
AI code review tools are static analysis systems that use machine learning to identify issues in a pull request before it merges. They read code as text, flag patterns that look wrong (security vulnerabilities, style violations, dead code, high complexity), and leave comments in the PR. The best ones, CodeRabbit, Sourcery, GitHub Copilot review, Codium, and Amazon CodeGuru, have become genuinely useful teammates in the AI-assisted development era. But they share a fundamental architectural constraint: they read code, they don't run it. This means AI code review tools reliably catch a class of problems that are visible in the source. They cannot catch a different class of problems that only appear at runtime: functional bugs, integration failures, race conditions, and the subtle ways that business logic misbehaves when real inputs hit real state. AI-generated code has a bug profile that skews heavily toward this second class. Understanding that distinction is the whole game.
A team I spoke with recently had CodeRabbit on every PR. Their AI coding agents were shipping features fast. The review bot was catching style issues and the occasional security pattern. The engineers felt covered.
Then a payment flow started failing for users with a specific combination of currency and account type. The code had passed review. It looked correct. The logic was clean and the patterns were right. The bug was functional: a conditional branch that appeared to handle the edge case but evaluated in the wrong order when account metadata was missing. No static reader would have flagged it. It only appeared when the right inputs hit the running system.
This is not an indictment of code review tools. It is a description of what they are built to do, and more importantly, what they are not. The gap between those two things is widening as AI-generated code becomes the norm.
What Code Review Tools Actually Do
Every AI code review tool, regardless of how it's marketed, is fundamentally a static analysis system with an LLM on top.
The static analysis part reads your code as text. It builds a representation of the program's structure: which functions call which other functions, which variables are declared and used, which patterns match known anti-patterns. The LLM part makes this more flexible. Instead of matching against a rigid rule list, the model can reason about style, intent, and context. It can say "this variable name is misleading" or "this error handling pattern is common but insufficient in async contexts," things a rule-based linter couldn't articulate.
This is genuinely valuable. The problems a good AI code reviewer catches are real problems. Security patterns like SQL injection surfaces, hardcoded credentials, and missing input sanitization. Code quality issues like functions that are too complex, dead code, circular dependencies. Style consistency that a human reviewer might let slip in a hurry. These are worth catching.
The constraint is architectural. Reading code tells you what the code says. It does not tell you what the code does when it runs. Those are related but different questions. A function can say exactly the right thing and do exactly the wrong thing, depending on the state it encounters at runtime.
The Bug Profile of AI-Generated Code
Here is what makes AI code generation a specific problem for code review tools.
Human developers write bugs that look like bugs. Typos, off-by-one errors, forgotten null checks, logic inversions. These are often visible in the source. A reviewer reading carefully will catch a meaningful percentage of them, and a static analysis tool will catch some fraction of what a human reviewer catches.
AI-generated code has a different bug profile. The code is syntactically correct. The style is consistent. The patterns are recognizable. An AI model trained on millions of repositories knows how code is supposed to look, and it produces code that looks right. The bugs are not visible as bugs.
What actually goes wrong in AI-generated code tends to be functional: the condition is evaluated in the wrong order. The retry logic works correctly in isolation but doesn't account for the state the calling function has already modified. The pagination logic handles the happy path but drops the last item when the total is an exact multiple of the page size. The caching layer is correct but invalidates on writes to the wrong key.
None of these bugs look wrong to a static reader. The code is coherent. The reviewer sees a valid function with appropriate error handling and leaves an approving comment. The bug is invisible until the specific runtime conditions that expose it occur in production.
This is the review-test gap, and it is widening. The better AI gets at writing clean-looking code, the less visible the bugs become to static analysis, and the more the detection burden shifts to execution-based testing. It is exactly this gap that we built Autonoma to close: read the codebase, generate tests from what the code is supposed to do, and execute them against the running application before the PR merges.
AI Code Review Tool Comparison: Five Tools, Compared Honestly
These are the main players in AI-assisted code review. Each has genuine strengths. Each has the same fundamental blind spot.
CodeRabbit is the broadest tool in the category. It reviews PRs across most major languages, integrates with GitHub and GitLab, and generates contextual comments that go beyond rule-matching. It understands the diff in relation to the codebase context, so comments reflect what the changed code is doing in context rather than in isolation. False positive rates are lower than older static analysis tools, and the security pattern detection is solid. It is the strongest general-purpose option for teams that want AI review without specializing.
Sourcery started as a Python refactoring tool and has grown into a code review assistant with genuine depth in Python-specific patterns. If your stack is Python-heavy, Sourcery's suggestions are often more actionable than CodeRabbit's because they understand Python idioms at a deeper level. It integrates with pre-commit hooks and IDEs as well as PR workflows, which means it can catch issues before they even reach review. The tradeoff is obvious: for polyglot teams, it doesn't cover the full surface.
GitHub Copilot review benefits from being native to the environment where most teams already work. The integration friction is zero. The convenience is real. The depth, however, is shallower than dedicated review tools. Copilot review works best for catching obvious issues quickly, not for the nuanced security or architectural analysis that CodeRabbit or Sourcery do well. For teams already on GitHub Copilot for code generation, it's a reasonable addition. For teams that want serious code review AI, it's a starting point rather than a destination.
Codium (Qodo) is the most interesting tool in the category because it explicitly acknowledges the review-test gap. It doesn't just review code: it suggests tests as part of the review output. This is a meaningful architectural difference. When Codium reviews a PR, it can flag that a function lacks test coverage for a specific branch and propose a test case. This doesn't solve the gap, but it is the only tool in the category that treats test coverage as a review dimension rather than a separate concern.
Amazon CodeGuru is purpose-built for Java and Python in AWS environments. It combines static analysis with ML models trained on Amazon's internal codebase, which gives it strong coverage of patterns that appear in AWS-adjacent code. The security detector component is particularly good at identifying patterns specific to AWS service integrations. The limitation is the same one that always applies to AWS-specific tooling: it is most valuable when your entire stack is on AWS, and the value drops sharply outside that context.
| Tool | AI Depth | Languages | PR Integration | Security Scanning | False Positive Rate | What It Cannot Catch | Pricing |
|---|---|---|---|---|---|---|---|
| CodeRabbit | High - contextual, diff-aware | Broad (most major languages) | GitHub, GitLab, Bitbucket | Good - pattern-based | Low | Runtime behavior, integration failures, business logic edge cases | Free tier; Pro from $12/seat/mo |
| Sourcery | High - Python-native reasoning | Python-focused, some JS | GitHub, GitLab, IDE plugins | Moderate | Low (Python); higher elsewhere | Runtime behavior, cross-service integration, functional correctness | Free for open source; paid from $12/seat/mo |
| GitHub Copilot Review | Moderate - surface-level | Broad | Native GitHub (best-in-class) | Basic | Moderate | Architectural issues, deep security patterns, functional bugs | Included in Copilot ($10-19/mo) |
| Codium / Qodo | High - review + test suggestion | Broad (JS, TS, Python, Java) | GitHub, GitLab | Good | Low-moderate | Actual test execution, integration behavior, end-to-end flows | Free tier; Teams from $19/seat/mo |
| Amazon CodeGuru | High - AWS-context-aware | Java, Python | GitHub, CodeCommit, Bitbucket | Excellent (AWS patterns) | Low (within AWS patterns) | Non-AWS integrations, runtime state, user flow behavior | Pay-per-use (~$0.75/100 lines reviewed) |
| Autonoma | High - codebase-first, executes tests | Broad (any web application) | GitHub, GitLab CI pipelines | Functional + regression (runtime) | N/A (tests real behavior) | Static patterns, style issues (pair with a code review tool) | Free tier; paid plans from $56/mo |
The "What It Cannot Catch" column is the same for the first five tools. Different words, same category: anything that requires executing the code to observe. Autonoma is the inverse. It doesn't read your code for style or security patterns. It reads your codebase to understand what your app does, generates test cases from your routes and components, and executes them against your running application. The things the review tools miss are exactly what Autonoma catches. The things Autonoma doesn't cover are exactly what the review tools handle. That complementary fit is deliberate.
Why the Gap Is Wider for AI-Generated Code
The review-test gap is not new. Human-written code has always had bugs that only appear at runtime. What is new is the ratio.
When a human developer writes a function, the visible-to-static-analysis bugs and the runtime-only bugs are roughly correlated. Code that looks sloppy often behaves sloppily. Code that looks careful often behaves carefully. This correlation is imperfect, but it is real enough that code review has been a meaningful quality gate for decades.
AI-generated code decouples appearance from behavior. A model optimizes for producing code that looks correct to a reader. It has been trained on human feedback that rewarded clean, readable outputs. The result is code with a high cosmetic quality floor and an unpredictable functional quality ceiling.
This means the signal that code review tools rely on, "does this code look right," is weaker for AI-generated code than for human-generated code. The code usually looks right. The question is whether it behaves correctly, and that question requires running it.
The shift left testing strategy that worked for human-velocity codebases doesn't automatically extend to AI-velocity codebases. The test coverage per PR needs to increase as the cosmetic reliability of code increases and its functional reliability becomes harder to assess from reading. This is explored in depth in the relationship between automated code review and testing, but the core tension is straightforward: AI-generated code demands more execution-based verification, not less.
Code Review vs Testing: What Each Actually Catches
It is worth being precise about the categories here, because the distinction matters for building a complete quality strategy.
Code review, AI or otherwise, is effective at catching issues that are visible in the source text. Security patterns like injection surfaces, missing authentication checks, and hardcoded credentials. Code quality issues like duplicated logic, overly complex functions, and dead code. Style and consistency violations. Known anti-patterns in the language or framework. Dependency issues that create risk. These are real problems, and catching them in review is genuinely better than discovering them in production.
Testing catches what code actually does when it runs. Functional correctness across input ranges. Integration behavior when services call each other. User flow integrity from entry to completion. Race conditions in concurrent code. Edge cases in business logic where boundary conditions interact with state. Database behavior under realistic data. Performance characteristics under realistic load.
The overlap between these categories is small. A bug that appears in both, visible in the source and observable at runtime, is usually caught in review. The interesting bugs for AI-generated code are in the second category only: invisible to reading, visible only when the code runs.
For teams that want to understand the full testing tools landscape, the takeaway is that code review tools and testing tools are not alternatives. They address different bug classes. Treating them as substitutes is what creates the gap. Autonoma exists specifically to cover the runtime bug class that code review tools cannot reach. It reads your codebase to derive what to test, then executes those tests against your running app. Teams ready to close the gap can explore our plans for codebase-first E2E testing.
Building the Complete Stack
The right framing is not "code review versus testing." It is "code review and testing, at the right layer."
CodeRabbit is excellent at what it does. Use it. Let it catch the security patterns, the style drift, the dead code, the complexity warnings. These are real value adds, especially in AI-assisted codebases where the pace of PR creation can outrun manual reviewer attention. The tools in this category have earned their place in the workflow.
The question is what you put alongside them. A code review tool that flags a missing null check is doing its job. A testing layer that runs the code and discovers that the null check was present but evaluated after a variable was already dereferenced is doing a different job. You need both.
For teams generating code with AI agents at high velocity, the testing layer needs to match that velocity. Manual test authorship doesn't scale to 30 AI-generated PRs per week. The functional coverage gap grows faster than a human QA team can close it.
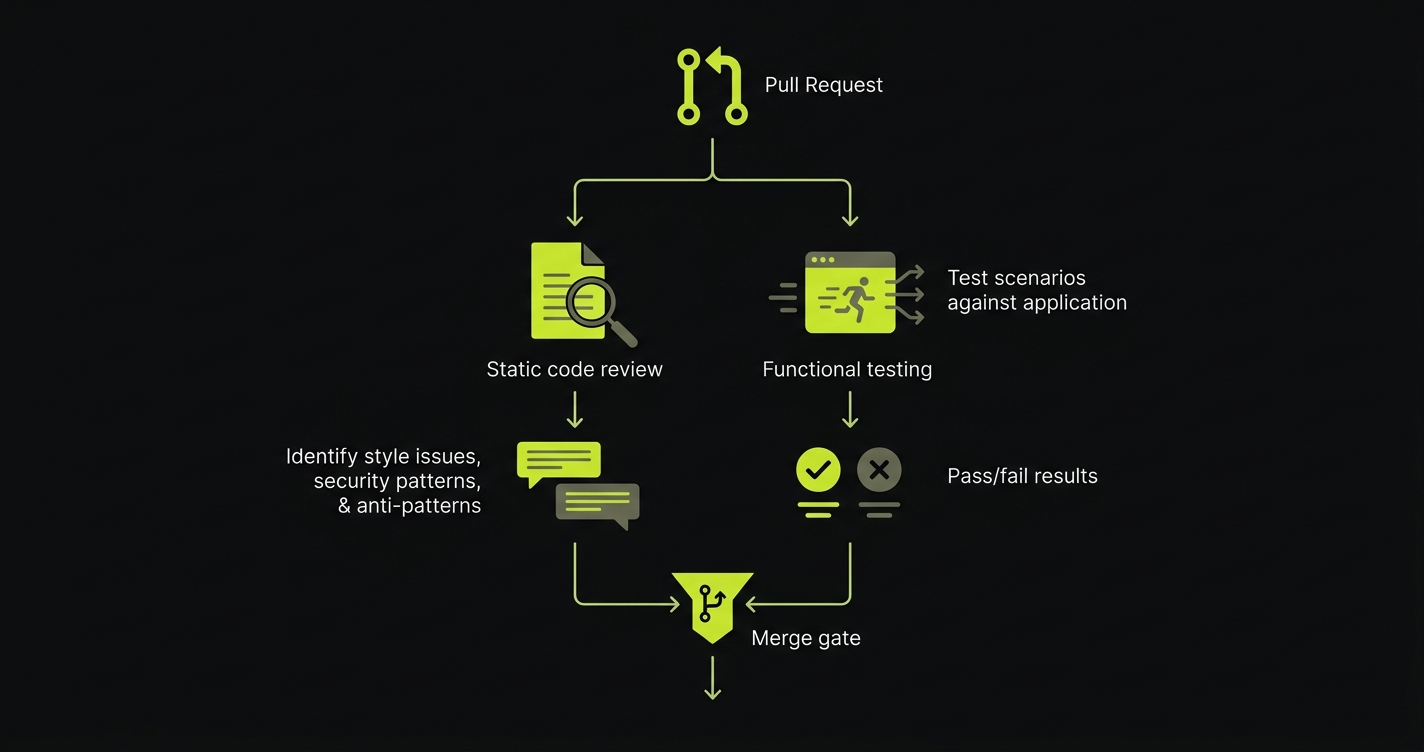
This is where we built Autonoma to complement the code review layer rather than replace it. Code review tools read your PR and say "this looks wrong." Autonoma reads your codebase, plans test cases from your routes and components, and executes them against your running application to say "this doesn't work." CodeRabbit catches the visible problems. Autonoma catches the runtime ones. Together they address the full bug class distribution that AI-generated code produces.
The Planner agent reads your code to understand what your application is supposed to do. The Automator agent runs those scenarios against your actual deployment. When your code changes, the Maintainer agent keeps the tests current. No recording, no scripting, no maintenance overhead. The verification runs automatically in your CI pipeline alongside the code review bot, and both leave their findings before the PR merges. See pricing to compare tiers.
The Verdict
AI code review tools are genuinely useful, and they are not enough on their own. This is not a criticism. A smoke detector is genuinely useful, and it is not a substitute for a fire suppression system. The tools are right for their category.
The problem is misclassifying what the category is. Teams that treat code review AI as their primary quality gate for AI-generated code are getting strong coverage on the bug class that was already less common in AI-generated code (visible style and pattern issues) and weak coverage on the bug class that is most common (functional failures that only appear at runtime).
The correct stack for 2026 teams shipping AI-generated code is:
A code review tool (CodeRabbit, Sourcery, or Codium depending on your stack) for the static layer, catching security patterns, style drift, and anti-patterns before the PR merges. And Autonoma for the functional layer, reading your codebase to generate tests and executing them against your running application to catch the runtime bugs that no static reader can see. The code review tool comments on the PR. Autonoma's test results land alongside those comments. Both clear before the merge button turns green.
Code review tells you the code looks right. Testing tells you the code works. Right now, AI generates code that almost always looks right. Whether it works is a different question, and it requires a different kind of answer. Start free and let Autonoma show you what your code review tool missed.
AI code review tools perform static analysis augmented with LLMs. They check for security patterns (SQL injection surfaces, hardcoded credentials, missing input sanitization), code quality issues (high cyclomatic complexity, dead code, circular dependencies), style consistency, known anti-patterns in the language or framework, and in some cases test coverage gaps. What they do not check is runtime behavior. They read code as text, not as a running program. This means they cannot detect functional bugs that only appear when specific inputs hit specific state, integration failures between services, race conditions, or business logic errors that produce wrong outputs for edge case inputs. For AI-generated code specifically, the functional bug class is disproportionately important because AI models produce code that looks correct to a static reader but may behave incorrectly at runtime.
Yes, with the right expectations. CodeRabbit is one of the better tools in the AI code review category because of its contextual, diff-aware analysis and low false positive rate. For AI-generated code, it will catch real issues: security patterns, style drift, complexity problems, and anti-patterns. What it will not catch is the functional bug class that is most characteristic of AI-generated code, the bugs that are invisible to a static reader and only appear when the code executes. Teams using CodeRabbit for AI-generated PRs should treat it as the static analysis layer and pair it with a functional testing layer that executes the code. CodeRabbit handles the visible problems; execution-based testing handles the runtime ones.
No. AI code review and testing address fundamentally different bug classes and should be treated as complementary rather than alternative strategies. Code review catches issues visible in source code: security patterns, style violations, dead code, anti-patterns. Testing catches issues that only appear when code executes: functional correctness, integration behavior, race conditions, user flow failures, edge cases in business logic. The overlap between these categories is small. For AI-generated code specifically, the runtime bug class is disproportionately large because AI models produce code that looks correct but may behave incorrectly. Replacing testing with code review in an AI-assisted codebase creates exactly the coverage gap where the most characteristic AI-generated bugs live.
The review-test gap is the category of bugs that pass code review but fail in testing. These are bugs that are invisible to a static reader because the code looks correct, but cause incorrect behavior when executed with real inputs against real state. Examples include: a conditional branch that evaluates in the wrong order when a specific data combination is present, pagination logic that drops the last item when the total is an exact multiple of page size, caching logic that invalidates on the wrong key under concurrent writes, retry logic that fails to account for state modified by the calling function. The review-test gap exists in all codebases, but it is wider for AI-generated code because AI models are optimized to produce code that looks correct. The cosmetic quality is high; the functional quality requires execution to verify.
Codium (now Qodo) is unique in the code review category because it explicitly addresses the review-test gap by suggesting tests as part of the review output. When reviewing a PR, Codium can identify functions with insufficient branch coverage and propose test cases for the missing scenarios. This is a meaningful architectural difference from tools that only comment on the source code. The limitation is that Codium suggests tests but does not execute them automatically against your running application. It narrows the review-test gap by prompting test creation; it does not close it by running functional verification. Teams using Codium for test suggestions still need a functional testing layer that executes the proposed tests and catches runtime behavior.



