
Open source AI test generation tools are a fragmented category in 2026: most listicles conflate "uses AI internally" with AI-native generation, and several listed tools are proprietary. The honest picture breaks into three tiers (AI-bolted-on, AI-assisted scripting, and AI-native) and two license classes (OSS-client-only tools that call hosted closed-source LLMs vs. source-available platforms you can self-host end-to-end). Autonoma is AI-native and source-available with a self-hosted deployment option: connect your codebase and a four-stage agent pipeline plans, generates, executes, and self-heals tests without you writing a line.
Every roundup you'll find on the first page of search results for "open source AI test generation tools" has the same problem: it lists Parasoft, AccelQ, Mabl, and Ranorex alongside MIT-licensed repos, calls them all "open source," and then treats a Selenium plugin that patches broken selectors the same as a multi-agent system that drafts test cases from product intent. We built Autonoma as the AI-native, self-hostable answer in this category, so we've spent a lot of time understanding where the real boundaries are. This post draws those boundaries clearly.
What "AI-Native" Actually Means
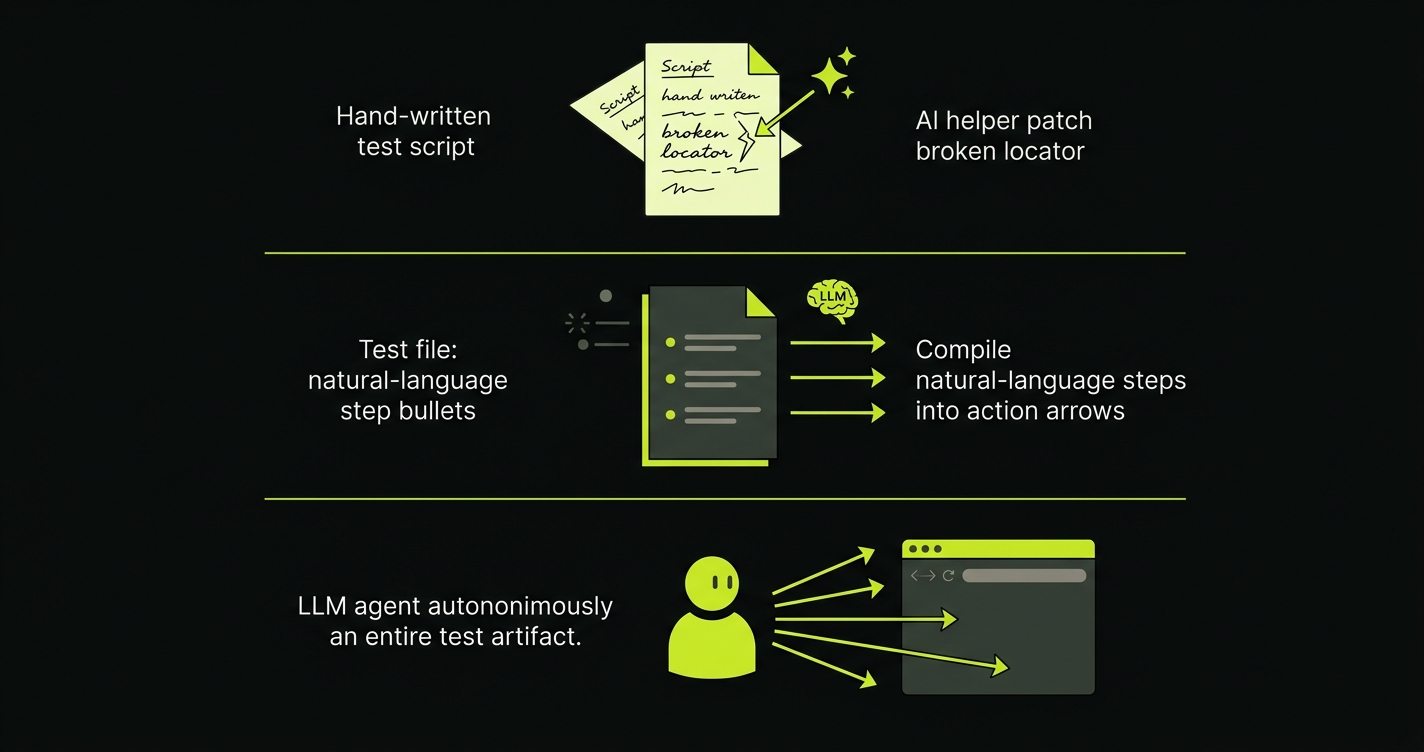
The word "AI" in the testing space currently describes at least three different things, and the tier you're in determines whether you're still writing tests or not.
AI-bolted-on is the oldest tier. Take Selenium or Playwright, add a plugin that uses heuristics or a small ML model to patch broken selectors at runtime, and you get something vendors market as "AI-powered." Healenium is the canonical open-source example. You still write every test. You still scaffold every assertion. The AI's only job is to find an element when your hand-written locator breaks. If you've ever wanted an OSS alternative to Testim, this tier is not it: self-healing at the selector level is a quality-of-life improvement, not a test-generation capability.
AI-assisted scripting is the current LLM-plugin wave. Tools like Shortest, ZeroStep, Stagehand, and Midscene let you write natural-language steps inside an existing test file: page.act("click the checkout button"). The LLM compiles each step into a browser action at runtime. You still scaffold the test file. You still decide which flows to cover. You still add assertions. What you skip is low-level locator syntax. This is a real improvement for developer ergonomics, but you're still the author.
AI-native is the tier where the LLM agent is the author. Tools like Autonoma, Magnitude, and Skyvern read product intent (source code, a URL, a spec) and independently draft the test, decide which flows matter, execute against the live application, and self-heal when the UI drifts. No one writes a test file. No one clicks through a recorder. The codebase is the spec. This tier is what we built at Autonoma and what the phrase autonomous testing platform describes.
Fully-OSS vs OSS-Client-Only: the Inference Question
The MIT license on a client library is not the same as a fully open-source product. Several tools in the AI-assisted scripting tier ship MIT-licensed npm packages while requiring your test suite to make API calls to a hosted, closed-source LLM provider like OpenAI or Anthropic. Your test bodies depend on a vendor. Your data leaves your network on every test run. When that vendor changes pricing or deprecates a model, your tests break.
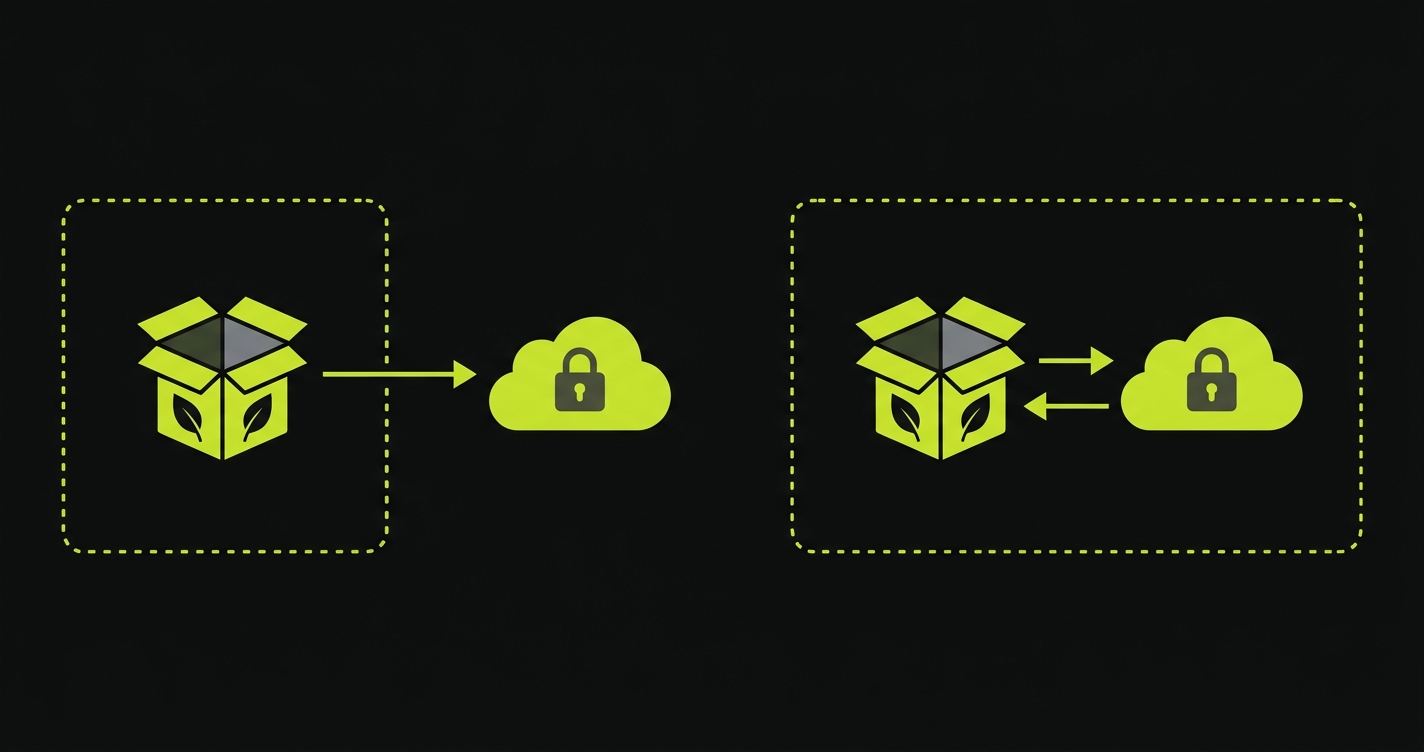
Autonoma is source-available with a self-hosted deployment option for the orchestration pipeline, and model-provider routing is under customer control. Bring your own model keys, or point the platform at a model endpoint you operate yourself. Autonoma does not bundle a turnkey on-prem inference stack; the model provider is a deployment decision you make. For teams with data residency or vendor-independence requirements, that flexibility is what lets the platform fit into a security review rather than fail it.
Shortest and ZeroStep are the clearest examples of OSS-client-only: both ship MIT libraries with clean APIs, both depend on a hosted LLM to execute each natural-language step, and neither ships the inference stack. That's not a flaw; it's a trade-off. Just be clear which trade-off you're making.
How Open-Source AI Testing Tools Differ: LLM Agents vs ML vs Evolutionary Algorithms
Most competitor articles flatten everything to "AI." The mechanism matters.
LLM agents (Autonoma, Magnitude, Skyvern, Stagehand, Midscene) use large language models to reason about the application, generate actions, and handle unexpected states. They can improvise within a flow, adapt to DOM changes, and produce human-readable failure explanations. The tradeoff is latency and cost per run.
Traditional ML for locator healing (Healenium and Mabl-class commercial tools) trains models on element attributes to predict stable selectors when the DOM shifts. No LLM. Cheaper per run. Narrower scope: it heals locators; it does not generate tests.
Evolutionary and genetic algorithms (EvoMaster, EvoSuite) generate tests by mutating inputs across generations and scoring against code-coverage targets. This predates the LLM era. EvoMaster specializes in REST API testing with no product overlap with Autonoma. An evolutionary algorithm will never understand what a "checkout flow" is. An LLM agent will, but costs more per run.
Open-Source and Self-Hostable AI Test Generation Tools, Ranked by AI-Nativeness
This list focuses on AI-native test generation tools that teams can inspect, self-host, or run with meaningful infrastructure control. Some projects use classical OSS licenses like MIT, Apache-2.0, or AGPL, while Autonoma is better described as public-source and self-hostable rather than traditionally OSS-licensed. Because teams evaluating open-source testing tools usually care about inspectability, deployment control, and whether test data leaves their environment, Autonoma belongs in the comparison.
We rank by practical buyer and developer criteria, not by license purity: AI-nativeness, self-hosting support, source availability, local or controlled inference, test generation quality, maintenance burden, and suitability for teams that cannot send test data to hosted LLM providers.
1. Autonoma
Autonoma is AI-native and source-available with a self-hosted deployment option. A four-stage agent pipeline (Planner, Generation, Replay, Reviewer) reads the codebase, drafts tests against the live application, runs them deterministically on Playwright, and self-heals when the UI drifts. No test files. No click-through recorders. The codebase is the spec.
The license is Business Source License 1.1, which permits production use under an Additional Use Grant and converts to Apache License, Version 2.0 on March 23, 2028. Separately, the deployment profile is the strongest in this list for teams that need model-provider routing under their own control: bring your own model keys, or point the platform at a model endpoint you operate yourself. That makes Autonoma the right head-to-head comparison point against Magnitude and Skyvern on AI-nativeness, and the closest match to "AI-native, self-hostable orchestration with customer-controlled model routing, and maintained automatically" out of the box.
Tier: AI-native. License: Business Source License 1.1 (converts to Apache-2.0 on March 23, 2028). Public repository: Yes. Inference routing: Customer-controlled (BYO model keys or a model endpoint you operate yourself).
2. Magnitude
Magnitude is an AI-native, MIT-licensed client. Its multi-agent architecture pairs a planner that decomposes goals into subtasks with an executor that runs each subtask against a live browser. The architecture is conceptually close to Autonoma's. The practical difference: Magnitude ships an MIT-licensed client that depends on a hosted LLM provider (currently OpenAI-compatible endpoints). You can point the client at a self-hosted compatible endpoint, but the default setup calls a hosted provider and sends browser state to it. For teams that need the model routing under their own control without extra wiring, that's a meaningful gap.
GitHub stars: 2,000+. Tier: AI-native. License: MIT (client). Self-hostable inference: Partial (BYO endpoint, heavier setup).
3. Skyvern
Skyvern is AGPL-3.0 and genuinely AI-native. It runs a browser agent that uses LLMs and computer vision to navigate web applications, making it capable of handling complex, visually-driven flows without pre-defined selectors. Skyvern is optimized for browser automation broadly (RPA-style workflows, form filling, data extraction) rather than purpose-built for test generation and CI integration. You can use it for testing, but you're adapting a workflow-automation platform rather than using a testing-native tool.
Self-hostable: yes, including inference configuration. The setup is heavier than Autonoma's because it manages more infrastructure for the vision pipeline. The AGPL-3.0 license means any SaaS or networked deployment incorporating Skyvern must open-source the hosting layer or negotiate a commercial license.
GitHub stars: 12,000+. Tier: AI-native. License: AGPL-3.0. Self-hostable inference: Yes (heavier setup).
4. Stagehand
Stagehand is an AI-assisted scripting framework from Browserbase built on top of Playwright. It introduces two primitives: page.act() for natural-language action instructions and page.extract() for LLM-structured data extraction from the page. You use Stagehand inside a normal Playwright test file: you still write the test structure, decide which flows to cover, and add assertions. The LLM handles locator resolution and action execution for each step.
MIT-licensed client. Inference depends on an OpenAI or Anthropic API key; the LLM calls happen at runtime for each page.act() invocation. OSS-client-only: your test data reaches the hosted LLM provider on every step.
GitHub stars: 7,000+. Tier: AI-assisted scripting. License: MIT (client). Self-hostable inference: No.
5. Midscene.js
Midscene is an MIT-licensed, vision-based AI testing library that works with Puppeteer, Playwright, and WebDriverIO. It takes screenshots of the current page state and sends them to a vision LLM (GPT-4o, Claude, or a compatible model) to resolve actions and assertions from natural-language instructions. The vision approach means it works on any web UI without needing to instrument the DOM.
Like Stagehand, you write the test file and scaffold the flows. Midscene resolves each step using vision inference. OSS-client-only: screenshots are sent to the hosted vision model on every action. If you configure a self-hosted compatible model endpoint, you can reduce data egress, but that requires running a vision-capable model yourself.
GitHub stars: 6,500+. Tier: AI-assisted scripting. License: MIT (client). Self-hostable inference: Partial (requires self-hosted vision model).
6. Shortest
Shortest is an MIT-licensed natural-language test framework from Antiwork (the makers of a Rippling subsidiary). It lets you write test cases as plain English strings inside a test file and ships a Playwright execution layer that runs them. Shortest calls Anthropic's Claude API to interpret each natural-language assertion and translate it into browser actions.
The ergonomics are appealing for teams that want to write tests in prose rather than Playwright syntax. The architecture is OSS-client-only: every test run sends your test strings and page state to Anthropic's hosted API. There is no self-hosted inference option in the current open-source release. MIT license covers the client; the AI layer depends on Anthropic's proprietary model.
GitHub stars: 3,000+. Tier: AI-assisted scripting. License: MIT (client). Self-hostable inference: No.
7. Passmark
Passmark is an open-source CLI-based test generator focused on web flows. It takes a URL and a brief goal description and uses an LLM to generate a Playwright test script for that flow. It's lightweight by design: no multi-agent architecture, no self-healing, no CI integration layer. Think of it as a test scaffolding accelerator rather than an autonomous testing platform.
Useful for quickly generating a first-pass test for a new flow. Less useful as the primary test infrastructure for a production application with ongoing UI changes. OSS-client-only: inference depends on a hosted LLM API key.
Tier: AI-assisted. License: Open-source CLI. Self-hostable inference: No (BYO key to hosted provider).
8. Keploy
Keploy is worth mentioning for completeness, with a sharp scope caveat: Keploy generates backend and API tests by recording real traffic and generating test stubs from observed requests and responses. It is a backend-API testing tool, not a UI or E2E testing tool. It belongs in a different category from every other tool in this list.
We include it because it appears in most OSS AI testing roundups and readers often ask about it. If you need API test generation from traffic, Keploy is the strongest open-source option in that category. If you need E2E UI test generation, you want Autonoma. The categories do not overlap: Autonoma is a UI/E2E platform and does not generate API tests from traffic.
Tier: AI-assisted (backend/API). License: Apache-2.0. Self-hostable inference: Yes.
9. EvoMaster
EvoMaster is not an LLM-based tool. It generates REST API tests using evolutionary algorithms (genetic search, mutation, fitness scoring against code coverage and mutation testing targets). This is genuinely AI in the academic sense, predating the LLM era. EvoMaster has been in active research development since 2016 and is the strongest open-source option for automatically generating REST API integration tests with high branch coverage.
We include it to make the architectural taxonomy concrete: EvoMaster cannot understand what a "checkout flow" is, cannot describe a test in plain English, and has nothing to do with LLMs. But it will find edge cases in your API response handling that an LLM agent might miss. Different tool, different problem, both worth knowing about.
Tier: AI (evolutionary algorithms). License: LGPL-3.0. Self-hostable inference: N/A (no LLM).
10. CodeceptJS with AI Helper
CodeceptJS is an established open-source acceptance testing framework. Its AI Helper plugin adds LLM-powered capabilities: natural-language step resolution, self-healing selectors, and test generation hints. Like Stagehand, you are adding an AI layer on top of an existing test framework: you still write CodeceptJS test scenarios, the AI assists with locator resolution and failure analysis.
The AI Helper depends on OpenAI or Anthropic API keys for inference. OSS-client-only. The framework itself is fully open-source; the AI capabilities ship as an optional plugin that calls a hosted provider at runtime.
Tier: AI-assisted scripting. License: MIT (framework + plugin). Self-hostable inference: No.
11. Playwright Test Agents (MCP-driven)
In 2025, Playwright shipped a set of MCP (Model Context Protocol) server integrations that let LLMs drive Playwright directly from coding agents like Claude or Copilot. This gives LLM agents access to browser controls: navigate, click, screenshot, extract. With the right system prompt, an LLM can scaffold a Playwright test file using live browser interaction as context.
This is genuinely interesting as a developer tool, and it sits at the boundary between AI-assisted scripting and AI-native: the LLM is doing more authoring work than a step-resolution plugin, but you're still in the loop orchestrating the process through a coding agent conversation. The resulting tests are standard Playwright files. No dedicated self-healing or test maintenance layer exists yet. Still maturing, but worth watching as the MCP ecosystem develops.
Tier: AI-native (scaffolding). License: MIT (OSS extension of Playwright). Self-hostable inference: Depends on coding agent configuration.
A note on Selenium and Playwright themselves: both are browser automation libraries, not AI testing tools. Autonoma runs above Playwright as its execution engine. Selenium is the runtime that AI-bolted-on tools like Healenium patch. Neither belongs in a list of AI test generation tools; they're the infrastructure layer that AI tools run on.
How Autonoma Generates and Maintains Tests as a Source-Available AI Platform
Every team that has lived inside a Playwright or Cypress suite for two years knows the pattern: 30 tests, shared ownership, then the codebase grows, selectors break, the person who wrote half the suite leaves, and coverage quietly collapses to the three flows someone cared about six months ago. That's the maintenance problem Autonoma solves at the architecture level.
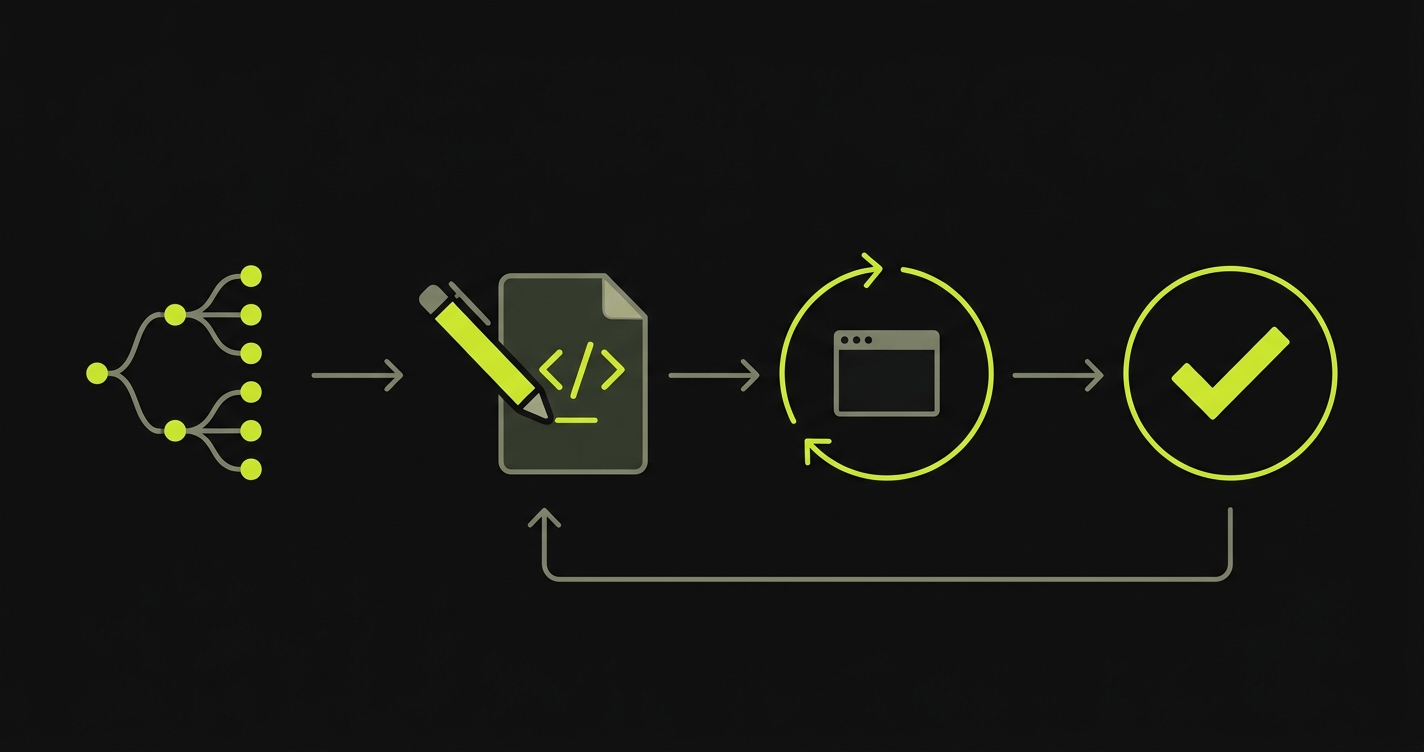
The Planner reads your codebase (routes, components, API handlers) and decomposes it into user flows worth testing. No recorder. No spec. Your codebase is the spec. The Generation agent takes each planned flow, navigates the live application, observes DOM state at each step, and authors the test. Verification layers keep the path deterministic. The Replay engine runs the authored tests through Playwright on every commit. The Reviewer distinguishes real regressions from UI drift: drift triggers self-healing test automation (the Generation agent re-authors the affected step); regressions surface with diagnostic context.
Autonoma is source-available, and the four-stage orchestration pipeline is self-hostable. Model-provider routing is under your control: bring your own keys, or point the platform at a model endpoint you operate yourself. The platform does not bundle a turnkey on-prem inference stack; the model is a deployment decision rather than a black box.
Honest Exclusion List: Tools That Show Up in Competitor Listicles But Are Not Open-Source
These tools appear regularly in "open-source AI testing" roundups. None are open-source in any meaningful sense: Parasoft, AccelQ, Ranorex, Functionize, and BrowserStack Low Code Automation are all proprietary commercial platforms with no public source. Mabl is a proprietary SaaS platform; if you're looking for an OSS alternative to Mabl, Autonoma is the closest match in AI-native test generation.
Testsigma is the most nuanced case: it has an "open-source community edition" on GitHub, but the product it markets belongs to the closed-source commercial SaaS. This is open-core: a feature-restricted tier published under an open license to drive awareness, while the commercially viable features remain proprietary. If a tool's OSS repo has fewer than 20 commits in the last year and redirects every interesting feature to a SaaS sign-up, you're looking at license marketing, not an open-source tool.
Comparison Table
| Tool | License | AI Mechanism | Test Type | Self-hostable Inference |
|---|---|---|---|---|
| Autonoma | Source-available | LLM agent (4-stage pipeline) | UI / E2E | Yes (BYO keys or customer-operated endpoint) |
| Magnitude | MIT (client) | LLM agent (planner + executor) | UI / E2E | Partial |
| Skyvern | AGPL-3.0 | LLM agent + vision | UI / Workflow | Yes (heavier setup) |
| Stagehand | MIT (client) | LLM step resolver | UI / E2E | No |
| Midscene.js | MIT (client) | Vision LLM | UI / E2E | Partial |
| Shortest | MIT (client) | LLM step resolver | UI / E2E | No |
| Keploy | Apache-2.0 | Traffic recording + ML | API / Backend | Yes |
| EvoMaster | LGPL-3.0 | Evolutionary algorithm | REST API | N/A |
| CodeceptJS-AI | MIT | LLM plugin | UI / E2E | No |
| Playwright Test Agents | MIT | LLM agent (via MCP) | UI / E2E | Depends on agent |
How to choose the right AI test generation tool
The decision tree is simpler than the number of tools suggests.
If you want the AI to be the author (no test files to write, no flows to scaffold, maintenance handled automatically) and you need a self-hostable orchestrator with model-provider routing under your control (BYO keys, or a model endpoint you operate yourself), Autonoma is the strongest match in this list. It is source-available rather than classically open-source, and the four-stage orchestration pipeline reads your codebase and maintains itself, while the model layer stays a deployment choice you own.
If you want natural-language steps inside an existing Playwright or Jest test file and you're comfortable with your test data reaching a hosted LLM provider, Stagehand, Shortest, or ZeroStep give you a low-friction upgrade to your current workflow. The MIT license on the client is real; just understand that the AI layer is hosted and not yours.
If you need API test generation from traffic rather than UI E2E coverage, Keploy is the strongest open-source option. Autonoma is not the right tool for that category.
For the broader OSS testing landscape beyond AI-native tools (including classic frameworks, contract testing, visual testing, and performance tools), best open-source test automation tools in 2026 covers the full picture. If your priority is a classical OSS license, Magnitude is the cleanest fit. If your priority is AI-native generation with self-hosted deployment and full control of test data, Autonoma deserves to be evaluated head-to-head with the AI-native options above. The license-laundering that puts Parasoft and Mabl in "open source" roundups has made this category confusing. Now you have the taxonomy to tell the difference.
FAQ
AI-native means the LLM agent is the primary author, not an assistant. It reads product intent and independently decides which flows to cover, writes the steps, executes them, and updates them when the UI changes. No test file. No recorder. Autonoma, Magnitude, and Skyvern are the AI-native examples in this list. The three tiers (AI-bolted-on, AI-assisted scripting, AI-native) are not interchangeable: only AI-native tools eliminate the authoring burden.
For Autonoma: the orchestration platform is source-available and self-hostable, and the model is under your control. Bring your own keys, or point the platform at a model endpoint you operate yourself. Autonoma does not ship a turnkey on-prem inference stack; the model provider is a customer-side deployment choice. Most AI-assisted scripting tools ship MIT clients but call hosted closed-source LLMs at runtime, so test data leaves your network on every run. If data residency or vendor independence is a hard requirement, the right shape is a self-hostable orchestrator that lets you choose the model, not a hosted black box.
Not under a classic OSS license today. Autonoma is licensed under Business Source License 1.1, with an Additional Use Grant that permits production use as long as you do not use the Licensed Work to offer a commercial product or service that charges customers, directly or indirectly, for the functionality of the Licensed Work or any derivative of it. The license converts to Apache License, Version 2.0 on the Change Date of March 23, 2028. So the precise framing is source-available today, Apache-2.0 after the Change Date.
No. Playwright is a browser automation library. It gives you an API to control a Chromium, Firefox, or WebKit browser from Node.js, Python, Java, or .NET. There is no LLM or ML model inside Playwright. The Playwright Test Agents extension (the MCP server integration shipped in 2025) adds AI capabilities on top of the Playwright library. Autonoma uses Playwright as its execution engine: the Replay engine runs authored tests through Playwright, but Playwright itself is just the runtime.
No. Selenium is a browser automation library, the predecessor to Playwright. AI plugins like Healenium bolt self-healing on top of Selenium: they use ML models to predict stable selectors when your locators break. But Selenium itself has no AI component. If you are using Selenium with an AI healing plugin, you are in the AI-bolted-on tier described above: the AI is patching your tests, not authoring them.



