same auth flow
describe('Authentication', () => {
it('redirects to dashboard after successful login', () => {
cy.visit('/login');
cy.get('[data-testid="email"]').type('user@example.com');
cy.get('[data-testid="password"]').type('correct-password');
cy.get('[data-testid="submit"]').click();
cy.url().should('include', '/dashboard');
});
it('shows error for invalid credentials', () => {
cy.visit('/login');
cy.get('[data-testid="email"]').type('user@example.com');
cy.get('[data-testid="password"]').type('wrong-password');
cy.get('[data-testid="submit"]').click();
cy.get('[data-testid="error-message"]').should('be.visible');
});
});Both frameworks excel at testing code once you know what to test. That is still true when the code is AI-generated. The challenge is that what to test requires the authorship understanding that AI code generation reduces.
Browser Infrastructure: BrowserStack and LambdaTest
BrowserStack and LambdaTest are infrastructure tools, not testing intelligence tools. They provide real browser and device environments for running tests across Chrome, Safari, Firefox, Edge, iOS, and Android. For cross-browser coverage and mobile testing, they are genuinely useful.
What they do not do is generate tests or understand your codebase. They run the tests you give them, at scale, across environments you specify. If your challenge is "I need to run my Playwright suite across 20 browser configurations," BrowserStack and LambdaTest solve that. If your challenge is "I need tests written for code I didn't author," they do not.
This distinction matters when evaluating tooling for AI-velocity teams. The bottleneck is test creation, not test execution infrastructure.
Mabl: AI Features Built for the Previous Era
Mabl has invested in AI features including auto-healing selectors and some test suggestion capabilities. It is a well-built product. The fundamental design constraint is that it was built for teams where developers write code and QA engineers record flows or write test scripts. The AI layer sits on top of that model.
For teams where AI writes the code, the recording-based approach amplifies the gap rather than closing it. Recording a flow through an application captures UI interactions, not application intent. When AI-generated code changes the underlying logic without changing the UI, recorded tests pass through a regression.
The Emerging Category: Codebase-First Test Generation
The third category, the one built for the AI-native shift left model, reads your codebase rather than watching a user click through your application.
This is the architectural difference that matters. A testing tool that reads your routes, components, data models, and user flows has access to the same structural information that an LLM code generator used to produce the code. It can infer what the code is supposed to do, what states need to exist for each scenario, and what the failure modes look like, without requiring a human to bridge that gap.
This is the problem we kept running into on our own team before we built Autonoma. Someone had to read the AI-generated implementation deeply enough to write good tests, and that person became the slowest part of the entire pipeline. The codebase-first approach removes that dependency: tests are generated from your code structure, executed against your running application, and maintained as the code changes. Autonoma is open source and self-hostable, with a free tier available. The human role shifts from writing tests to validating that the right behaviors are covered.
The pattern is the same one that made shift left testing work in the first place: keep the feedback loop tight. The difference is that the loop now runs between code generation and test generation, rather than between a developer's mental model and their test file.
Implementing Shift Left Testing at AI Velocity
Knowing the framework is useful. Having an implementation path is more useful.
The practical approach differs depending on where your team sits in the transition.
If your team is still primarily human-authored code, the traditional shift left practices apply with some additions. Run Playwright or Cypress in CI. Write tests as part of the PR rather than after. Add contract testing for your API boundaries. The main adjustment is to start building the infrastructure that will scale when AI code generation increases.
If your team uses AI for some code generation, the hybrid approach matters. Treat AI-generated PRs as requiring additional test scrutiny, not less. The code may be structurally correct while missing invariants the prompt didn't specify. Have engineers do a focused edge-case review on AI-generated code specifically, asking: what happens when inputs are at boundary values? what happens when external dependencies fail? what state does this assume exists? Write tests from those questions, not just from the happy path.
If your team is running at full AI velocity, 30 or more PRs per week from AI assistance, the manual approach breaks down on math alone. A comprehensive test for an AI-generated feature takes a senior engineer 2-4 hours to write well. At 30 PRs per week, that is 60-120 engineer-hours of test authorship per week. The only solution is to make test generation match code generation velocity. This is where codebase-first AI testing becomes necessary rather than optional.
The implementation steps for full-velocity teams:
Connect your codebase to an AI testing platform that reads your routes and components. Let the Planner agent generate the initial test suite from your code structure. Run it in CI from the first day. Then, critically, treat the results as a validation task rather than a review task. You are not checking whether the tests are comprehensive (the agent handles that). You are checking whether the behaviors being tested reflect your actual intent.
This shift in the human role, from test author to test validator, is what makes shift left testing sustainable at AI velocity. It preserves the fast-feedback loop that shift left was designed to create, while removing the authorship bottleneck that AI code generation creates.
The Regression Risk Is Asymmetric
One aspect of the AI code generation testing problem that doesn't get discussed enough: AI tools introduce regressions in patterns that differ from human-introduced regressions.
Human developers introduce regressions in areas they touched. When a developer modifies the checkout flow, the regressions are usually in the checkout flow or in code that was tightly coupled to it. This is intuitive. You modified A, A broke B.
AI code generation introduces regressions differently. An AI that is asked to add a new feature to a codebase may modify shared utilities, update common data models, or refactor helper functions as part of producing the requested output. The regressions appear in places the developer didn't intend to touch and may not think to test. The diff looks focused. The downstream effects are not.
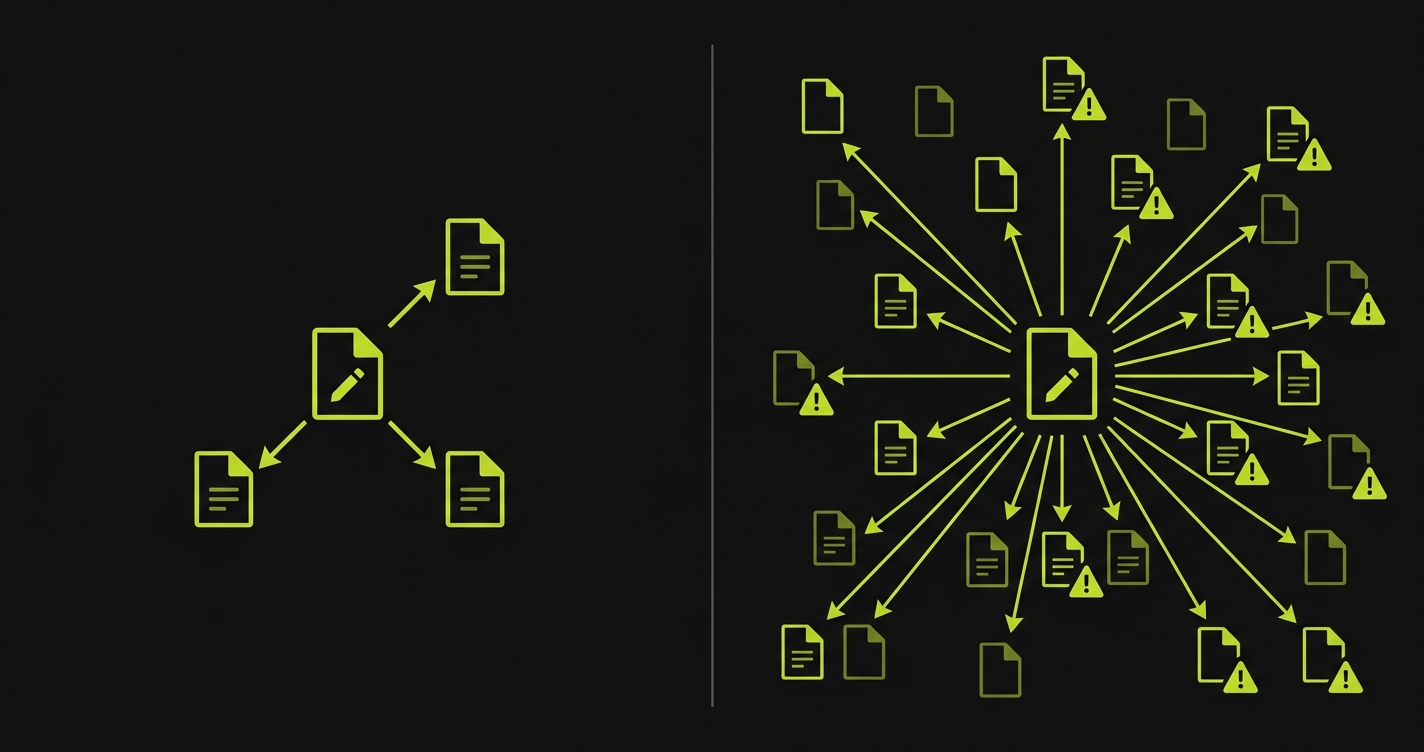
This makes automated regression testing more critical, not less, in AI-velocity environments. The suite needs to be broad enough to catch regressions in unexpected places, not just in the code that was nominally changed. And it needs to run automatically on every PR, because the cost of manually identifying which test areas to run against an AI-generated PR is prohibitive.
Continuous testing in the CI pipeline, covering the full application surface, is the structural answer to asymmetric regression risk. It is also what makes the shift left model work in practice rather than theory: tests run on every change, regardless of which parts of the codebase the change nominally touches.
Choosing Your Path Forward
For teams building their shift left testing strategy today, the choice comes down to where your code generation velocity is heading.
If AI tools are supplementary and most code is still human-authored, invest in Playwright or Cypress with strong CI integration. Build the test authorship discipline now, before the volume makes it impossible. Add pytest for API and unit coverage. The practices are well-documented and the tooling is stable.
If AI tools are becoming primary and PR volume is scaling past what manual test authorship can cover, the upgrade path is a codebase-first testing layer. Playwright and Cypress remain valid for existing test suites. The new coverage comes from tools that can read your code and generate tests at the same speed code is generated. If you've outgrown manual test authoring with Playwright, Autonoma adds the AI layer: your codebase is the spec, agents generate and maintain the tests, and your engineers validate rather than author.
The teams that will have structural quality advantages in 12 months are the ones solving the test generation bottleneck now, while their peers are still writing tests by hand for code written by machines.
Shift left testing means moving quality assurance earlier in the development lifecycle, catching bugs during development rather than after deployment. In traditional development, this works because the developer who writes the code also writes the tests and understands the implementation deeply. In AI-assisted development, this assumption breaks: when an LLM generates the code, the developer reviewing it has partial understanding of the implementation's edge cases and failure modes. This makes shift left testing both more important (AI tools can introduce regressions in unexpected places) and harder to execute well (test authorship requires understanding that AI code generation reduces). Teams adopting AI tools need to adapt their shift left strategy, not abandon it.
The traditional shift left loop (developer writes code, developer writes tests, CI gives feedback) slows down when AI writes the code. The developer reviewing AI-generated code has a review relationship rather than an authorship relationship to the implementation. Tests written from a review relationship tend to cluster around the happy path, missing the edge cases a human author would have internalized. The emerging adaptation is AI-native shift left: AI writes code, AI generates tests from the code's structure (routes, components, data models), CI provides instant feedback, and humans validate results. The fast-feedback loop is preserved, but the test authorship bottleneck is removed. This is what makes shift left testing viable at the PR velocity AI tools enable.
Both Playwright and Cypress work well as test execution frameworks for AI-generated code. Playwright has broader cross-browser support and stronger TypeScript integration, which can be valuable when AI-generated code uses modern TypeScript patterns. Cypress has a more developer-friendly debugging experience and strong JavaScript ecosystem integration. Neither framework solves the fundamental challenge of AI-velocity testing: they both require human test authorship, which becomes the bottleneck when AI generates code faster than humans can write tests for it. For teams with existing suites in either framework, the upgrade path is adding a codebase-first AI testing layer that generates tests automatically, rather than replacing the framework. The frameworks handle execution; the AI layer handles test generation and maintenance.
Vibe coding testing refers to the quality assurance challenge specific to vibe coding workflows, where developers use AI tools to generate most or all of the application code with minimal manual implementation. The testing challenge is acute because the developer may not have deep authorship understanding of the generated code, making traditional test authorship difficult. Shift left testing in a vibe coding context requires tools that can generate tests directly from the codebase rather than relying on developer knowledge of the implementation. The most effective approach is codebase-first test generation: an AI agent reads your routes, components, and data models and generates test cases from the structural analysis, then maintains those tests as the code changes. This preserves the shift left goal (fast feedback, bugs caught early) while removing the dependency on deep implementation knowledge that vibe coding reduces.



