
Preview environment testing without writing test code means your per-PR environment gets full E2E coverage the moment it provisions, with no Playwright spec files to author, no CI pipeline to wire, and no on-call rotation when the suite drifts. An AI agent reads the codebase, runs against the live preview URL, and posts a Replay trace to the PR comment. No test code required at any stage.
Most teams put E2E testing preview environments in place and then realize the test signal still requires Playwright code, a CI pipeline, and someone available when the suite breaks. We built Autonoma's four-stage pipeline so the preview environment is tested by an AI agent. No test code to write, no pipeline to wire.
That framing matters because most teams encounter this problem in the wrong order. The preview infrastructure ships first. The testing question comes second, and by then the implicit answer is already "Playwright plus GitHub Actions," because that is what everyone on the team knows. The Playwright suite is written, wired into the E2E testing preview environments pipeline, and promptly begins demanding maintenance every time a component changes. Within a sprint or two, someone is spending half a day fixing tests that the feature team considers low priority.
The Autonoma position on this is different. You should not have to write test code to get test signal on a preview environment. The preview environment already contains everything the test needs: the running application, the database, the routing. The agent reads the codebase to understand what needs testing, runs against the live URL, and reports back. No intermediary artifact, no spec files, no selector database to maintain.
The Test-Code Problem on Preview Environments
The test-code maintenance burden is not unique to preview environments. It exists everywhere Playwright runs. But preview environments amplify it in two ways that don't get enough attention.
The first is selector drift from agent-induced UI churn. Teams using agentic coding tools to ship features are now merging PRs at a cadence that would have been impossible two years ago. An AI coding agent edits a component, renames a data attribute, restructures a form. The Playwright suite, which was written against last week's DOM, now has failing selectors. Not because the feature broke, but because the UI changed underneath it. At one or two PRs per day, this is a manageable nuisance. At ten PRs per day across five engineers plus three AI coding agents, it becomes a full-time maintenance job.
The second amplifier is the per-PR isolation model. Shared staging environments let you build a Playwright suite once and let it run forever against a stable URL. Per-PR preview environments are not stable: every PR gets a fresh environment, and any UI variation introduced by that PR can knock out the selectors your test suite was written against. The test suite that runs fine on the main branch preview can fail immediately on a feature branch preview because the feature branch changes a component the selectors depended on.
Flakiness compounds both of these. Cold starts on ephemeral environments introduce timing variance. A test that relies on a fixed wait time built against warm staging infrastructure will occasionally time out against a cold preview container. You add retries. The retries slow CI. The slow CI makes people skip the test step on small PRs. The small PRs start shipping bugs.
The common mitigation is to write more resilient selectors, add more retries, invest in better seed scripts. These all work. They are all test-code maintenance work. They do not solve the underlying structural problem, which is that the test suite is a separate artifact from the application code, and every change to the application can invalidate the test suite.
What Code-Less Testing on Preview Environments Actually Does
The "no code" claim gets abused in testing. It is worth being precise about what it means in our context, because the most common vendor in this space, record-and-replay tools, makes the same claim and does not actually deliver it.
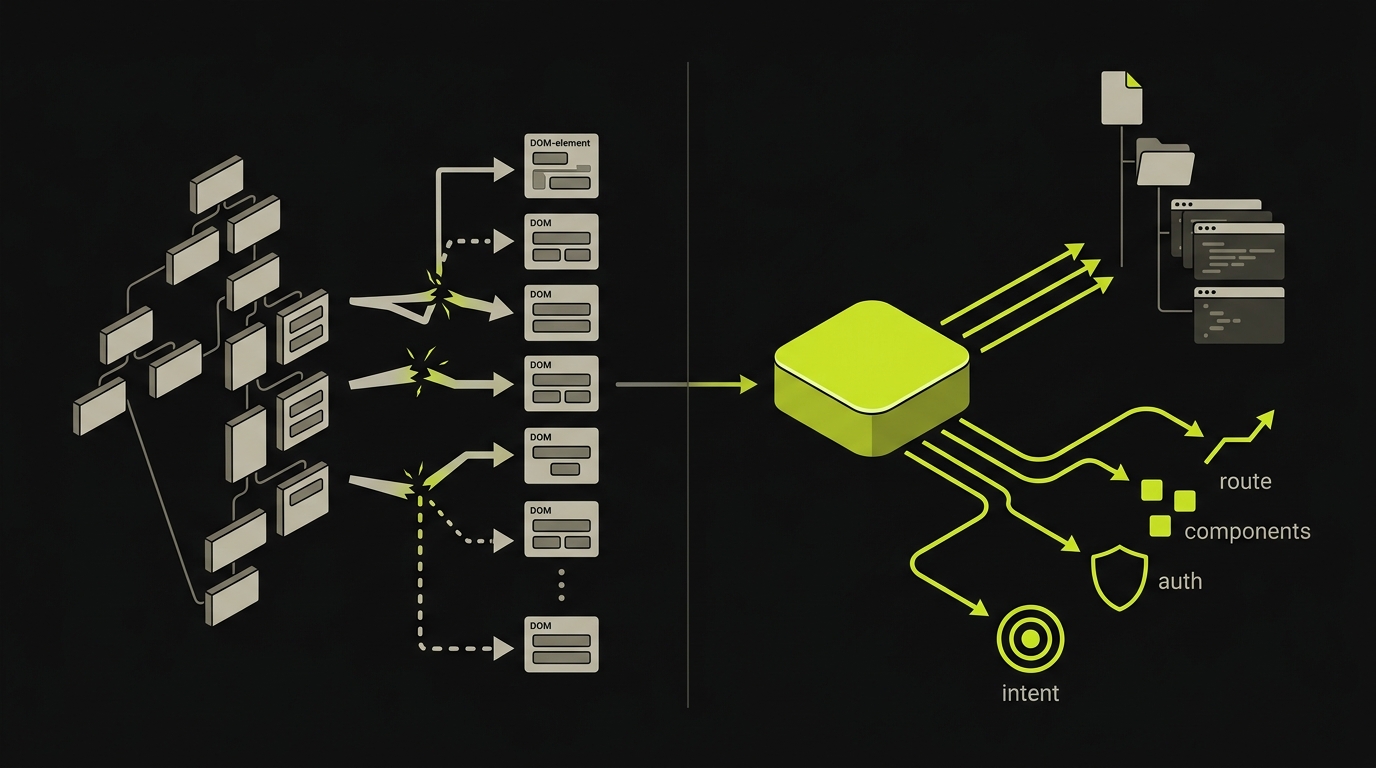
Record-and-replay tools store DOM selectors. When you "record" a test by clicking through the app, the tool captures which elements you interacted with. Those elements are identified by their selectors: class names, data attributes, IDs, XPath expressions. The test "code" is a selector database. When your UI changes, the selectors break. The self-healing logic these tools advertise is fundamentally trying to re-match the old selector against a changed DOM. It works sometimes. It fails when the structural change is significant enough that no heuristic re-match finds the right element.
What we built is different. The Planner agent reads your source code, not your DOM. It understands your routes, your components, your user flows, your auth model, not from a recording of what you clicked, but from what the code actually defines. When the UI changes, the Planner re-reads the updated source and re-derives the test plan. There is no selector database that can drift, because selectors are never the unit of storage. Intent, derived from code, is what gets stored and replayed.
That distinction matters most in the context of agent-induced churn. A coding agent that refactors a component changes the source code and therefore updates the Planner's understanding of the app on the next run. A record-and-replay tool stored selectors based on the old DOM and has no automatic connection to the updated source.
Crawl-based testing tools have a different failure mode: they test what they can reach from the surface, typically the public-facing marketing site. They miss authenticated flows because they cannot log in. They miss admin dashboards, billing portals, and anything that requires a session. Autonoma's Planner reads source, so it sees the flows behind auth gates and three clicks deep into the app, not just what a headless browser finds by crawling from the homepage.
What the Artifact Looks Like
When Autonoma runs against a preview environment, the PR comment receives an artifact bundle. This is not a test report. It is a Replay trace.
The Replay trace is a deterministic recording of every step the agent executed: the actions taken, the outcomes observed, the verification checks at each step. It is reproducible. You can re-run the Replay against the same preview environment and get the same result, because the Reviewer agent uses the trace to distinguish actual failures from environmental noise.
Alongside the trace, the PR comment includes a video of the session, screenshots at each significant step, network traffic logs showing every request and response the app made during the test, and application logs from the preview container. When a test fails, you have enough context to diagnose the failure without re-running anything manually.
What the artifact does not include is test code. There is no .spec.ts file generated. There is no test suite to check in, no version-control history for the test, no downstream diff to review when the test changes on the next PR. The Replay trace is the record. The Planner's codebase reading is the persistent specification. The two together give you everything a traditional test suite gives you, without the authoring and maintenance overhead.
This distinction matters for teams evaluating whether this approach fits into their existing review process. The PR comment artifact is readable by a developer who has never used Autonoma. The trace shows what the agent did. The video confirms the behavior. The failure explanation names the specific step and the specific assertion that failed. No Playwright expertise is required to interpret it.
How Autonoma Generates Test Coverage on Every Preview
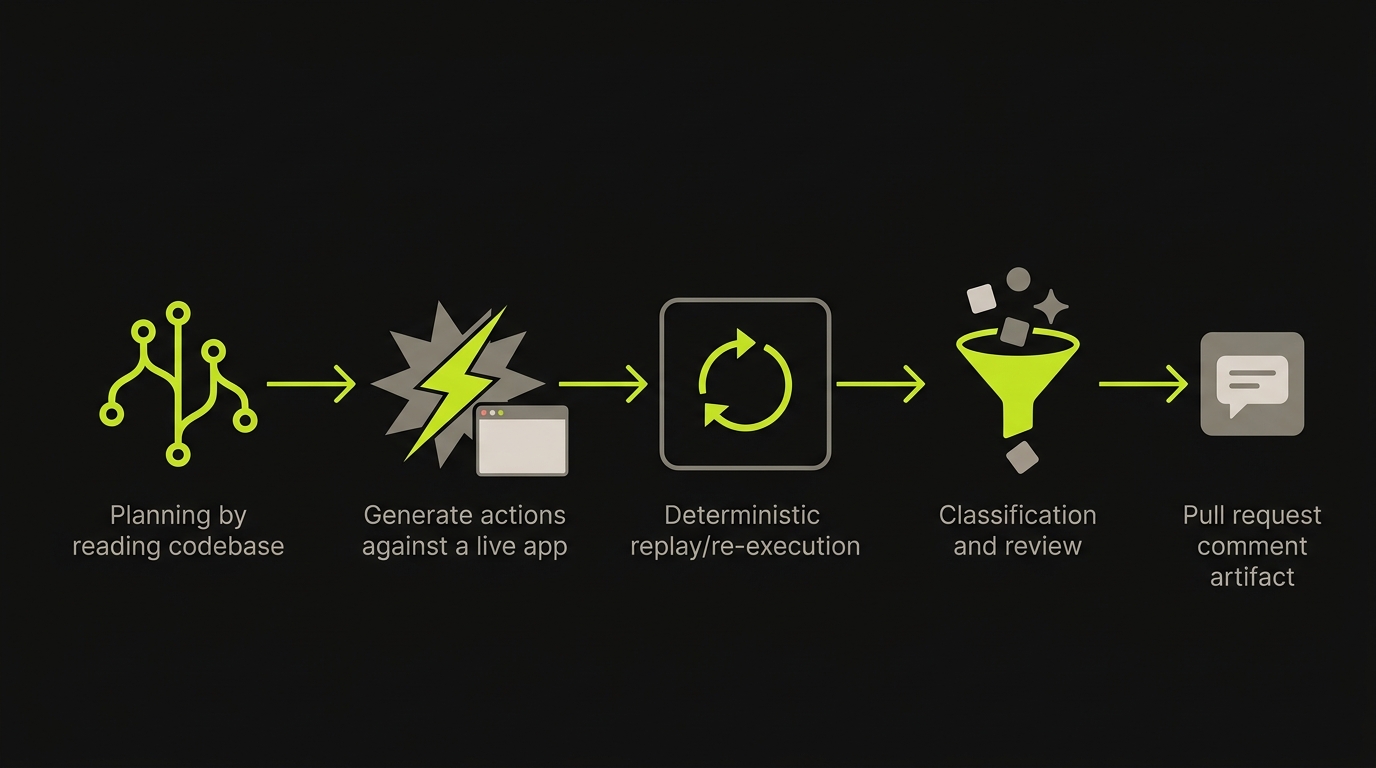
The four stages of the pipeline are Planner, Generation, Replay, and Reviewer. They run in sequence on every preview environment Autonoma provisions.
The Planner reads your codebase before any test runs. Routes, components, user flows, API definitions, and authentication models are all inputs. The Planner produces a test plan that reflects the behavior your code actually defines, not a human's click-through recording. It also generates the database-state setup endpoints each test scenario requires, so the preview environment's database is in the correct state before the test begins. No seed script to maintain. The Planner derives the required state from the code that defines what the feature does.
Generation executes the planned test cases against the running preview URL. The preview environment is already provisioned: stable URL, isolated database, correct service topology. Generation runs the agent against the live application, hitting real endpoints, interacting with real UI components, following the paths the Planner identified. Each step has a verification layer. The agent does not explore randomly. It follows the plan, checks outcomes, and records what happened at each point.
Replay re-executes the recorded session deterministically. This is what separates genuine reliability from probabilistic guessing. The first run (Generation) produces a trace. Replay uses that trace to re-run the same steps against the same environment. If Generation found a bug, Replay confirms it. If Generation encountered environmental noise, Replay's re-run distinguishes the noise from the actual failure. This is the mechanism that controls false positives: two independent runs, one planned, one replayed, both must agree before a failure is surfaced.
The Reviewer interprets the results. It reads the Replay trace, the video, the network traffic, and the application logs. It classifies failures as genuine behavioral regressions (the feature is broken), environmental failures (the preview container had a problem), or test drift (the agent's path is no longer valid because the code changed). For genuine failures, the Reviewer generates a plain-language explanation of what broke and which step failed. For test drift, it flags that the Planner should re-derive the test plan on the next run.
The four stages run without human intervention. Planner reads code. Generation runs. Replay confirms. Reviewer interprets. The PR comment arrives with the full artifact bundle. No one needs to trigger anything, monitor anything, or maintain anything between the initial codebase connection and the PR comment.
For teams who have read how the pipeline connects to the full ephemeral environment lifecycle, the four-stage pipeline is what runs inside that lifecycle on every PR. The preview environment is the substrate. The four-stage pipeline is the verification layer that runs on top of it.
The Comparison
| Dimension | Playwright on preview env | Autonoma codeless |
|---|---|---|
| Code to write | Full .spec.ts suite required | None |
| CI maintenance | Ongoing (selector drift, retries) | Zero (self-healing Planner) |
| Self-heal on UI change | Manual or heuristic re-match | Re-derives from updated source |
| False-positive control | Retry logic, timing tuning | Generation plus Replay agreement |
| PR-comment artifact | Test report (pass/fail counts) | Replay trace, video, screenshots, network, logs |
The table is honest about where Playwright is still the right call. If you have an existing Playwright suite that is well-maintained, runs fast, and your team treats it as first-class code, the maintenance cost is already baked into your sprint structure. Adopting Autonoma on top of that is additive, not a replacement. Some teams run both: Playwright for the unit-level flows they have already invested in, Autonoma for the full-stack coverage they have not been able to staff.
Where This Earns Its Keep
We see teams settle into two patterns where the no-test-code approach earns its keep clearly.
The first is teams where a platform engineer or QA engineer left and no one has the bandwidth to maintain the Playwright suite. The suite has been yellow for two sprints. Flake triage is a standing agenda item in the weekly sync. Nobody wants to own it. Autonoma replaces the suite without requiring anyone to write the replacement.
The second is teams running at AI-accelerated velocity: multiple coding agents, ten-plus PRs per day, UI churn that the existing test suite cannot keep up with. At this cadence, human-written selectors are structurally obsolete before the sprint ends. Codebase-reading agents that re-derive the test plan from updated source are the only approach that stays current without constant manual intervention.
Where the approach earns less is in teams with very specialized UI testing requirements, complex visual regression needs, or precise pixel-level assertions that require a human to define what "correct" looks like. The Planner derives behavioral tests from code. If the correctness criterion for a given flow is aesthetic or subjective (this chart should look like this mockup), that requires human-defined test cases regardless of what tool runs them.
Being honest about scope: Autonoma is built for behavioral E2E coverage on full-stack preview environments. It is not a screenshot comparison tool, not a unit test runner, not an API-schema validator. The flows it covers are the ones your code defines: authenticated user journeys, multi-step interactions, form submissions, state transitions. That is the category where it replaces the test code you would otherwise write and maintain.
If you're trying to skip the Playwright-on-CI tax and have an AI agent test each preview directly, our co-founder Eugenio is happy to walk through how it works. Grab 20 min with a founder
FAQ
You can run both. Autonoma does not require you to delete an existing Playwright suite. If you have Playwright tests you trust and maintain, those keep running. Autonoma adds coverage on the flows you have not gotten to yet, or covers the full-stack paths your Playwright suite only partially reaches because it runs against a shared staging environment rather than a per-PR isolated environment. Many teams use Playwright for their most critical, tightly-scoped flows and Autonoma for the broader behavioral coverage across the full application.
The Reviewer agent classifies the failure before surfacing it. Genuine behavioral regressions get a plain-language explanation naming the specific step, the specific assertion, and the difference between expected and actual behavior. The PR comment includes the Replay trace, video of the session, screenshots at the failure point, network traffic, and application logs. Environmental failures (cold start timing issues, container problems) are separated from genuine behavioral failures so your team is not chasing false positives. The artifact is complete enough that the engineer who opened the PR can diagnose the failure without re-running anything or asking for help.
Yes. The Planner agent reads your codebase: routes, components, user flows, API definitions, auth models. It derives test cases from what the code actually defines, not from a recording or a list of flows someone typed in. If a new route is added in a PR, the Planner sees it in the updated source and includes it in the test plan. If a component is refactored, the Planner re-reads the updated code and re-derives the affected test paths. The codebase is the specification. The Planner's job is to translate that specification into executable test cases on every run.
The Planner reads your auth model from source: it sees your login routes, your session management, your permission model. It generates the database state setup needed for each test scenario, including the user accounts with the correct roles. The agent logs in as part of the test flow, navigates behind the auth gate, and tests the protected flows the same way a real user would. Authenticated flows are not excluded or mocked out. This is one of the areas where Autonoma's codebase-reading approach has a structural advantage over crawl-based testers, which cannot reach anything behind a login screen.



