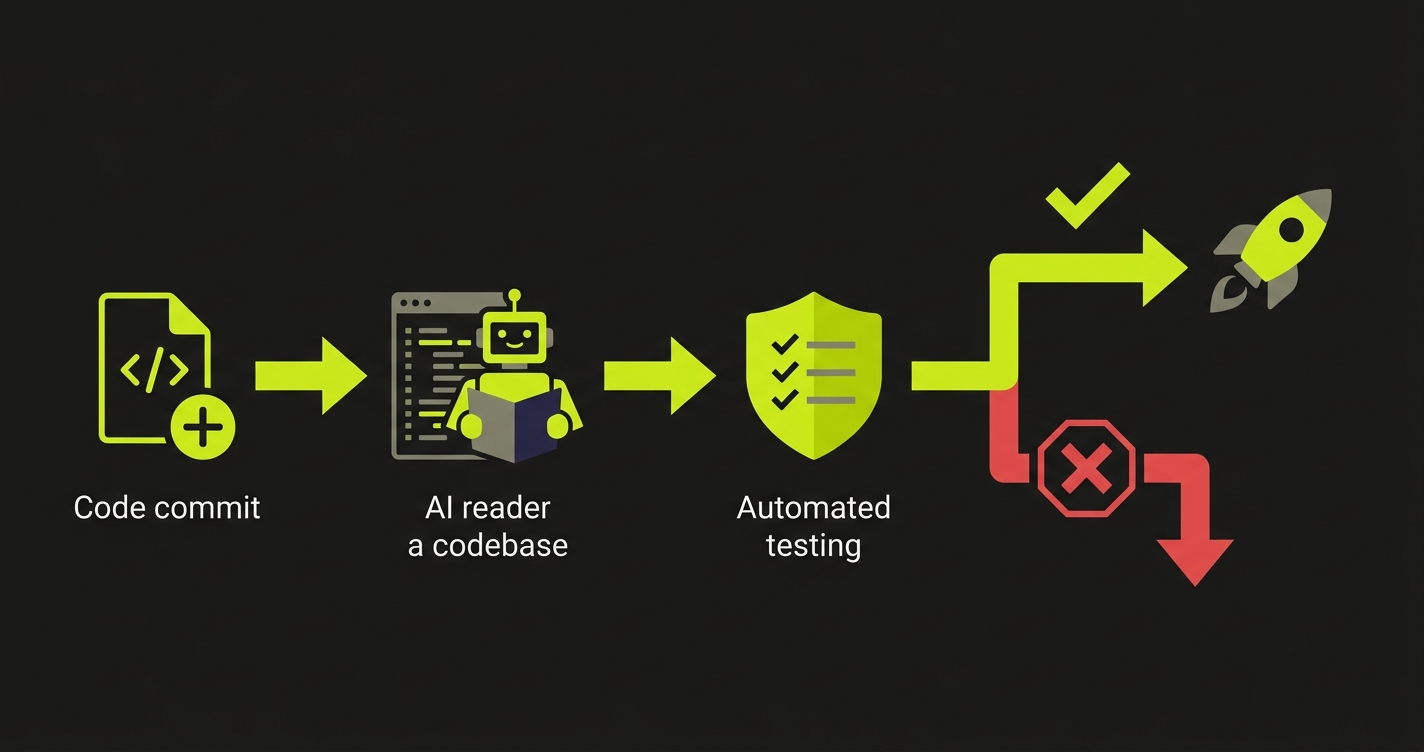
TLDR: NXTP Demo Day is 6 weeks out. You have 2-3 enterprise pilots running with LatAm banks, retail chains, or telecoms. One bug in front of a conservative corporate IT team sets your relationship back 3-6 months, not 3-6 days. This post explains how to get test coverage on the exact paths your pilot customers walk, automatically, so you ship features fast without breaking the deals you're trying to close.
The timeline every NXTP founder is doing math on right now
Six weeks. That's the window between today and the moment you walk onto the NXTP Demo Day stage and tell a room of investors that you have paying customers, signed pilots, and a LatAm enterprise willing to expand.
That window creates a specific kind of pressure. You're still shipping. You have to ship. The enterprise customer you're piloting with has a list of requirements that came out of three procurement meetings, and if you don't hit those requirements before Demo Day, the deal doesn't close in time to count. So you push code. You add features. You move fast because that's the job.
But the companies in your pilot are not the kind of companies that tolerate bugs with grace. A Banco Galicia, a Falabella, a Claro. Organizations with IT departments that have seen vendors fail before. When a bug surfaces in a pilot with one of these companies, the call you get is not a friendly Slack message from a startup-savvy product manager. It's a formal escalation from an IT director to your champion, who now has to explain to their boss why they approved onboarding an unstable product.
That's the setup. Here's the tension: the thing you need to do to close the deal (ship fast) is the same thing that creates the risk that kills the deal (introduce bugs). And the consequence of a bug in LatAm enterprise sales is not a brief delay. It is months.
Therefore: you need a way to ship fast and keep the pilot paths stable. The solution is narrow, targeted test coverage on exactly the flows your pilot customers use, running automatically every time you deploy.
Why LatAm enterprise bugs cost more than US bugs
This is worth stating directly because it shapes how you should think about risk.
In a US or EU SaaS context, a bug in a pilot is a problem you can often recover from quickly. Your champion is usually a product-minded person inside a startup-culture company. They file a bug report, you fix it same day, you send a quick apology, and the relationship continues. The trust recovery timeline is measured in hours or days.
In LatAm enterprise sales, the trust recovery timeline is measured in months. Here's why.
LatAm B2B sales cycles are relationship-driven in a way that US SaaS cycles often are not. Your champion put their reputation on the line to get you into the building. They had conversations with their manager, their IT team, their security officer. They vouched for you. When a bug surfaces, the damage is not just to your product's credibility. It is to your champion's internal credibility. And when your champion's internal credibility takes a hit, they become a less effective advocate for your deal. They slow down. They add more approval steps. They start hedging their recommendations.
Add to this the fact that large LatAm corporates often have conservative IT policies. A bank's IT department in Argentina is not going to shrug off an authentication error or a data display bug. They are going to document it. They are going to put it in the vendor evaluation file. They are going to bring it up in the next procurement review.
A bug in front of this kind of customer is not a temporary setback. It is a permanent part of the record of your pilot.
The 6-week math for NXTP portfolio companies
Let's be specific about what the 6 weeks actually look like.
Weeks 1-2: You're still negotiating the final scope of the pilot with at least one customer. You're also shipping features to satisfy requirements from another customer who started their pilot 3 weeks ago. Your team is split across customer success and product development.
Weeks 3-4: You enter what should be the stability phase. This is when pilot customers are supposed to be using the product independently, discovering value, and building the internal case for expansion. This is the phase that turns a "pilot" into a "reference customer" that you can put on your Demo Day slide.
Weeks 5-6: You're in pre-Demo Day mode. You're rehearsing. You're coordinating with NXTP on your presentation. You are desperately hoping your pilot customers don't surface a new issue that your team has to drop everything to fix.
The problem is that almost every NXTP founder I've talked to is still shipping code in weeks 3-4. Not because they want to. Because they have to. A customer found something that doesn't work in their environment. A competitor just launched a feature your customer mentioned. Your onboarding flow has a 30% drop-off and you can see it in the data.
You ship. And when you ship, you risk breaking something.
The three paths that cannot break
Here's the framework that actually works for protecting pilots without having to stop shipping.
You are not trying to achieve 100% test coverage. You are trying to identify the three to five flows that, if broken, immediately surface in front of your pilot customer and trigger an escalation. Everything else is secondary. Write those flows down. They are probably:
Authentication and login. Your pilot customer's employees need to log in every day. If login breaks, every single one of them knows immediately. There is no path to "maybe they won't notice." They will notice. The IT team will get calls. Your champion will get a message before you do.
The core action that delivers value. This is specific to your product. For a B2B SaaS tool, it's the action that the customer's user performs to get the output they care about. For a fintech, it might be initiating a transaction. For a logistics tool, it might be generating a route or a manifest. For a compliance platform, it might be running a document scan. Whatever the action is, if it breaks, the pilot stops delivering value. The customer notices within hours.
The output your customer sends to their own stakeholders. Many B2B products produce something that the customer's users then forward internally. A report, a dashboard, an export, an email. If that output breaks or shows wrong data, the bug doesn't stay inside the pilot. It propagates into your customer's internal communications. This is how a single bug becomes a multi-team incident.
Those three categories. Map them to the specific flows in your product. Then make sure those flows have automated coverage that runs on every deploy.
What "every deploy" means in practice
Here's a code-level example of what a critical path test looks like. This is the kind of test you want running in CI every time you push:
import { test, expect } from '@playwright/test';
test.describe('Pilot critical path: document compliance scan', () => {
test('user can upload document and receive compliance report', async ({ page }) => {
// Step 1: Auth
await page.goto('/login');
await page.fill('[data-testid="email"]', process.env.PILOT_TEST_USER_EMAIL!);
await page.fill('[data-testid="password"]', process.env.PILOT_TEST_USER_PASSWORD!);
await page.click('[data-testid="login-submit"]');
await expect(page).toHaveURL('/dashboard');
// Step 2: Core action
await page.click('[data-testid="new-scan"]');
await page.setInputFiles('[data-testid="upload-input"]', 'fixtures/sample-contract.pdf');
await page.click('[data-testid="start-scan"]');
await expect(page.locator('[data-testid="scan-status"]')).toContainText('Complete', {
timeout: 30000
});
// Step 3: Output quality
const reportTitle = await page.locator('[data-testid="report-title"]').textContent();
expect(reportTitle).not.toBeNull();
await page.click('[data-testid="export-pdf"]');
const download = await page.waitForEvent('download');
expect(download.suggestedFilename()).toMatch(/compliance-report.*\.pdf/);
});
});Writing this test manually is straightforward when the product is young. The problem is that most NXTP-stage companies have a product that has evolved significantly since anyone last wrote a test. The flows changed. New components were added. The test would need to be rewritten from scratch, and the team doesn't have the bandwidth to do that in a 6-week sprint.
This is exactly the gap Autonoma fills. It reads your codebase and generates these critical path tests automatically, without you writing a line of test code. You connect your repo, identify the flows that matter, and Autonoma creates the coverage. Then it runs on every deploy.
The 48-72 hour stability window
There is a specific moment in every pilot that founders underestimate. It's the first time your customer's team uses the product without you on the call.
Up until that moment, every session has been either a sales demo or an onboarding call where you're there to catch and explain away any issues. But at some point, your champion says "okay, I think we've got it, I'll have my team start using it this week," and you get off the call.
That first solo session, usually 48-72 hours after the last guided session, is when the product has to stand on its own. If something breaks in that window, the customer doesn't have the context to know if it's a known issue, a temporary problem, or a sign that the product isn't ready. They have no one to ask. They just see a broken product.
For NXTP portfolio companies, this window is especially critical because the customers are enterprise organizations. Their users are not going to spend 20 minutes troubleshooting. They are going to close the tab, send a message to their manager saying the tool didn't work, and wait for instruction. That message travels fast inside large organizations.
The protocol for this window: do not deploy anything in the 48 hours before a pilot customer's first solo session unless you have confirmed test coverage on all three critical paths. Lock the deployment window. If a bug surfaces during this time, the cost of shipping a fix without test validation is higher than the cost of waiting.
How this shows up in investor diligence
NXTP's portfolio companies raise follow-on rounds, and those rounds involve diligence on the customer base. Here's something that most early-stage founders don't think about until they're in a data room: your reference customers talk to investors.
When an investor calls your pilot customer as part of diligence, they are not just asking "is this product valuable." They are asking "is this product reliable." They are asking about specific incidents. They are asking whether the team is responsive and whether the product has improved over the course of the pilot.
A pilot that was stable and delivered consistent results tells a much better story than a pilot where the customer has to say "yes, we love the direction, but we had a few bugs in the middle that were frustrating." Even a small number of stability incidents can downgrade a reference customer from "strong yes" to "cautiously optimistic," and that difference shows up in how the investor prices the round.
Stability is not just a product quality metric. It is a fundraising asset.
The "protect the deal" framework in practice
Here's the operational version of everything above, distilled to a checklist you can run in the next week.
| Step | Action | Owner | Timeline |
|---|---|---|---|
| 1 | Map the 3 critical paths for each active pilot | Founder / CTO | Day 1-2 |
| 2 | Generate automated tests for each path | Engineering (with Autonoma) | Day 2-4 |
| 3 | Add test suite to CI pipeline, run on every deploy | Engineering | Day 4-5 |
| 4 | Identify the 48-hour window before each customer's first solo session | Founder | Day 1-2 |
| 5 | Implement deploy freeze policy for those windows | Founder / CTO | Day 3 |
| 6 | Review test results before each customer milestone | CTO | Ongoing |
The goal is not to test everything. The goal is to make it impossible to accidentally break the thing your customer relies on.
Why this matters more now than it did 6 months ago
NXTP's portfolio has been pushing into larger enterprise customers over the past two years. The average deal size in the portfolio has grown. The average buyer sophistication has grown. The average IT governance requirement has grown.
Six months ago, many NXTP-stage companies were doing smaller pilots with more forgiving customers. A bug was recoverable with a quick fix and a phone call. Today, more of the portfolio is piloting with companies that have formal vendor evaluation processes, where a stability incident goes into a written record.
This is the market maturing. LatAm enterprises are becoming more sophisticated buyers. They expect the same stability guarantees from an early-stage startup that they would expect from a larger vendor. They are not going to make exceptions for your stage.
The companies that will close the most enterprise deals in the next 12 months are the ones that figured out how to ship fast and stay stable at the same time. That is the operational challenge in front of every NXTP founder right now.
Automated testing on the critical paths is the direct solution to that challenge. Not because testing solves all problems, but because it makes sure that the most important paths stay working while you continue to ship everything else.
FAQ
If you have a pilot customer from a LatAm enterprise, you are already past the point where this matters. The moment a customer's team is logging in and using your product independently, a bug is not a development issue. It is a customer relationship issue. The investment in critical path coverage pays off the first time a deploy breaks something and the test catches it before the customer sees it.
For most startups with a standard web application, you can have critical path tests generated and running in CI within a day. Autonoma reads your codebase and generates the tests automatically. You review them, make adjustments if needed, and connect them to your deployment pipeline. The upfront investment is measured in hours, not weeks.
This is exactly the right question to ask. The answer is to create a test environment that mirrors the customer's configuration as closely as possible, and run your critical path tests against that environment. It does not need to be perfect. It needs to cover the three critical paths: auth, core action, output. Autonoma can generate tests that work against a staging environment configured to match your customer's setup.
You have three options: fix it immediately if it's small, delay the feature release and keep the customer on the stable version, or communicate proactively with your customer before they discover it. The worst outcome is always the customer discovering the bug themselves. A proactive 'we caught something and we're fixing it' message actually builds trust with LatAm enterprise buyers, because it signals that you have quality controls in place.
Autonoma focuses on end-to-end testing for web-based products, which covers the majority of B2B SaaS applications in the NXTP portfolio. If your product has a web interface that your customers interact with, Autonoma can generate coverage for it. For mobile-first or API-only products, the scope of what's covered differs, but the pilot path protection framework still applies.
Yes. That's the core value proposition. Autonoma generates the test code from your codebase. You do not need to write tests yourself. Your engineers review the generated tests for correctness and connect them to CI. The requirement is not testing expertise. It is understanding which paths in your product your pilot customers actually walk.
What Autonoma Does for NXTP-Stage Teams
LatAm enterprise trust is expensive to build and fast to lose. A Banco Galicia or a Claro that vouched internally for your product has placed a reputational bet on your team. A bug during the pilot is not a temporary setback. It is a permanent entry in the vendor file, referenced in every future procurement review. And the problem is sharpest in the six weeks before Demo Day, when you are shipping code every day into the most fragile window of the customer relationship.
Autonoma generates E2E coverage from your actual codebase automatically, reading your routes, your components, the flows your enterprise customers walk. The team does not choose between shipping features and protecting pilots. Both happen in parallel because the coverage is generated and maintained without engineering overhead.
For LatAm enterprise accounts, the CI gate is what matters. Regressions are blocked before they ship, not discovered by a bank's IT department three days after the deploy. The difference between those two outcomes is the difference between a clean pilot record and a formal escalation that your champion has to explain to their manager.
The tests stay current as the codebase evolves. During a 6-week sprint, your product is changing daily. Autonoma's coverage keeps up with no maintenance overhead and no stale tests that pass while real paths break.
The LatAm enterprise relationship you spent 8 weeks building should not end because of a regression that a 2-hour setup would have caught.