
An AI QA agent is software that observes an application, plans a test, executes it, evaluates the result, and adapts. The 4 levels of QA-agent autonomy mirror the SAE driving-automation levels: L1 (assist) writes a test you ran; L2 (collaborative) writes and runs tests you reviewed; L3 (autonomous) writes, runs, and self-heals without prompts; L4 (self-improving) closes the loop end to end. Most tools on the market today are L1 or L2. Very few operate at L3. Fewer still reach L4.
The phrase "we don't have any QA" is how a lot of Seed-to-Series A founding teams describe their testing situation. They mean it practically: no dedicated QA hire, no manual regression process, no test suite anyone is actively maintaining. Bugs reach production. They find out from customers. We built Autonoma to operate at L3-L4 because Seed-to-Series A teams without a QA hire cannot afford to babysit an L1 assist. The source code is the spec, three agents handle plan, execution, and maintenance, and the runtime is open-source self-hostable. That framing shapes everything in this article. Read it as a vendor-neutral framework for evaluating any QA agent, including ours.
The 4 levels of QA-agent autonomy
The SAE driving-automation framework is useful here because it separates "the car assists the driver" from "the car drives itself." The same separation exists in QA tooling, and conflating L1 with L3 is how teams buy an assistant that still costs them a full-time maintenance burden.
L1: Assist. The agent generates test code for a flow the human already ran. The human selects the flow, the agent produces a Playwright or Cypress script, and the human runs it. The script breaks when the UI changes and the human fixes it. What it does: code generation from recording. What it does not do: run tests, interpret failures, or repair itself. Example tool: Playwright Codegen, Cypress Studio.
L2: Collaborative. The agent writes and runs tests, but a human reviews the plan before execution and triages failures afterward. The agent surfaces a queue of proposed tests; the engineer approves, runs, and reviews the report. What it does: test authoring and execution. What it does not do: self-heal, prioritize, or close the loop without a human checkpoint. Example tool: Momentic, Testim with AI-assist mode.
L3: Autonomous. The agent generates tests from application code or live behavior, runs them on every PR or on a schedule, detects failures, distinguishes real regressions from flakes, and self-heals broken selectors or flow changes without prompting a human. What it does: generate, execute, evaluate, and self-heal. What it does not do: update coverage strategy based on production error rates or close the shipping loop without a human merging the PR. Example tool: Autonoma (codebase-first, four-stage pipeline), qa.tech (runtime-exploration mode), QA Wolf (managed-service L3 with human backstop).
L4: Self-improving. The agent observes production signals (error rates, user paths, Sentry reports), identifies coverage gaps, generates new tests, validates them, and updates the coverage plan without human direction. What it does: everything L3 does, plus closes the feedback loop from production to coverage plan. What it does not do: replace human judgment on business-critical edge cases or liability-bearing flows. Example tool: Early implementations in Autonoma's roadmap; no vendor credibly ships full L4 yet as of mid-2026.
| Level | Name | What it does | What it does not do |
|---|---|---|---|
| L1 | Assist | Generates test code from a recorded flow | Run, heal, or evaluate tests |
| L2 | Collaborative | Writes and runs tests; human reviews plan and failures | Self-heal or close the loop without review |
| L3 | Autonomous | Generates, runs, evaluates, and self-heals | Update coverage strategy from production signals |
| L4 | Self-improving | Closes loop from production errors to coverage plan | Replace human judgment on liability-bearing flows |
One note on ICP. The L3-L4 autonomy story matters most to Seed-to-Series A teams without a dedicated QA hire. Enterprise teams with staffed QA organizations may legitimately prefer L1-L2 assists that route failures into a human review queue. This article is written for the teams who cannot afford that model.
What a QA agent is not

Before going further, three things the label "QA agent" gets wrongly applied to.
A QA agent is not a static analyzer. ESLint, Semgrep, Snyk, and SonarQube find code-level patterns before runtime. They are valuable. They are not QA agents. A QA agent operates against a running application.
A QA agent is not a performance monitor. Datadog, New Relic, and Grafana observe a deployed system under real load. Useful, not the same thing. A QA agent tests behavior before deployment reaches production users.
A QA agent is not Sentry. Sentry catches errors that already reached production users. A QA agent's job is to catch those errors in a test environment so they never reach Sentry. The two layers are complementary: a QA agent doesn't replace your post-prod safety net like Sentry, it moves the catch point earlier.
A QA agent is not a unit test runner. Jest, Vitest, pytest, and RSpec run isolated function-level assertions. Important. Not E2E behavior. Not user flows. Not integration surfaces.
A QA agent is also not a CAPTCHA solver or a web scraper. These are automation tools that operate on the application's surface without reasoning about correctness.
What a QA agent actually does
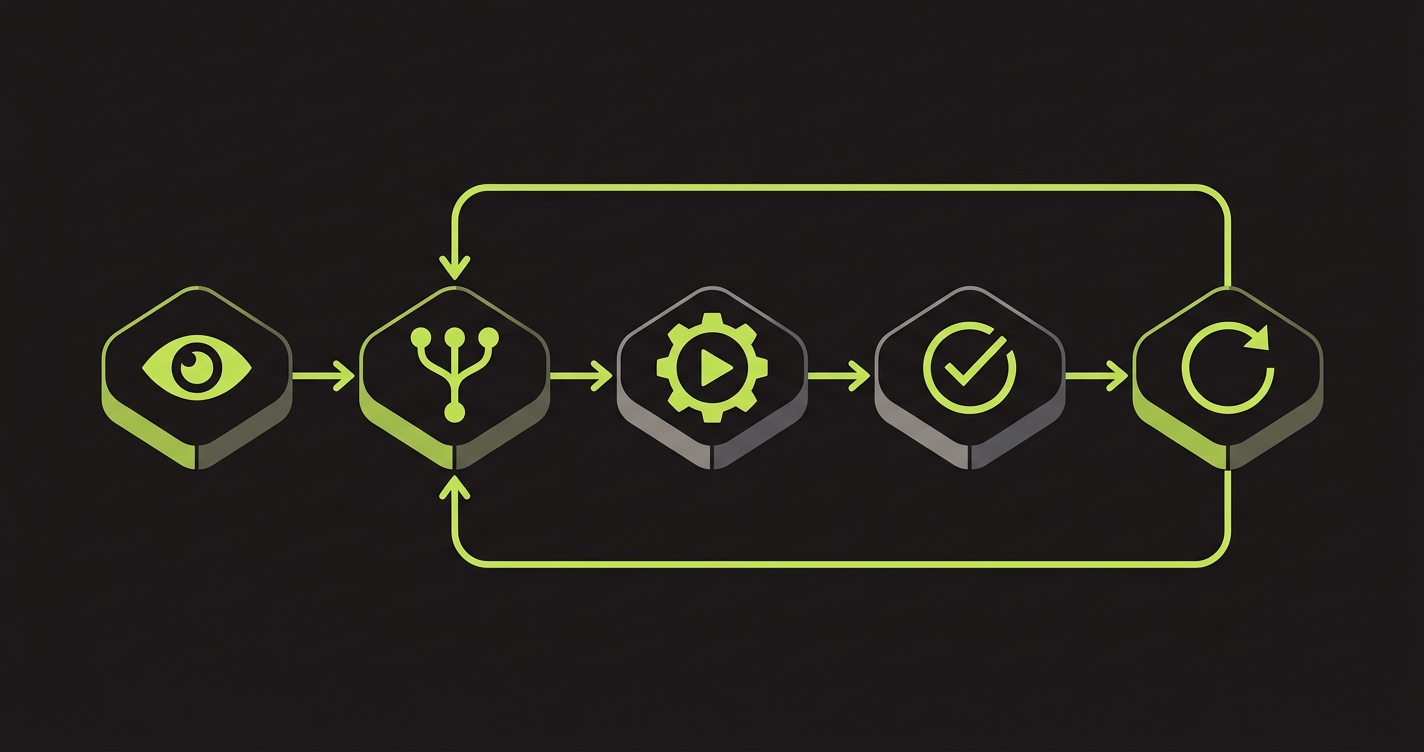
Five concrete capabilities define what it means to be a QA agent rather than a test automation tool.
Generate. The agent reads the application (source code, routes, components, or live behavior) and produces a test plan. This is distinct from recording: the agent does not need a human to click through a flow. It derives test cases from what the code says the application should do.
Execute. The agent runs the generated tests against a live instance of the application, a preview environment, or a staging server. It drives a real browser, clicks real buttons, fills real forms, and observes real responses. Not mocks. Not synthetic assertions against a schema. Real behavior under test.
Evaluate. The agent interprets results. It classifies failures as genuine regressions, flakes, or expected differences. It reads screenshots, DOM state, and response bodies to form a verdict. This is the step that separates an agent from a runner: a runner reports pass/fail; an agent reasons about what the failure means.
Self-heal. When the application changes (new selector, renamed route, redesigned flow), the agent detects the mismatch and repairs the test without human intervention. Self-healing is what makes the testing layer sustainable over time. Without it, the maintenance cost of a growing test suite eventually exceeds its value.
Adapt. The agent updates its coverage model as the application evolves. New routes get test coverage. Deleted flows are pruned. The coverage surface stays current with the codebase without a human scheduling a "test audit sprint." For an introduction to how agentic patterns change the testing contract overall, the agentic testing guide covers the foundational concepts.
Catch bugs before they reach Sentry
The core value proposition of a QA agent, framed as simply as possible: catch bugs before they reach Sentry.
Teams that ship without a QA function typically find bugs one of two ways: Sentry fires, or a customer files a ticket. Both have the same shape. A regression shipped, it hit production, it affected real users, and now the team is in reactive mode. The cost isn't just the fix. It's the lost trust, the support time, and the compounding effect on retention for an early-stage product.
A QA agent intercepts that loop. Every PR that touches the application runs through a test cycle against a preview environment. Broken auth flows, dead clicks, form submissions that return 500s, permission checks that stopped working, corner cases that only surface when two features interact, all of these are caught before the PR merges. The agent evaluates the failure, decides whether it is a real regression, and surfaces it in the PR as a blocking comment.
The unit economics are a no brainer for early-stage teams. One avoided incident (support time, engineering context-switch, customer churn risk) covers months of agent runtime cost. The question isn't whether an L3 QA agent is worth it. It's whether the team can afford to keep discovering bugs in production instead.
How Autonoma operates as a QA agent
Here is the specific architecture, since the autonomy spectrum only means something when grounded in how a real system implements it.
The pain point this article documents: small engineering teams ship fast, skip QA, and discover regressions from customers instead of tests. The verification gap is at every PR merge. Autonoma sits at that gap.
Autonoma runs a four-stage pipeline on every PR. The Planner agent reads the application source code, maps routes, components, and user flows, and produces a structured test plan. This is the L2 collaboration layer: the Planner reasons about what the application is supposed to do before any test runs. It also handles database state setup, generating the endpoints needed to put the DB in the right state for each scenario so tests are not dependent on existing data.
The Automator agent executes that plan against a live preview environment. This is where L3 autonomy kicks in. The agent drives a real browser, authenticates, navigates flows, and records what it observes. Verification layers at every step ensure the agent takes consistent, deterministic paths rather than drifting across runs.
The Maintainer agent is the self-healing layer. When a PR changes a selector, renames a route, or restructures a flow, the Maintainer detects the mismatch, updates the test, and re-runs. No human schedules a fix. Coverage stays current automatically. For teams interested in the full architecture of a source-code-grounded testing system, the autonomous testing platform breakdown covers the design choices in more detail.
The Reviewer agent sits between execution and reporting. It reads failure screenshots, DOM state, and response logs to distinguish a real regression from a flaky selector. This is the L3.5 reasoning layer: it does not just report pass/fail, it forms a verdict on whether the failure is blocking.
PreviewKit closes the loop toward L4. Each PR spins up an isolated preview environment with seeded test data. The agent runs against production-shaped infrastructure, not a stripped-down staging server. When a test fails in preview, it is a real signal about production behavior.
The result is a system where "we don't have any QA" is a staffing statement, not a coverage statement. The mechanical layer is covered. Human judgment is still in the loop on what gets merged. That division of responsibility is the practical implementation of source-code-grounded agentic testing at L3.
How to evaluate a QA agent: a 10-criterion buying framework
Before choosing any QA agent, run it through these ten questions. The answers will surface whether you are buying an L1 assist labeled as autonomous or a genuine L3 system.
-
Autonomy level (L1-L4)
- Why: Determines your ongoing maintenance cost
- Ask: Does your agent generate tests without human input? Does it self-heal?
-
Source-code access (Y/N)
- Why: Code-grounded plans miss fewer flows
- Ask: Does the agent read our codebase, or only observe the running app?
-
Self-hosting (Y/N)
- Why: Data residency, compliance, vendor lock-in
- Ask: Can the agent runtime run in our infrastructure?
-
Where the agent runs
- Why: Cloud vs. customer infra changes compliance exposure
- Ask: Where does test execution happen? Who sees our app traffic?
-
How it handles flakes
- Why: False positives erode trust in the test layer
- Ask: How does the agent distinguish a flaky selector from a real regression?
-
What it does with failures
- Why: A pass/fail report without reasoning forces human triage
- Ask: Does the agent reason about why a test failed, or just report it?
-
AI mechanism
- Why: LLM-based agents drift; ML-based agents have narrower scope
- Ask: Does the agent use an LLM, a trained ML model, or evolutionary algorithms?
-
Pricing model
- Why: Per-run pricing punishes high-frequency CI/CD
- Ask: Is pricing per test run, per seat, or flat?
-
Integration model
- Why: PR-stage testing catches bugs before merge; nightly finds them after
- Ask: Does the agent run on every PR, or on a schedule?
-
Open source (runtime Y/N, orchestration Y/N)
- Why: Auditability, self-hosting, and roadmap control
- Ask: What parts of the system are open source? Can we inspect the runtime?
Failure modes: when QA agents miss bugs
No QA agent catches everything. The honest account of failure modes helps teams design a complementary safety net.
Missed bugs (false negatives). The agent generates tests from code it can see. If the application has behavior that is not legible from source (a third-party embed, a race condition at a specific load level, a cross-origin interaction), the agent does not test it. Mitigation: audit the coverage map and identify flows the agent cannot reach by design. Add targeted manual checks for those surfaces.
Hallucinated UI elements (LLM confabulation). LLM-based agents occasionally generate test steps for elements that do not exist in the current build. The test fails, the agent retries, and the run time bloats. Mitigation: screenshot diffs and DOM-state validation at each step, so the agent detects a missing element rather than retrying blindly. Autonoma's verification layers at each step exist specifically to catch this.
False positives (flaky reports). An agent that reports every selector timeout as a regression creates alert fatigue. Teams start ignoring the report, which defeats the purpose. Mitigation: a dedicated reasoning pass that reads the failure context (screenshot, response code, DOM diff) before surfacing it as blocking. The Reviewer agent in Autonoma's pipeline fills this role.
Reasoning drift across runs. LLM-based agents that derive their navigation path at runtime rather than from a fixed plan can take different paths to the same goal across runs. A flow that passed on Monday fails on Wednesday not because the app changed but because the agent took a different route. Mitigation: deterministic replay against a fixed plan. The plan is derived from source once; execution replays that plan, so runs are comparable.
QA agents compared: an honest matrix
This comparison covers the tools most commonly evaluated alongside Autonoma for teams in the no-QA-hire bracket. For a full-spectrum AI E2E testing breakdown including visual-AI and managed-service options, the sibling post covers more ground.
| Tool | Autonomy | Source-code access | Self-hosting | AI mechanism | OSS |
|---|---|---|---|---|---|
| Autonoma | L3-L4 | Yes (codebase-first) | Yes (runtime OSS) | LLM + verification layers | Runtime OSS, orchestration proprietary |
| QA Wolf | L3 (managed) | Partial (engineers review) | No | Human engineers + tooling | No |
| mabl | L2 | No (runtime observation) | No | ML (selector healing) | No |
| Momentic | L2 | No | No | LLM (natural-language specs) | No |
| testRigor | L2 | No | No | NLP + rule-based | No |
| Checkly | L1-L2 | No | No | Script-based + API checks | Runtime partial |
A few honest notes on this matrix. QA Wolf reaches L3 outcomes through human engineers, not autonomous agents. The engineers own the suite on the customer's behalf. For teams that want L3 outcomes and are willing to pay a managed-service price, QA Wolf is a legitimate option. Momentic and testRigor are both L2: they execute tests written in natural language, but a human writes and maintains those specs. Checkly is primarily a monitoring and synthetic-check tool that overlaps with QA agent use cases at the edges.
Are QA agents production-ready in 2026?
L1 and L2 are mature. AI-assisted test authoring (Playwright Codegen, Testim, Katalon) and collaborative review queues (Momentic) are well-understood products with stable customer bases. Teams adopting them know what they are buying.
L3 is production-ready for web application E2E testing. The category is not commodity yet. Implementations vary significantly in how they handle source-code grounding, flake detection, and self-healing. But the core pattern (codebase-first plan, deterministic replay, reasoning-based triage) is proven in production across Seed-to-Series A teams today. A Series A fintech we ship coverage for runs the Autonoma pipeline on every PR across 40 routes, zero test maintenance hours per sprint. That is the realistic outcome of a mature L3 deployment.
L4 is emerging. Closing the loop from production Sentry signals to updated coverage plans is something we are building toward. Early closed-loop implementations exist internally. The category is not yet something any vendor should claim as a shipped product in 2026.
The unit economics at L3 are a no brainer for small teams. An L3 agent costs a fraction of a QA hire, runs on every PR, and catches corner cases that manual spot-checking misses entirely. The question is not whether the agent is production-ready. The question is whether the team's current bug discovery process (finding out from customers via Sentry) is acceptable.
The 4-level autonomy spectrum is the most useful frame for evaluating any QA agent in 2026, and most vendor marketing deliberately blurs L1 and L3. The practical test is simple: does the agent generate tests without a human writing them, and does it repair those tests when the application changes? If the answer to both is yes, you have an L3 system. If either answer is no, you have an L1 or L2 assist with a more expensive price tag than it deserves. For teams building toward full agentic coverage of their application, the agentic testing framework and the autonomous testing platform posts cover the implementation decisions in depth.
Frequently asked questions
A QA agent is software that observes an application, plans a test, executes it, evaluates the result, and adapts. Unlike static automation scripts that replay a fixed sequence, a QA agent reasons about what to test, runs the test against a live application, and updates its behavior when the application changes.
A QA engineer makes judgment calls that require human intuition: understanding business intent, deciding what coverage matters, interpreting ambiguous failures, and communicating risk to stakeholders. An AI QA agent executes the mechanical layer: test generation, execution, evaluation, self-healing, and regression detection. L3-L4 QA agents can own the mechanical layer end to end, which frees QA engineers (where they exist) to focus on judgment work, or enables small teams to ship coverage without hiring a dedicated QA function.
Traditional automation requires a human to write and maintain the test script. When the UI changes, the script breaks and a human fixes it. A QA agent generates tests from source code or application behavior, detects when the application has changed, and repairs the test without human intervention. The core difference is that automation executes instructions; an agent reasons about what instructions to execute.
Evaluate a QA agent on ten criteria: autonomy level (L1-L4), source-code access, self-hosting option, where the agent runs, how it handles flaky tests, what it does with failures, the AI mechanism it uses, pricing model, integration model (PR-stage vs. nightly), and open-source status of the runtime. The single most important criterion for small teams is autonomy level: an L1 assist still requires a human to write tests; an L3 agent generates, runs, and self-heals without prompts.
L1 and L2 QA agents (AI-assisted authoring tools) are mature and widely deployed. L3 agents (autonomous generation, execution, and self-healing) are production-ready for web application E2E testing and are the right call for Seed-to-Series A teams shipping without a QA hire. L4 agents (fully closed-loop, self-improving coverage) are emerging: early implementations exist, but the category is not yet commodity. For teams whose primary concern is catching regressions and corner cases before they reach production, an L3 agent is a clear choice today.



