
Automated code review uses static analysis tools to inspect source code before it runs, catching style violations, anti-patterns, and known security issues at the pull request stage. Automated testing runs your application against real inputs to catch functional bugs, integration failures, and user-facing regressions. Both matter. But as AI coding tools accelerate output, the bottleneck has shifted: Layer 1 (linting) and Layer 2 (static analysis/code review) are increasingly handled automatically by AI IDEs themselves. The gap that's growing fastest is Layer 3 and Layer 4 -- unit tests, integration tests, and E2E coverage that verify the application actually works as intended.
The team shipped a new checkout flow on a Friday. Automated code review passed: no style violations, no flagged security patterns, clean diff. On Monday, three users reported that applying a discount code after selecting a shipping method silently reset their cart. The code was readable. The logic was broken.
This is the scenario that separates the two disciplines. Automated code review would never catch that bug, not because it failed, but because that was never its job. The question for engineering leaders in 2026 isn't whether to use code review tools or testing tools. It's understanding exactly what each layer catches, and recognizing which layers your team is underinvesting in.
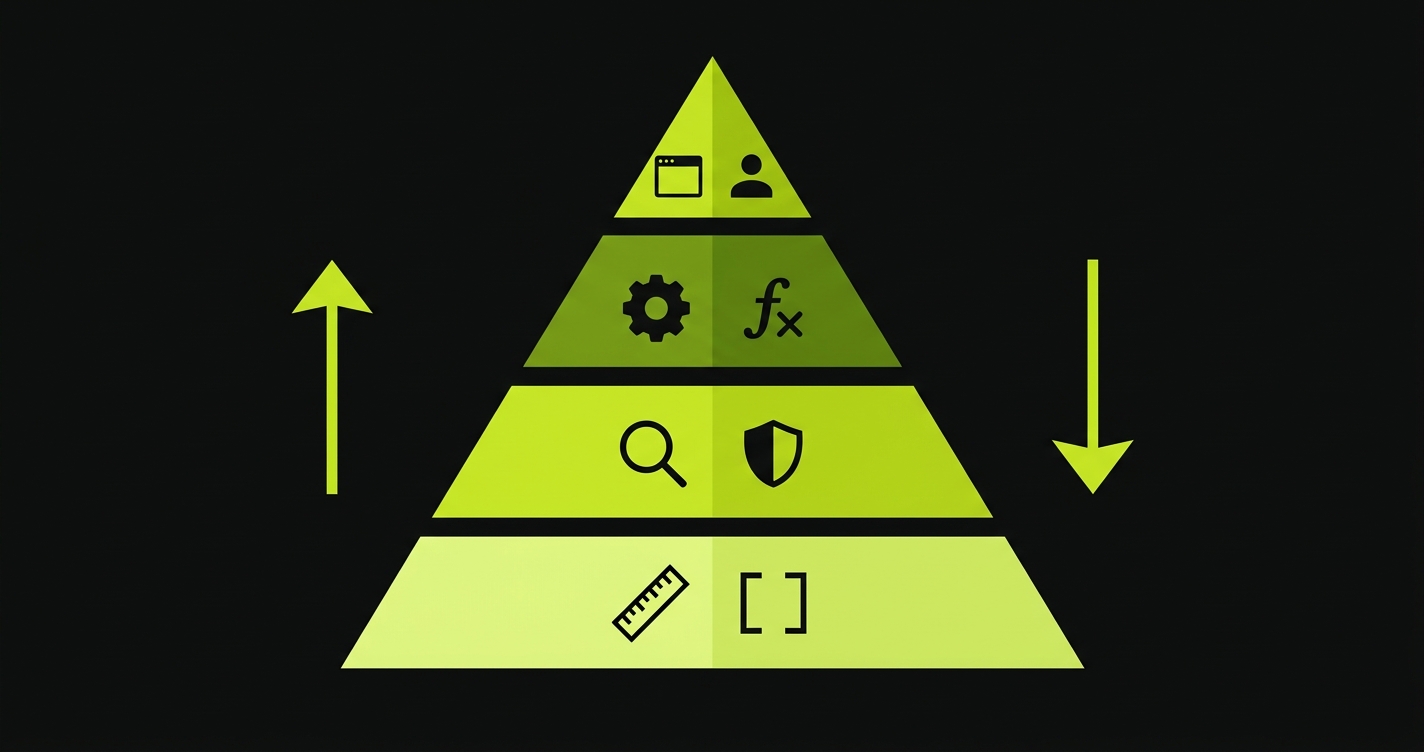
The Quality Pyramid for AI-Generated Code
Before comparing tools, it helps to have a shared model. Most teams think of quality tooling as a flat list of things to configure. In practice, quality assurance is a pyramid with four distinct layers, each catching a different class of problem.
Layer 1: Linting and formatting. ESLint, Prettier, Ruff, and their equivalents catch syntax errors, code style inconsistencies, and trivially incorrect patterns before a PR is even opened. They are fast, cheap, and almost entirely automated by modern AI IDEs. Cursor auto-formats on save. Copilot chat fixes lint errors on request. This layer is effectively solved for most teams.
Layer 2: Static analysis and automated code review. Tools like SonarQube, CodeRabbit, and Semgrep inspect the code without running it. They identify security anti-patterns (hardcoded credentials, SQL injection vectors), structural complexity, duplicated logic, and common bug patterns. This is what most people mean when they say "automated code review." It is genuinely valuable. It also has a ceiling: static analysis can only evaluate what the code looks like, not what it does.
Layer 3: Unit and integration tests. Jest, pytest, Vitest, and similar frameworks execute code paths and verify outputs. For a deeper breakdown of how these layers compare, see our guide to automated regression testing. A unit test checks that a function returns the right value. An integration test checks that two modules work together correctly. This layer catches functional bugs that no amount of reading the code would surface. It requires writing test cases, and maintaining them as the codebase evolves.
Layer 4: End-to-end and AI-native testing. Playwright, Cypress, and AI-native platforms like Autonoma exercise the full application stack as a real user would. They catch regressions that only manifest when the frontend, backend, and database interact. They are the most expensive to maintain and the most valuable when they catch something.
The strategic implication: the bottleneck has moved. Investing more in linters or static analysis in 2026 is optimizing a layer that's already mostly handled. The ROI is in closing the Layer 3 and Layer 4 gap.
What Each Approach Actually Catches
The cleanest way to understand the distinction is to look at specific failure categories.
| Failure Type | Automated Code Review (Static Analysis) | Automated Testing (Dynamic) |
|---|---|---|
| Style and formatting bugs | Catches (primary purpose) | Not applicable |
| Known security anti-patterns (hardcoded secrets, injection vectors) | Catches | Partial (only if a test exercises that path) |
| Structural complexity and dead code | Catches | Does not catch |
| Functional logic bugs (wrong output for valid input) | Rarely catches | Catches (unit/integration tests) |
| Integration failures (two modules break when combined) | Does not catch | Catches (integration tests) |
| Performance regressions under real load | Flags potential issues only | Catches (performance/load tests) |
| Visual regressions | Does not catch | Catches (visual regression testing) |
| User flow breaks (multi-step interactions) | Does not catch | Catches (E2E tests) |
| State-dependent bugs (behavior changes based on DB/session state) | Does not catch | Catches (E2E with proper state setup) |
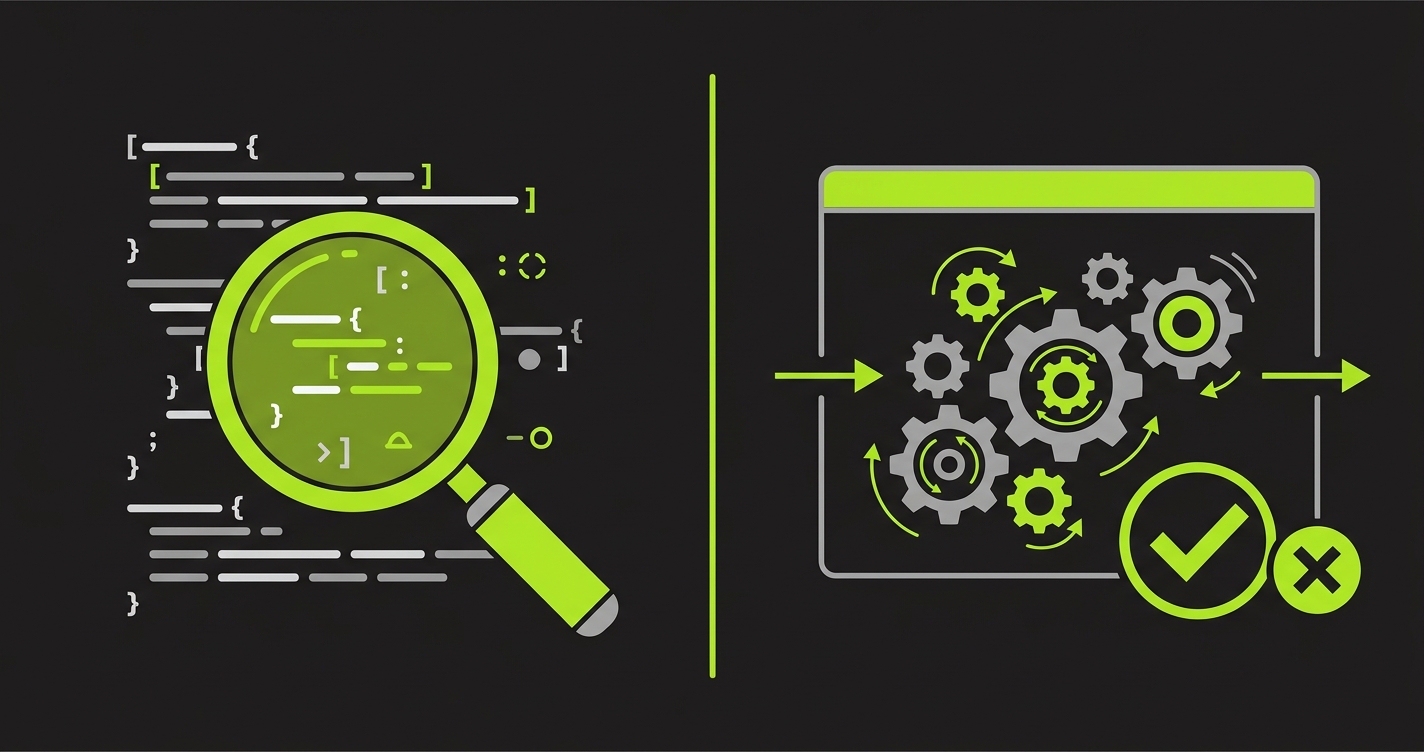
The pattern is clear. Code review tools are excellent at evaluating code in isolation. Testing tools are the only way to verify behavior at runtime. These are not redundant; they are complementary, covering almost non-overlapping classes of bugs.
The checkout discount bug from the introduction? No static analysis tool would flag it. The logic for updating cart state after applying a coupon is syntactically valid. It uses no known anti-patterns. It simply has an incorrect conditional that only manifests when two specific user actions occur in a specific order. Only a test that exercises that exact sequence can catch it.
Why AI-Generated Code Shifts the Balance Toward Testing
This is the part that changes the strategic calculus for engineering leaders in 2026.
When developers write code manually, they tend to have strong mental models of what they're building. They can often reason through edge cases, even without comprehensive tests. Code review tools compensate for the gaps by flagging patterns the developer might have missed in a second pass.
AI coding tools invert this dynamic. The code arrives fully formed, faster than any human could write it, and the developer often has limited intuition about its internal logic. They didn't work through the algorithm step by step. They described the outcome and the tool produced an implementation. The code may be elegant. It may also be subtly wrong in ways that won't show up in a code review.
Static analysis cannot detect semantic errors in syntactically valid code. A function that adds items to a cart instead of replacing them will pass every linter, every security scanner, and every complexity analyzer. Only a test that checks the cart state after calling the function will catch the bug.
Teams running AI code review tools are finding that those tools excel at catching AI hallucinations at the pattern level: deprecated API usage, known insecure constructs, framework anti-patterns that the AI training data included. That's real value. But the volume of logic errors that pass static analysis is increasing faster than code review tools can address. The solution is more testing, not better linting. Teams ready to close this gap can explore our plans for AI-native E2E coverage that scales with code velocity.
Tool Recommendations by Layer
Here is a practical view of the tooling landscape for each pyramid layer, including setup time estimates and ongoing maintenance expectations.
| Layer | Free Options | Paid Options | Setup Time | Ongoing Maintenance |
|---|---|---|---|---|
| Layer 1: Linting / Formatting | ESLint, Prettier, Ruff, Stylelint | Trunk (paid tiers), Mega-Linter (self-hosted) | 1-2 hours | Very low (update configs on major upgrades) |
| Layer 2: Static Analysis / Code Review | CodeRabbit (free tier), SonarQube Community, Semgrep OSS | CodeRabbit Pro, SonarQube Developer/Enterprise, Semgrep Supply Chain | Half day to 1 day | Low (review flagged patterns, tune rules quarterly) |
| Layer 3: Unit / Integration Tests | Jest, Vitest, pytest, Go test, JUnit | Codecov (coverage reporting), Chromatic (component testing) | 1-2 sprints to meaningful coverage | High (tests break when implementation changes) |
| Layer 4: E2E / AI-Native Testing | Playwright, Cypress (limited), Selenium, Autonoma (free tier) | Autonoma Cloud, Mabl, Sauce Labs | 1-3 weeks for meaningful coverage | High without self-healing; low with AI-native tools |
A few observations worth calling out.
Layer 1 tooling is a one-time investment. Configure it, commit the config, and it runs forever with minimal attention. This is the easiest quality win for any team that hasn't already done it.
Layer 2 is where most teams currently spend their automated code review budget. CodeRabbit in particular has become popular because it provides automated PR review comments without requiring a dedicated QA engineer to read every diff. The free tier is genuinely useful for small teams. The limitation, as discussed, is that it can only catch what's visible in the source.
Layer 3 is where the real maintenance burden lives. Unit and integration tests encode assumptions about implementation details. When the implementation changes -- as it does constantly when AI tools are generating code -- tests break. The engineers who wrote the tests often no longer remember the intent behind specific assertions. The result is test suites full of skipped or deleted tests, covering progressively less of the application.
Layer 4 is the highest-leverage investment for teams that ship to production frequently. An E2E test suite that covers critical user flows will catch regressions that slip through every other layer. The traditional barrier is maintenance: Playwright tests written against specific selectors break every time the UI changes. This is exactly the problem that Autonoma addresses by generating tests from codebase analysis rather than from recorded sessions, and self-healing them as the code evolves.
The Complete Quality Stack by Team Size
The right quality stack depends on where your team is. Here is a practical recommendation for three tiers.
Free tier (early stage, pre-Series A): ESLint and Prettier for Layer 1. CodeRabbit free tier for Layer 2 (add PR review automation without a QA budget). Autonoma free tier for Layer 4: instead of writing and maintaining Playwright tests manually (engineering time you don't have at this stage), let Autonoma generate E2E coverage for your most critical user flows. Skip comprehensive unit tests initially; focus coverage on the five flows that would cause the most damage if they broke in production.
Mid tier (growth stage, dedicated QA or senior engineers): ESLint with custom rules for Layer 1. CodeRabbit Pro for Layer 2 (adds more context-aware review comments, better support for larger diffs). Vitest or Jest for Layer 3 targeting core business logic. Autonoma free tier for Layer 4 to eliminate the E2E maintenance burden as the team scales. The ROI calculation here is straightforward: if engineers spend more than four hours per sprint fixing broken E2E tests, an AI-native testing layer pays for itself. See pricing to compare tiers.
Enterprise (large eng team, regulated environment, or high-release cadence): SonarQube or Semgrep for Layer 2 with custom security rules and compliance reporting. Full unit test coverage targets (80%+) with a dedicated test infrastructure investment. Autonoma Cloud or self-hosted for Layer 4, using the Planner agent to derive test cases from codebase analysis, the Executor agent for running tests against a live preview environment, the Reviewer agent for classifying results, and the Diffs Agent to maintain test cases as PRs change the codebase. At this scale, the test maintenance problem is an engineering capacity problem, and AI-native testing is the structural solution.
The Verdict for AI-First Teams
The question "should we invest in automated code review or automated testing?" has a straightforward answer: both, but weighted toward testing if you're currently underinvested there. For teams focused on AI code quality, the priority is even clearer.
Most teams already have Layer 1 sorted. A meaningful number have Layer 2 covered with CodeRabbit or SonarQube. The gap is almost always Layers 3 and 4. This is where regressions slip to production. This is where the checkout bug from Monday lived.
For continuous testing in AI-accelerated development, the pattern that scales is: automate what's static (Layers 1 and 2), invest deliberately in what's dynamic (Layers 3 and 4), and use AI-native tooling at Layer 4 to keep maintenance from consuming your team as code velocity increases.
The teams that are shipping confidently in 2026 aren't the ones with the most sophisticated linters. They're the ones with the most reliable signal about whether their critical user flows still work after every deploy. Start free and see what Autonoma catches in your first run.
Static analysis tells you the code looks right. Testing tells you the application works. In an era where AI generates code faster than any team can review it manually, the second answer matters more.
Automated code review uses static analysis to inspect source code without running it, catching style violations, known security patterns, and structural issues. Automated testing executes the application against real inputs to verify it behaves correctly at runtime. Code review evaluates how code is written; testing evaluates whether it works.
No. Automated code review and automated testing catch almost entirely different classes of problems. Code review tools (SonarQube, CodeRabbit) excel at identifying patterns in source code. Testing tools (Playwright, Jest) verify runtime behavior. A codebase can pass every static analysis check and still have critical functional bugs that only tests would catch.
For most teams, CodeRabbit is the fastest path to automated PR review without a large setup investment. The free tier handles small teams well. SonarQube is the standard for enterprises that need compliance reporting or custom security rules. Semgrep is excellent if you need to write highly specific rules for proprietary patterns or frameworks.
AI coding tools accelerate code output significantly, which means more code changes per sprint and more potential regressions. At the same time, developers working with AI tools often have less intuition about the internal logic of generated code than code they wrote manually. Both factors increase the value of automated testing: more changes means more regression risk, and less developer intuition means static analysis provides less protection than it used to.
The Quality Pyramid organizes testing and review tools into four layers based on what they catch. Layer 1 is linting and formatting (ESLint, Prettier). Layer 2 is static analysis and code review (SonarQube, CodeRabbit). Layer 3 is unit and integration tests (Jest, pytest, Playwright). Layer 4 is E2E and AI-native testing (Autonoma). AI tools have largely automated Layers 1 and 2. The strategic gap for most teams is Layers 3 and 4.
Playwright is the right choice when you have engineers with bandwidth to write and maintain test scripts, your UI is relatively stable, and you're comfortable owning the test infrastructure. AI-native testing tools like Autonoma are the right choice when your team is shipping at high velocity, your UI changes frequently, or you're finding that E2E test maintenance is consuming a significant share of engineering time.



