
AI E2E testing means using AI to plan, generate, replay, and maintain end-to-end browser tests across real user flows. In 2026, the useful map is not "AI testing tools" as one bucket. It is the LLM-agent OSS wave, split into AI-bolted-on, AI-assisted scripting, and AI-native platforms that can help small teams catch bugs before they reach production.
We built Autonoma for engineers without a QA team who cannot afford to maintain a brittle E2E suite. AI E2E testing in 2026 is the answer because the tests maintain themselves. That matters most for Seed to Series A startups, small engineering teams, and engineers shipping without a QA hire, where the honest internal sentence is often "we don't have any QA" and the external pressure is still the same: users find regressions fast.
The mistake in most AI end-to-end testing roundups is that they treat every project with a model call as the same category. A Selenium plugin that recovers a selector, a Playwright helper that turns a sentence into one browser action, and an AI-native platform that owns four coordinated agents are not the same operating model. If you do not separate them, you end up buying a developer convenience and expecting it to behave like a testing function.
What 'AI' means in AI E2E testing 2026
The first cut is structural. Ask where the AI sits in the workflow. Does it patch a human-written test, assist a human who still authors the suite, or own the test lifecycle from planning through maintenance?
| Tier | Where AI sits | Examples | Small-team reality |
|---|---|---|---|
| AI-bolted-on | Repairs scripted tests | Selenium IDE + plugin | Still manual ownership |
| AI-assisted scripting | Translates test steps | Shortest, ZeroStep, Auto Playwright | Faster authoring, same backlog |
| AI-native | Owns planning and maintenance | Autonoma, Magnitude, Skyvern | Testing function without QA headcount |
AI-bolted-on tools are useful when you already have a suite and the pain is selector churn. They do not decide what to test. They do not map a product surface. They do not remove the person who owns the test backlog. For a no dedicated QA function team, that means the bottleneck moves only a little.
AI-assisted scripting is the most visible part of the LLM-agent OSS wave because it fits into familiar Playwright files. Shortest, ZeroStep, Stagehand, Midscene.js, and Auto Playwright all reduce locator work. The developer still has to choose flows, write test boundaries, interpret failures, and decide when coverage is enough. That is a meaningful ergonomic improvement, but it is not a replacement for a QA function.
AI-native tools change the shape of the work. The agent reads application context, plans browser-level coverage, generates the run, replays it against the running app, and updates the suite as the UI changes. That is why AI-native is the important term for AI E2E testing in 2026. The point is not that an LLM is present. The point is that the operating burden changes.
If you want the broader definition layer, start with what an AI QA agent actually does and then come back here for the E2E-specific landscape. For the architecture comparison, use agentic testing vs traditional automation. For the glossary answer, use what is agentic testing. The agent category explains the role; this article explains which 2025-2026 tools can plausibly own browser coverage for teams that need to catch bugs before they reach production.
The 2025-2026 LLM-agent OSS wave
The LLM-agent OSS wave is the set of recent projects that apply LLMs, browser agents, vision models, and Playwright-adjacent primitives to test generation or browser automation. The important reading habit is to keep scope and license separate. A project can be open source but not E2E. It can be AI-native but not a testing platform. It can be an OSS client while the model brain remains hosted elsewhere.
- Autonoma: AI-native E2E platform built on four agents: Planner and Diffs Agent lead as the primary pair, with Executor and Reviewer as secondary agents that run and grade the results. License note: see the dedicated open-source page for exact license language; this article uses the fully-OSS-platform framing from the no-QA-team batch contract.
- Magnitude: Vision-first browser agent. License note: Apache-2.0 repository; useful AI-native comparator, but not a full regression-testing operating layer by itself.
- Shortest: Natural-language E2E framework built on Playwright. License note: MIT client; execution depends on Anthropic model access.
- Stagehand: Browserbase SDK with act, extract, observe, and agent primitives. License note: MIT; model calls route through configured providers rather than a self-contained inference stack.
- Midscene.js: Vision-driven UI automation for web, desktop, and mobile interfaces. License note: MIT; page screenshots go to the model provider you configure.
- Skyvern: AI browser automation platform for web workflows. License note: AGPL-3.0; strong browser-agent project, broader than regression testing.
- Passmark: Playwright library for AI regression testing with caching and auto-healing. License note: package metadata declares FSL-1.1-Apache-2.0, so do not flatten it into simple MIT or Apache language.
- Playwright Test Agents: First-party planner, generator, and healer agent definitions for Playwright. License note: Playwright is Apache-2.0; these are primitives, not a complete platform.
- Keploy: API, integration, and unit testing agent based on production traffic and sandboxes. License note: Apache-2.0; important adjacent tool, but API-not-E2E for this article.
- EvoMaster: Search-based system test generation for web APIs. License note: LGPL-3.0; evolutionary-not-LLM, and not browser E2E.
That list is intentionally mixed because the SERP is mixed. High-authority pages for AI-powered e2e testing still collapse libraries, agents, API generators, and platforms into one roundup. The better mental model is to ask what job the tool owns after installation. Does it generate one file? Does it run one browser action? Does it operate the coverage lifecycle?

From OSS client to full platform, hosted model to self-hostable inference.
This is where no-QA-team buyers need to be blunt. If a tool accelerates test writing but leaves your engineering team to maintain every flow, it may still be worth using, but it does not solve the "we hear about it real quick" problem when a customer finds a broken checkout, onboarding path, or permissions edge case in production.
OSS-client vs fully-OSS-platform
The most important license nuance in the LLM-agent OSS wave is the difference between an OSS client and a fully-OSS-platform. An OSS client is code you can inspect and fork, but the important intelligence may still live behind a hosted model provider or service. A fully-OSS-platform gives the team control over the orchestration layer, execution environment, artifacts, and AI inference path.

OSS clients expose code; a full platform also keeps the model path in-house.
ZeroStep and Shortest are clean examples of the OSS-client pattern. The client code is MIT. The workflow is developer-friendly. But the AI layer depends on hosted model access. That is not a scandal, and it is not vendor-bashing. It is simply a different risk profile from a platform that a startup can self-host, inspect, and route through customer-controlled model infrastructure.
For no-QA teams, that distinction affects more than procurement language. If every run calls a hosted model, test data and page state may leave your environment. If the model provider changes latency, cost, or behavior, your testing layer inherits that instability. If the tool is only a client, your team still owns CI, test history, retries, artifacts, and failure review.
Autonoma is positioned here as the AI-native fully-OSS-platform reference because the article's concern is not license purity for its own sake. The concern is whether a small team can run AI E2E testing as an operating layer: codebase-aware planning, generated browser coverage, replay against the running app, and review or maintenance without building a separate QA function. The broader license and self-hosting distinctions live in the open-source AI test generation tools guide, and the practical buyer question is whether your team controls enough of the stack to trust it.
That is why the phrase fully-OSS-platform matters. It names the difference between a repo that helps a developer write tests and an operating layer that can become the team's pre-production safety net. For an engineer who says "we don't have any QA", the second category is the one that can turn AI E2E testing from a neat experiment into a no brainer.
A useful screening question is: what happens on the tenth run? On the first run, almost every AI-assisted demo looks impressive. A model interprets a page, clicks through a flow, and produces evidence that feels better than an empty test directory. The tenth run exposes the architecture. If every run still asks a hosted model to reinterpret the same page, your cost and latency scale with coverage. If the generated output is just a script, your team owns the next refactor. If the platform records what it learned, replays stable actions, and asks AI to re-enter only when the product changes, the test suite starts behaving like infrastructure instead of a prompt.
The second screening question is: who reviews drift? A no-QA-team startup can tolerate a little setup work. It cannot tolerate an unowned weekly ritual where someone scans flaky failures, updates selectors, rewrites assertions, and decides which failures were product bugs. That is where the OSS-client vs fully-OSS-platform distinction becomes practical. The client can be excellent and still leave the review loop with engineering. The platform has to carry enough context to keep the suite aligned with the app.
How Autonoma covers AI E2E testing for no-QA teams
The pain this article documents is not "we need a nicer syntax for Playwright." It is the missing testing function inside small engineering teams. When nobody owns E2E coverage full-time, the suite decays, regressions escape, and the team starts treating production feedback as the real QA loop.
Autonoma covers that gap with four agents that map directly to the AI E2E testing lifecycle. Planner reads the codebase, plans the flows worth covering, and can generate the endpoints needed to set up database state for a test. Diffs Agent runs on every pull request, adding, deprecating, or updating test cases as the code diff changes what the app does. Executor runs the planned tests against a live preview environment. Reviewer classifies each result as a real bug, an agent error, or a mismatch between the test plan and the current app. Planner and Diffs Agent are the primary pair that keep coverage planned and current; Executor and Reviewer are the secondary pair that run the suite and grade what happened.
For a no-QA team, Planner replaces the missing test-planning meeting. Nobody has to sit down and enumerate every onboarding, billing, permissions, or settings flow from memory. Diffs Agent replaces the empty sprint ticket that says "add E2E tests later," because it updates the suite every time the code changes. Executor replaces the false confidence of code review alone. Reviewer replaces the neglected maintenance chore that usually kills the suite after the third UI refactor.
That is the small-team adoption story: AI-generated AND AI-maintained tests. The point is not that engineers stop caring about quality. The point is that engineers stop being forced to choose between shipping the feature and maintaining the safety net. With an AI-native fully-OSS-platform, the test layer keeps following the app even when there is no QA reviewer waiting at the end of the pull request.
AI E2E testing for the no-QA-team reader
A founding engineer does not usually wake up wanting a testing taxonomy. They wake up with a production bug, a Sentry alert, a customer Slack thread, or a founder saying "we hear about it real quick." The purchase trigger is the same even when the search query is category-level: the team needs to catch bugs before they reach production, and there is no dedicated QA function to absorb the work.
What AI E2E testing changes for a no-QA team
AI-powered e2e testing changes the adoption curve in three ways. First, coverage can start from the codebase instead of from a blank spreadsheet of test cases. Second, the first version of a suite is not the end of the work, because the system has to maintain coverage as the product changes. Third, the output is still browser-level evidence that engineers can inspect, not a vague quality score.
That is different from hiring a QA engineer, and it is different from asking a coding agent to write a few Playwright tests. Hiring creates a human function. Generic code generation creates artifacts that someone still has to own. AI E2E testing creates an operating layer that handles the routine coverage loop so engineers can spend review time on product risk, not selector archaeology.
The function you cannot hire yet
The ICP carveout matters. Seed to Series A startups, small engineering teams, engineers shipping without a QA hire, and companies with no dedicated QA function get the most leverage. A larger organization with a mature QA platform team may want primitives, integrations, and migration controls. A team of 3 to 20 engineers wants the missing function: plan, maintain, run, review, repeat.
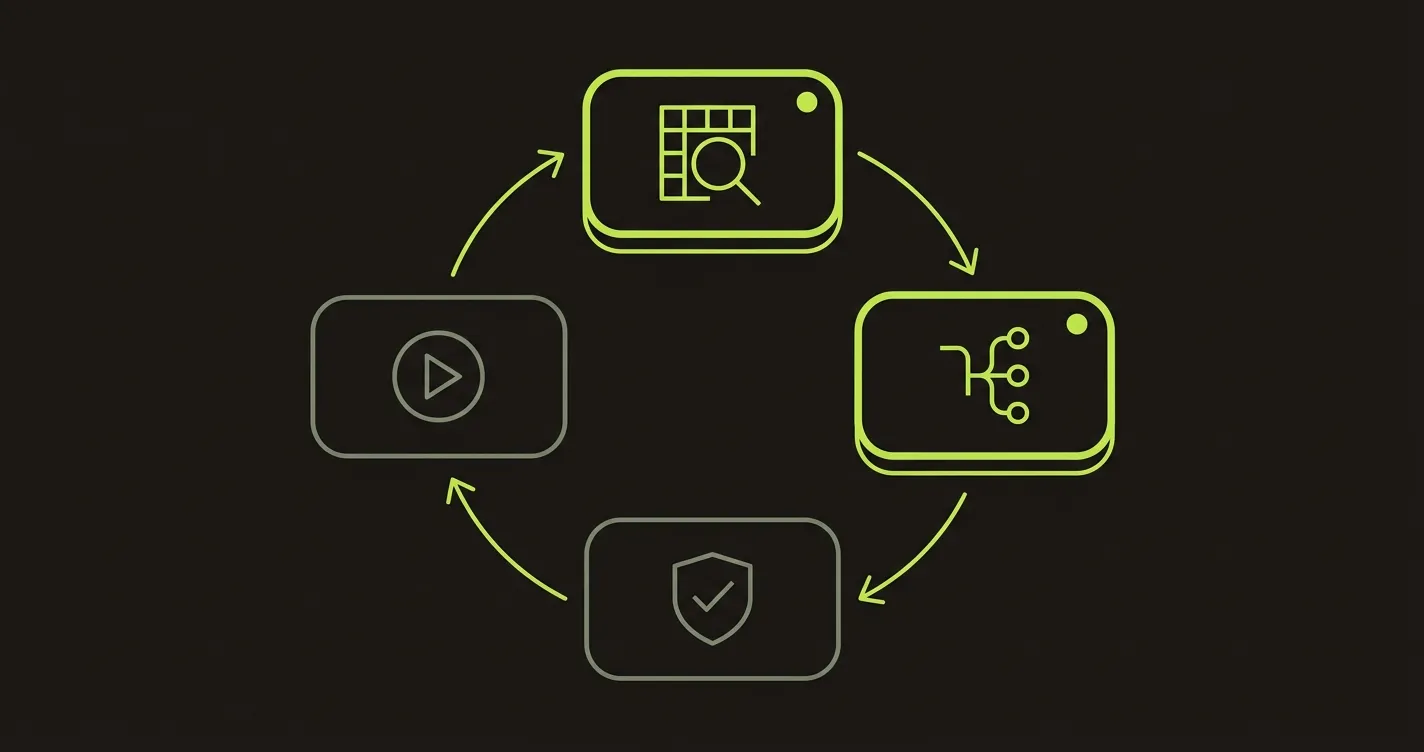
Planner and Diffs Agent lead the loop; Executor and Reviewer close it, and it reruns every time you ship.
There is also a social reason AI E2E testing lands differently in small teams. A QA hire is not only a person who writes test cases. They become the memory of the product: which flows are fragile, which customer promises cannot regress, which admin-only paths are easy to forget, which third-party callback breaks when a fixture changes. When that person does not exist, the memory has to live somewhere else. A hand-written Playwright suite can hold some of it, but only if engineers keep feeding it. An AI-native operating layer can hold more of it because it is designed to re-read the product as the product changes.
This is why "AI-generated" is only half the phrase. The first generation moment gets attention because it is visible. A suite appears where there was no suite. But the value compounds only when the maintenance loop is also handled. In small startups, the failure mode is not that nobody can write the first test. The failure mode is that the next five features ship, the DOM changes, roles move, empty states get redesigned, permissions are renamed, and no one has the spare cycle to keep the suite honest.
Reliability comes from boundaries, not cleverness
Reliability in 2026 therefore depends less on model cleverness and more on boundaries. A good AI E2E testing system should preserve evidence: what was planned, what was generated, what was replayed, what failed, what changed, and what a reviewer concluded. Without that chain, a model's confidence is just another opaque signal. With that chain, an engineer can inspect the output in the same way they inspect a CI failure, a trace, or a pull request comment.
Where AI-assisted tools still fit
The AI-assisted scripting tier is not obsolete. It is useful when a team already has developers who like owning test files and only wants to remove low-level browser friction. Shortest can make a test read closer to the intent of the flow. ZeroStep can reduce selector work inside existing Playwright tests. Stagehand and Midscene.js can make browser actions more resilient when page structure shifts. Auto Playwright can speed up scaffolding. Those are real advantages, especially for teams that want to keep test authorship close to code.
The boundary is ownership. AI-assisted tools fit when the team can answer four questions without creating a new role: who chooses the flows, who adds the assertions, who reviews failures, and who updates coverage after product changes? If the answer is "the feature engineer who already owns the PR," then assisted scripting may be enough. If the answer is "nobody, because we are already stretched," then the category is wrong even if the tool is good.
Keploy and EvoMaster fit a different boundary. They are valuable for API-side generation, integration tests, and service-level coverage. They should not be forced into the browser E2E bucket simply because they generate tests automatically. The same is true in reverse: a browser E2E platform should not pretend to replace API fuzzing, unit tests, contract tests, or production monitoring. The stack is stronger when each layer keeps its job.
Playwright Test Agents are the most interesting primitive because they make the planner, generator, and healer vocabulary mainstream. They give developers a way to see the agentic workflow inside a toolchain they already trust. But primitives still need an operating model around them: environment setup, test history, artifacts, retries, review, ownership, and the decision of when generated coverage is good enough for release.
What to adopt now
If you are evaluating AI end-to-end testing in 2026, do not start by asking which tool "has AI." Start by asking what work disappears from your team after the tool is installed. If the answer is only "locator writing gets easier," you are in the AI-assisted scripting tier. If the answer is "the suite is planned, generated, replayed, and maintained without a QA hire," you are in the AI-native platform tier.
Use Selenium IDE plugins, Auto Playwright, ZeroStep, Shortest, Stagehand, and Midscene.js as baseline pain explanations or tactical accelerators. They can help a developer move faster, and some teams will prefer that control. Use Keploy and EvoMaster for API-side generation where they belong. Use Playwright Test Agents as promising primitives for planner, generator, and healer workflows.
The practical rollout should be narrow, not ceremonial. Pick one flow that would embarrass the company if it broke: signup, checkout, invitation, billing, file upload, or the workflow your largest customer uses every week. Ask whether the tool can plan the flow, generate browser-level coverage, replay the evidence, and survive a real UI change. Then add the next flow. The goal is not a giant test-migration project. The goal is to make the release path safer without creating a new maintenance queue.
Whatever your QA maturity, that narrow rollout is the difference between adoption and shelfware. If the first week produces more triage work than confidence, the tool gets ignored. If the first week produces a maintained critical-flow suite, the team starts trusting the gate. That trust is what converts AI E2E testing from an experiment into release infrastructure, and it is the same dynamic whether the team has no testers or fifty.
So be specific about who this is for, because the answer is the same across the board. With no QA team, Autonoma is the function you cannot hire yet: Planner plans the flows that matter, Diffs Agent keeps that plan current on every pull request, Executor runs it against a live preview environment, and Reviewer classifies what happened, so production stops being your test environment. With a small QA team, Autonoma removes the maintenance grind that eats the week, so two testers cover what used to take six and spend their judgment on real product risk instead of selector archaeology. With a large QA org, Autonoma scales coverage no human can hand-author or keep current across hundreds of flows, and frees senior QA to own strategy instead of upkeep. The headcount changes. The leverage does not.
That is why the answer to "which AI E2E testing tool" does not depend on the size of your QA team. The same four agents, Planner and Diffs Agent leading, Executor and Reviewer close behind, are the engine whether you have zero testers or fifty, which is why it fits a team with no QA and a team with a full QA org without changing what it does. Start with Autonoma: connect the repo, get maintained coverage on the next PR, and stop hearing about bugs from customers first.
FAQ
AI E2E testing is end-to-end browser testing where AI helps plan, generate, execute, or maintain tests across real user flows. In 2026, the useful distinction is whether AI is only patched onto scripted tests, assisting a developer who still writes the suite, or acting as an AI-native operating layer that creates and maintains coverage from the codebase.
It is reliable when AI is bounded by verification, replay, and review rather than allowed to improvise on every run. The strongest pattern uses AI to generate and maintain tests, then replays browser-level checks against a running app so the team can inspect deterministic artifacts.
Yes, but the details vary by tool. Some projects are OSS clients that call hosted model providers. Others let you run more of the platform yourself. Autonoma is framed here as the fully-OSS-platform reference because the platform is self-hostable and the AI inference path can be routed under customer control.
Playwright is the browser automation engine. AI E2E testing is the layer above it that decides what to test, generates the browser-level coverage, replays it, and maintains the suite when the app changes. Many AI E2E tools still use Playwright underneath.
No. The main adoption story for no-QA teams is that tests can be AI-generated and AI-maintained, so engineers do not need a dedicated QA function to write every test case, triage every flaky selector, or keep coverage current after each release.



