
Frontend-only previews are per-PR temporary URLs serving the built frontend of a pull request against a shared or absent backend. Full-stack preview environments are per-PR isolated runtimes containing the complete application stack: frontend, backend API, database, queues, caches, and workers. The difference is not a feature gap between vendors. It is a category distinction. Seven classes of bugs live exclusively in the gap between them.
Vercel and Netlify preview deployments are genuinely good at their job. A PR opens, a URL appears, a reviewer clicks through the UI changes before approving. That feedback loop has made frontend-only previews one of the most widely adopted developer workflow features of the last decade. Most teams shipping React or Next.js apps have them. Many teams believe they cover preview-based validation entirely.
They don't. Not because these platforms are deficient, but because frontend-only previews operate at a different layer than full-stack preview environments. The scope boundary is intentional and well-defined. What falls outside that boundary is a distinct category of infrastructure with distinct bug-catching properties.
This article names the seven bug classes that live in the gap, explains why each is a structural property of frontend-only scope rather than a fixable limitation, and frames the category distinction that separates preview deployments from full-stack preview environments.
What Frontend-Only Previews Do Well
Before cataloging what they miss, it's worth being precise about what frontend-only previews actually do. A Vercel preview deployment builds your frontend per pull request, deploys it to a CDN-backed URL, and posts that URL to the PR. Netlify deploy previews follow the same pattern. Serverless functions on both platforms extend this slightly, but the backend layer (your API, your database, your queues) is not provisioned per PR. It runs somewhere else: usually a shared staging backend, or in some cases production.
For purely cosmetic changes, this coverage is complete. Color, copy, layout, client-side animations, responsive behavior: all of these are visible in a frontend preview. The feedback loop is fast, the URL is shareable, and no backend infrastructure work is required.
The scope ceiling becomes visible the moment a PR touches anything below the frontend layer.
If you're sizing how many of these seven bug classes your current preview setup catches, our co-founder Eugenio is happy to compare notes. Grab 20 min with a founder
Bug Class 1: Backend Logic on the Diff
The most common blind spot. A PR modifies an API endpoint: a new validation rule, a changed response shape, a fixed authorization check, a new field in the payload. The frontend preview shows the UI rendering correctly against the old backend. The new backend behavior is never exercised.
Consider a PR that tightens an authorization rule to reject requests from users without a verified email. The frontend preview loads, the reviewer clicks through the UI, and everything looks fine: the frontend is talking to the shared staging API, which still runs the old authorization code. The PR merges. The migration runs. The new authorization logic goes live. Users with unverified emails who previously had access are now locked out. No one caught it in review because the diff's backend logic never ran in the preview environment.
Frontend-only previews cannot catch this class of bug by construction. There is no per-PR isolated backend process. Service replication is not part of the scope.
Bug Class 2: Real Database Shape Bugs
A PR adds a column, drops an index, changes a constraint, or introduces a migration that assumes a specific data state. The migration looks correct in code review. What code review cannot see is how the migration behaves against real data: the rows already in the table, the foreign key relationships, the enum values that have accumulated over the application's lifetime.
Frontend-only previews have no opinion about the database. There is no isolated database instance per PR, no branched schema, no migration run against a copy of real data. If the migration has a problem, it surfaces in the shared staging database (if someone thinks to run it there), or it surfaces in production.
Full-stack preview environments provision an isolated database instance per PR, apply migrations against that instance, and optionally seed it with representative data. The migration runs before the PR is approved. If it fails or corrupts a foreign key relationship, that failure appears in the per-PR environment, not in production.
Bug Class 3: Side Effects in Service Replication
Most non-trivial applications have more than one backend service: an API server, a background job runner, a notification service, an internal admin API. A change to one service often has side effects on another. A PR that modifies the notification service's retry logic may cause the job runner to enqueue duplicate events under specific timing conditions. A PR that changes the admin API's permission model may break assumptions the main API makes about shared session state.
Frontend-only previews provision none of these services per PR. Service replication does not happen. The services that run alongside the frontend are the shared staging instances, or production, running code that predates the PR. Side effects that only appear when the changed service interacts with other services in the diff are invisible.
Full-stack preview environments replicate every service defined in the application's service manifest, per PR. When the notification service and the job runner both run against the PR's code, timing-dependent side effects surface before merge.
Bug Class 4: Queue State Without Per-PR Orchestration
Applications that use message queues (Redis, RabbitMQ, SQS, Kafka) have a specific class of bugs that only surface when the queue is in a particular state. A PR changes the consumer logic for a queue. The frontend preview has no queue. The shared staging queue, if it exists, is being consumed by other engineers' changes simultaneously. There is no controlled state to test against.
This gap is structural. Without per-PR orchestration of the queue infrastructure itself, tests that exercise queue-dependent behavior are either absent or running against a contaminated shared resource. A consumer that correctly processes a specific message format in isolation may silently drop messages under the queue's actual state in staging.
Per-PR orchestration of queue infrastructure means each preview gets its own queue instance, seeded to a known state. Consumer logic changes run against that controlled state, in isolation from every other open PR.
Bug Class 5: Cache Invalidation Without Secrets and Config Propagation
Cache invalidation bugs are notoriously hard to reproduce because they depend on the cache's state at the moment the code runs. A PR changes the caching strategy for a response: a new cache key pattern, a changed TTL, a new invalidation trigger. The frontend preview has no per-PR cache layer. The shared staging cache has state from other PRs, from other engineers' test runs, from data seeding that happened days ago.
This class of bug compounds with secrets and config propagation. Many caching configurations reference environment variables: cache endpoint URLs, authentication tokens, TTL values. A frontend-only preview does not provision per-PR environment configuration. The PR's cache configuration changes are never exercised with the environment variables they will run against in production.
Full-stack preview environments handle secrets and config propagation per PR: environment variables are scoped to the preview, the cache layer is isolated, and the PR's configuration runs against a cache in a known starting state. Cache invalidation bugs that would silently corrupt data in production surface in the controlled preview.
How Autonoma Closes the Seven Bug Classes
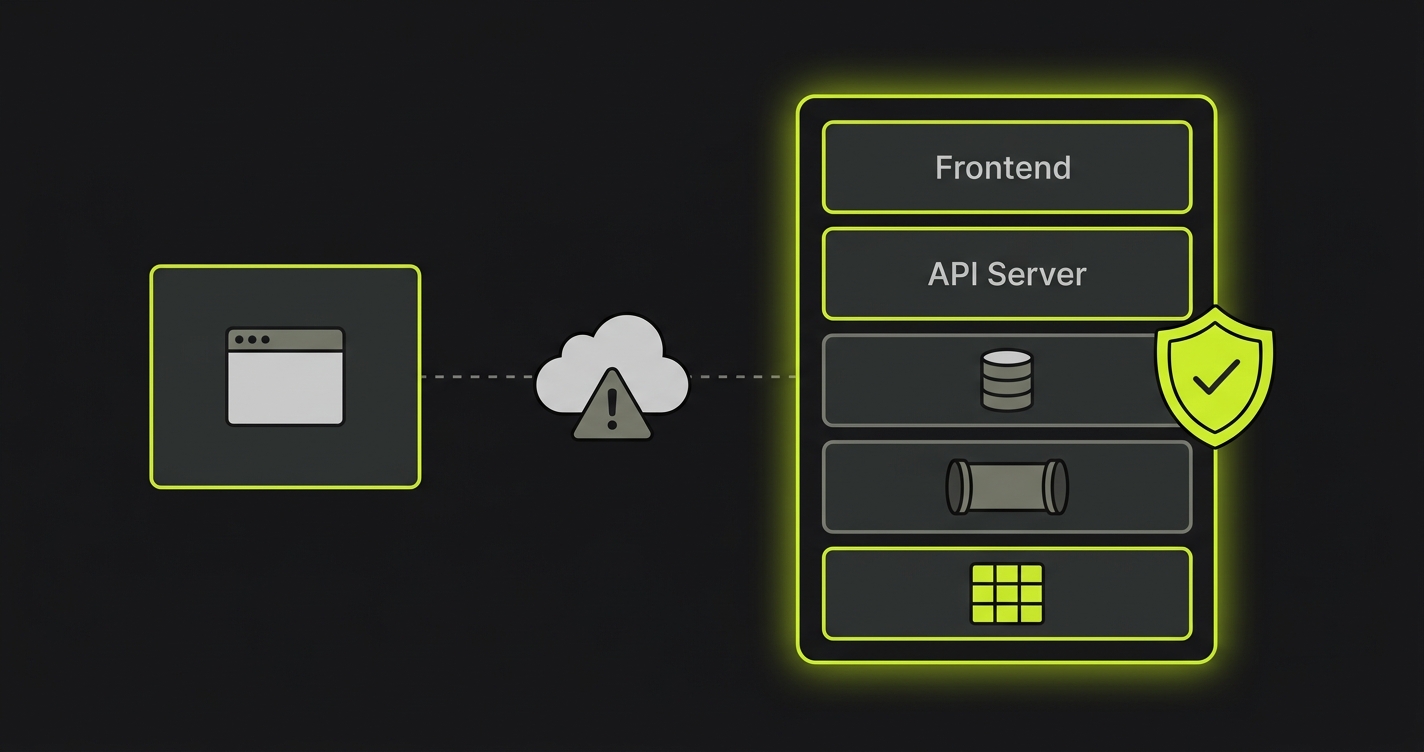
The seven bug classes above share a single root cause: they require a running, isolated, complete application stack to surface. Frontend-only previews cannot provide that by design. The infrastructure that does provide it, per-PR service replication, isolated database instances with migrations applied, per-PR orchestration of queues and caches, and secrets and config propagation scoped to each preview, is the managed preview environment layer. Without it, each of the seven bug classes is invisible until it reaches production.
Autonoma provides managed preview environments that operate this infrastructure out of the box. Layer 1 handles image builds, full-stack service replication, environment routing, secrets and config propagation, database isolation, and teardown per PR. No infra overhead, no bespoke orchestration glue per repo. Layer 2 is the integrated differentiator: Autonoma's Planner reads the codebase and plans E2E test cases against the running preview, the Diffs Agent runs on every PR to add, deprecate, and maintain those tests as the code changes, the Executor runs the planned tests against the live preview, and the Reviewer classifies each result as a real bug, an agent error, or a test-plan mismatch. Preview environments and the tests that run on them ship as one product. The seven bug classes that frontend-only scope cannot catch are the classes that full-stack previews plus integrated E2E testing catch before merge.
Bug Class 6: Third-Party Integration Drift
Applications that integrate with external services (payment processors, identity providers, email platforms, mapping APIs) often have environment-specific configuration: test-mode credentials, sandbox endpoints, webhook secrets. A PR changes the integration logic. In the frontend-only preview, there is no per-PR configuration for the third-party service. The preview either skips the integration entirely (because there are no credentials) or uses the shared staging credentials that other PRs are also using.
Integration drift happens when the PR's changed integration code is never exercised against its own configuration. A payment flow that works correctly with the PR's updated Stripe integration might silently fail when the webhook signature validation changes, because the shared staging webhook secret doesn't match the PR's expected format. No one catches it in preview because the integration never ran with isolated credentials.
Isolated runtime infrastructure per PR includes per-PR propagation of third-party credentials and sandbox configuration. The PR's integration logic runs against its own credentials, in isolation from other PRs' test activity.
Bug Class 7: Cross-Service Races Without Isolated Runtime Infrastructure
Race conditions between services are the hardest class to reproduce and the most consequential to miss. A PR changes the ordering of two concurrent operations: an API write and a background job that reads the same record. Under specific timing, the job reads stale data. This race is not visible in code review. It is not visible in unit tests, which mock the other service. It surfaces only when both services run concurrently against the same data layer.
Frontend-only previews run no backend services concurrently. There is no isolated runtime infrastructure where the API and the job runner execute simultaneously against a shared isolated database. The race condition exists in the PR, remains invisible through review, and surfaces in production under load.
Full-stack preview environments run every service in the application concurrently, per PR, against an isolated database. Cross-service races that require simultaneous execution to manifest have a runtime to surface in before the PR merges.
Frontend-Only vs Full-Stack: A Direct Comparison
| Dimension | Frontend-Only Preview | Full-Stack Preview Environment |
|---|---|---|
| Bug classes caught | UI-layer only (1 of 7) | All 7 classes above |
| Isolation completeness | Frontend assets only | Full stack per PR |
| When it's enough | Pure UI / cosmetic PRs | Any PR touching backend |
| Infra provisioned per PR | CDN deployment only | Services, DB, queues, cache |
| Secrets/config scope | Shared or absent | Per-PR propagation |
Why This Is Not a Vercel Problem
Naming a category boundary is not a criticism of the products that operate within it. Vercel preview deployments and Netlify deploy previews do exactly what they are designed to do: fast, zero-config, per-PR frontend URLs. They serve that job better than almost anything else available. The frontend-only scope is a deliberate product decision, not an oversight.
The category distinction matters because teams often assume that having "previews" means having full-stack validation. That assumption is easy to form when the Vercel UI says "Preview" and the PR gets a green checkmark. The assumption causes teams to skip additional validation steps, to treat the preview URL as equivalent to a staging environment, and to be surprised by post-merge incidents that should have been visible before merge.
The correct frame is: preview deployments are a frontend tool. Full-stack preview environments are an infrastructure tool. They are adjacent categories, not competing products at the same layer. A team using Vercel preview deployments for frontend review and a separate full-stack preview environment platform for backend validation is using both correctly.
The Full-Stack Preview Environments Alternative
Teams that recognize the seven-class ceiling often reach for one of two paths. The first is DIY: run an ephemeral backend server inside a CI job, expose it via a tunnel, wire secrets manually, write teardown scripts. This closes some of the gap. It also absorbs significant engineering time to build, per-repo glue to maintain, and reliability surface to debug when tunnels drop or secrets rotate. Teams that have gone down this path know that the orchestration work expands to fill the available engineering capacity.
The second path is a managed preview environment platform that handles the infrastructure layer as a product. The same per-PR orchestration that is expensive to build in-house (image builds, service replication, environment routing, database isolation, secrets propagation, teardown) is operated by the platform. The team configures the services it wants to preview; the platform handles the rest.
For teams that are currently using frontend-only previews and wondering whether to close the seven-class gap, the decision usually comes down to how frequently their PRs touch backend logic. If most PRs are cosmetic, the current setup may be sufficient. If PRs regularly touch the database, services, queues, or third-party integrations, the seven bug classes above describe the systematic blind spot that the current setup is not catching.
The blind spot is not visible until one of those bug classes produces a production incident. Once it does, the question changes from "do we need full-stack previews?" to "how quickly can we get them."
A frontend-only preview is a temporary URL serving the built frontend of a pull request. The backend, database, and services are either shared with staging or absent entirely. Platforms like Vercel and Netlify provision these automatically per PR. They are excellent for UI review but cannot verify backend logic, database migrations, queue behavior, or cross-service interactions.
A full-stack preview environment is a per-PR isolated runtime containing every service the application depends on: frontend, backend API, database, queues, caches, and workers. Each PR gets its own isolated copy of the full stack, provisioned from scratch with its own database instance, migrations applied, and environment routing. It is torn down automatically when the PR closes.
Frontend-only previews cannot catch seven classes of bugs: (1) backend logic on the diff, (2) real database shape bugs from migrations, (3) side effects in service replication, (4) queue state bugs without per-PR orchestration, (5) cache invalidation bugs without secrets and config propagation, (6) third-party integration drift, and (7) cross-service race conditions without isolated runtime infrastructure. All seven require a running, isolated full-stack environment to surface. Autonoma's Layer 1 provides that environment per PR: isolated services, database instance with migrations applied, queues, cache, and secrets scoped to each preview, so all seven classes are catchable before merge.
No. Vercel preview deployments are frontend-only previews by design. They deploy the frontend per PR and serve it against your existing backend and database. The backend is not isolated, the database is not branched, and services are not replicated. This is a deliberate product scope decision, not a limitation. Full-stack preview environments are a different category that provisions isolated infrastructure for every service in the stack.
A frontend-only preview is sufficient when the pull request changes only frontend presentation: layout, styling, copy, or client-side logic that does not interact with the backend. If the PR touches backend logic, API contracts, database schemas, environment variables, queues, or third-party integrations, a frontend-only preview cannot validate those changes. For teams shipping multiple PRs a day with full-stack changes, frontend-only coverage leaves a systematic blind spot.
DIY full-stack preview setups run ephemeral backend servers inside CI jobs, expose them via tunnels, and wire secrets manually per repo. They close some of the frontend-only gap but absorb significant engineering time to build and ongoing maintenance as the stack evolves. Managed preview environment platforms handle image builds, service replication, environment routing, secrets propagation, database isolation, and teardown automatically, letting teams get full-stack coverage without owning the orchestration surface. Autonoma is one such platform: Layer 1 handles all the infra provisioning per PR, and Layer 2 adds four agents built around a Planner and Diffs Agent pairing, backed by an Executor and Reviewer, that read the codebase, generate and maintain E2E tests from code diffs, execute them against the running preview, and classify each result as a real bug, an agent error, or a test-plan mismatch.



