
A self-hosted E2E testing platform is a test infrastructure stack where runners, browser pools, and artifact stores all run on infrastructure you control, with the option to route LLM inference to a model endpoint you operate so test data and application traffic stay on your own infrastructure. In 2026, the canonical reasons to self-host are data residency requirements, SOC 2 Type II audit obligations, Schrems II-driven EU data sovereignty, and the option to keep LLM inference on-prem when test fixtures contain PII. Autonoma is open source and self-hostable, with PreviewKit providing per-PR ephemeral environment namespaces as the substrate.
Building a self-hosted E2E testing platform in 2026 is no longer about dropping Selenium Grid onto a VM. It is about controlling all four layers of the stack: where runners execute, where artifacts land, where browsers render, and where AI inference happens. Most teams get one or two of those right and call it done. The rest of this guide explains why that is not enough, and what a complete architecture actually looks like.
We will walk through what "self-hosted" means at each layer, why compliance teams are forcing this question in 2026, what the reference architecture looks like, and how the incumbent options (Selenium Grid, Selenoid, Moon, Playwright sharding) hold up against a modern full-platform answer.
What a self-hosted E2E testing platform actually covers
The phrase gets used loosely. Teams often say "self-hosted" when they mean "we run the test runner on our CI." That is runner placement, and it is just one of the four layers that matter for genuine data residency.
Runner placement is where test execution logic runs. A self-hosted GitHub Actions runner or a Jenkins agent on EC2 counts. Most teams already have this. It means your test code never leaves your environment. It does not protect you if the runner phones home to a SaaS dashboard for results.
Artifact placement is where screenshots, videos, HAR traces, and test result metadata land. A fully self-hosted stack writes all artifacts to your own object store (S3-compatible, on-prem NAS, or GCS bucket you control). The moment artifacts upload to Cypress Cloud or BrowserStack, data residency is broken regardless of where the runner lives.
Browser placement is where actual browser processes execute. Selenium Grid, Selenoid, and Playwright sharding all let you run browsers on your own hardware or in your own Kubernetes cluster. Cloud browser farms (BrowserStack, Sauce Labs, LambdaTest) run browsers on vendor infrastructure. The distinction matters when your application under test handles protected data: every network request and page render happens inside the browser, and a cloud browser on vendor iron means that traffic transits outside your boundary.
AI/LLM placement is the layer that 2024-era self-host guides never had to consider. AI-assisted test generation and self-healing now depend on LLMs. If your test infrastructure sends code snippets, DOM snapshots, or selector strings to OpenAI or Anthropic's cloud APIs, you have a PII exfiltration risk if those fixtures contain real customer data. On-prem LLM inference (Ollama, vLLM, or a locally deployed model) closes that gap. Autonoma can be configured to route inference to a customer-operated model endpoint (Ollama, vLLM, or a private deployment) so prompts and DOM snapshots stay on infrastructure you control. The default managed configuration uses a hosted model provider; on-prem inference requires you to stand up and point Autonoma at your own model endpoint.
True self-hosted E2E testing means all four layers stay inside your boundary. Most "self-hosted" options address only one or two.
Why teams are asking this question in 2026
The question has always existed, but four forces converged in 2024 and 2025 to make it urgent in 2026.
SOC 2 Type II audit pressure. SOC 2 audits have moved from a sales checkbox to an operational obligation for B2B SaaS teams. Type II audits require continuous evidence of data flow controls, not just a policy doc. When auditors ask "where does test data go?", the answer "to a third-party SaaS we don't control" triggers a finding. Security teams are now demanding that test infrastructure produce the same attestations as production infrastructure. Self-hosted runners with internal artifact stores satisfy that requirement; SaaS dashboards with opaque data retention policies do not.
SaaS vendor lock-in and pricing inflation. Cloud testing platforms moved to per-test or per-parallel-run pricing models and increased prices substantially after 2023. Teams that built CI workflows tightly coupled to a vendor's test recording or analytics features found migration painful. The combination of rising cost and low portability is pushing platform engineering teams toward open infrastructure they own.
Data sovereignty post-Schrems II. The EU-US Data Privacy Framework has faced repeated legal challenges. Engineering teams at EU-headquartered companies, or US companies with EU customer data, cannot assume a framework will survive the next challenge. Self-hosted infrastructure inside an EU datacenter removes the cross-border transfer question for runners, browsers, and artifacts. Data does not cross the Atlantic if your test pipeline stays inside an EU-region VPC and inference is routed to an EU model endpoint.
AI/LLM data exfiltration concerns. This is the newest pressure point. AI-assisted testing tools that connect to cloud LLMs create a subtle but real exfiltration risk: test fixtures often contain anonymized-but-real-shaped user data, and DOM snapshots fed to a cloud model may leak structure that a sophisticated adversary could reverse. Regulated industries (healthcare, financial services, defense) are beginning to mandate on-prem LLM inference as a data handling control. Self-hosted E2E with on-prem LLM inference addresses this. Self-hosted E2E with cloud AI inference does not.
Self-hosted E2E testing reference architecture
A complete self-hosted E2E architecture for a Kubernetes-native team looks like this: CI triggers a job on a self-hosted runner. The runner pulls the test binary, resolves the target URL from the per-PR ephemeral environment, and dispatches browser sessions to a browser pool running in a separate Kubernetes namespace (or a dedicated node pool). The application under test runs in its own isolated namespace, spun up by PreviewKit from the PR branch. Artifacts (video, trace, screenshots) write to an internal S3-compatible bucket. LLM inference calls can be routed to a model endpoint you operate (on-prem or in-VPC) when configured; in the default setup, prompts go to the configured model provider. With an in-VPC model endpoint configured, nothing in this flow touches the public internet except outbound DNS and package pulls, which can themselves be proxied through your internal mirror if you need air-gap compliance.
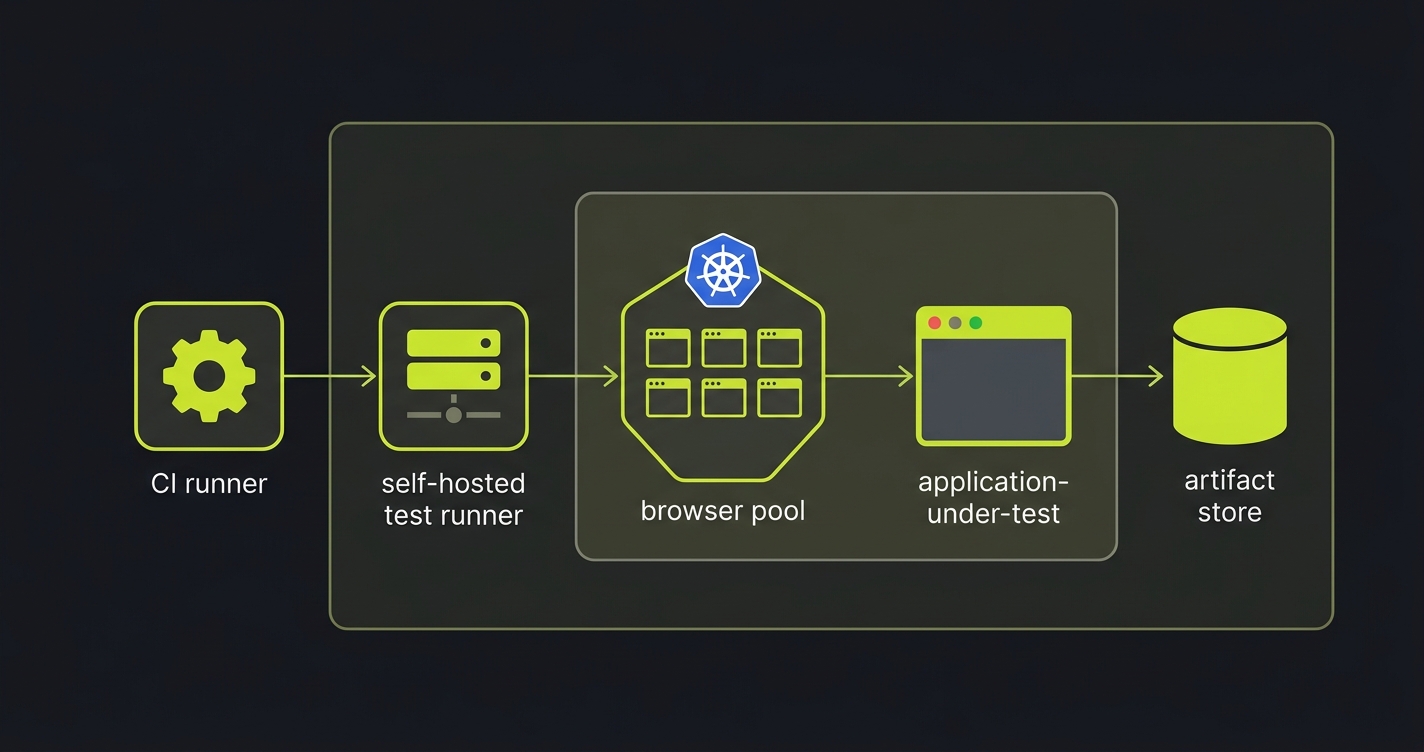
PreviewKit's namespace isolation per PR is the substrate that makes this architecture composable. Each pull request gets its own Kubernetes namespace containing the application stack (web, API, worker, database, cache). The namespace is ephemeral: it provisions on PR open, runs tests, and tears down on merge or close. Because the namespace is fully isolated, browser sessions run against a production-shaped environment with real data shapes rather than a shared staging environment polluted by other developers' work.
The key invariant: every component in this diagram (runner, browser pool, AUT namespace, artifact store, LLM endpoint) is a resource you declare, deploy, and own. The orchestration layer coordinates across them without requiring runner, browser, or artifact data to leave your boundary; LLM traffic follows whichever model endpoint you configure.
Selenium Grid is the legacy self-host pattern
Selenium Grid has been the default self-host answer for browser automation since 2012. It is still a valid answer for one specific case: teams that need multi-browser parallel execution and are already running Java-based Selenium suites. For every other case in 2026, it is the wrong starting point.
The Grid model is a hub-and-node topology: a hub receives RemoteWebDriver requests and dispatches them to registered nodes that each run a browser. It works. The problem is what you build around it: you need a test framework (Selenium is a library, not a platform), a test runner, an artifact storage layer, a dashboard, and a way to spin up the application under test. None of that comes with Grid. You are assembling a platform from components, and the seams between them are your problem to maintain.
Selenoid solves the node-management problem elegantly: it replaces the node layer with Docker containers, spinning a fresh browser container per session and destroying it after. The browser pool scales horizontally and sessions are isolated. Selenoid is a real improvement over Grid's persistent-node model. The concern in 2026 is maintenance trajectory: per its own README, Selenoid is in minimal-maintenance mode. Bug fixes happen, but active development has stopped. For new infrastructure, building on a minimal-maintenance foundation is a risk.
Moon is the commercial fork of Selenoid with Kubernetes support, a proper operator, and active development. It is a solid browser pool. It requires a commercial license for production scale, which re-introduces vendor dependency (different from SaaS lock-in, but not free). Moon solves browser pool management; it does not solve the platform assembly problem.
Sorry Cypress is the self-hosted Cypress dashboard equivalent: it gives you the result recording and parallelization coordination that Cypress Cloud provides, without sending data to Cypress Inc. If you are already committed to Cypress, Sorry Cypress is the right self-host answer for the dashboard layer. Its scope is narrow by design: it covers Cypress specifically and does not generalize to other frameworks.
Playwright sharding is frequently described as "self-hosted E2E." It is more precise to call it a runner distribution pattern. Playwright's --shard N/M flag splits a test suite across N workers, each running independently. You can run those workers on self-hosted CI agents with full data residency. Playwright is a library, not a platform: it does not include a browser pool manager, an artifact dashboard, ephemeral environment provisioning, or AI assist. When teams say "we run Playwright self-hosted," they mean the runner is theirs. The platform is whatever they built around it.
The answer for teams who want to skip the platform assembly problem entirely is a full-platform self-hosted E2E solution, where the runner, browser pool, ephemeral environments, artifact storage, and AI layer are all provided as a unit rather than assembled from components. That is what the next section covers.
When "self-hostable" is a marketing qualifier
Some platforms rank prominently for self-hosted test automation queries and then steer readers toward their SaaS offering. Worth knowing before you shortlist.
AccelQ markets an on-prem option, but in practice its AI inference layer runs against cloud LLMs. "On-prem" here means the execution engine is on-premises; the intelligence layer is not. For teams whose self-host requirement is specifically about LLM data residency, this distinction matters.
The honest reason platforms describe SaaS-first offerings as "self-hostable" is operational cost. Running a fully self-hosted platform requires version upgrades, migration scripts, customer-specific deployment support, and air-gap documentation. SaaS concentrates that cost. When a vendor says "we have an on-prem option, but most customers choose cloud," the on-prem option exists but the investment behind it is lower.
Comparison: self-hosted E2E options (2026)
| Tool | Self-hostable | On-prem AI/LLM | Data residency | License / Pricing |
|---|---|---|---|---|
| Autonoma | Yes | Yes (customer-provided model endpoint) | Runner/browser/artifacts in-VPC; LLM follows configured endpoint | Source-available (open core), OSS + managed cloud |
| Selenium Grid | Yes | N/A | Full | Apache 2.0 / free OSS (library only) |
| Selenoid / Moon | Yes | N/A | Full | Selenoid OSS / Moon commercial |
| Sorry Cypress | Yes | N/A | Full | MIT / free OSS |
| Playwright + custom | Yes (you build the platform) | N/A | Full | Apache 2.0 / free OSS (library only) |
| Cypress Cloud | No | No | US/EU regions (vendor) | Proprietary SaaS, per-test usage |
| Mabl | No | No | Regional (vendor) | Proprietary SaaS, enterprise quote |
| BrowserStack | No (local agent only) | No | Regional (vendor) | Proprietary SaaS, per-parallel tier |
| Sauce Labs | No | No | Regional (vendor) | Proprietary SaaS, per-parallel tier |
| ACCELQ on-prem | Yes (on-prem option) | No (cloud LLM) | Customer-controlled | Proprietary on-prem, enterprise quote |
| Ranorex | Yes (desktop) | No | Full | Proprietary, per-seat license |
| Digital.ai | Yes | No | Full | Proprietary, enterprise quote |
| QA Brain | Yes | Yes (claimed) | Full | Partial OSS, tiered |
| Karate Agent | Yes | Yes (configurable) | Full | Karate OSS + enterprise tier |
Note on Selenium and Playwright in this table: both are libraries, not platforms. "Self-hostable" for them means you are responsible for building and operating all the platform layers (browser pool, artifact store, dashboard, AI assist) yourself. A full platform provides those layers as part of the product.
How Autonoma's PreviewKit operates self-hosted E2E testing
Most E2E infrastructure discussions treat the test framework and the environment as separate decisions. You pick a runner (Playwright, Cypress), then separately figure out where the application runs. This is the source of most self-host complexity: teams end up maintaining a Selenium Grid for browsers, a staging cluster for the application, an artifact store, and a dashboard, all wired together with glue scripts. The seams between those components are where compliance controls break down.
The platform owns the full stack, not just the test layer. PreviewKit handles ephemeral environment provisioning as a first-class capability. When a PR opens, a .preview.yaml at the root of your repo defines the environment shape: which services compose the stack, how they are built (Railpack detects language and produces OCI images via BuildKit with layer caching), and what database seed state the Planner agent should establish. PreviewKit spins a Kubernetes namespace for that PR and registers the environment endpoint with the agent layer.
The Planner agent reads your codebase (routes, component tree, user flows, API contracts) and generates a test plan against that specific PR's namespace. The Automator agent executes browser sessions against the per-PR URL, with all browser traffic staying inside the VPC. The Maintainer agent patches tests when code changes break selectors or flow assumptions. At no point does orchestration or artifact handling phone home: those run inside your boundary. Inference follows your configured model endpoint. Point Autonoma at an in-VPC model server (Ollama, vLLM, a private hosted deployment) and inference stays in-boundary too.
The Environment Factory SDK is the escape hatch for complex state setup. Your .preview.yaml can reference factory endpoints that the Planner agent calls to put the database in the right state for a specific test scenario. factory.up() establishes the state before the test run; factory.down() tears it down after. Because the factory endpoints run inside the same Kubernetes namespace as the application, they never require a connection outside the VPC boundary.
For teams with air-gap requirements, the LLM inference component can point to an on-prem model server, and the orchestration layer continues to function without modification. For the detailed mechanics of how per-PR ephemeral environments provision and tear down, see how Autonoma preview environments works.
Honest limitations of self-hosting
Self-hosting gives you data sovereignty. It also hands you a set of operational responsibilities that SaaS vendors handle invisibly.
Browser pool maintenance. You own the browser image update cycle. When Chrome ships a new major version, you need to pull a new browser image, test it against your suite, and roll it out to the pool. In a SaaS platform, the vendor absorbs this work. Self-hosted, it is a recurring task on your platform team's backlog. Selenoid and Moon handle the image pull; you still own testing the new version against your suite.
Scaling and capacity planning. SaaS platforms scale browser capacity on demand. Self-hosted, you set resource requests and limits for browser pods and handle saturation when large test runs hit the pool. Over-provisioning wastes cost; under-provisioning creates queue depth.
Runner image security updates. Self-hosted CI runners need regular OS and dependency patches. A stale runner image is a security liability. Most teams underestimate how much friction this creates over 12-18 months.
Observability stack. SaaS platforms provide built-in test result dashboards, flakiness tracking, and trend views. Self-hosted, you build these from Prometheus metrics, Grafana dashboards, or a test results database you maintain yourself. A full self-hosted E2E platform may include an observability layer, but you remain responsible for the underlying monitoring infrastructure (cluster health, disk usage, network saturation).
The trade-off framing: if data residency, compliance posture, or pricing control are the primary drivers, the operational burden of self-hosting is justified. If speed-to-value is the primary driver, the managed SaaS path gets you running faster with fewer operational concerns. Both are legitimate choices, and the right answer depends on which constraint is binding.
Picking the right self-hosted test automation approach
Self-host if compliance, data residency, or long-run cost control is the binding constraint. The operational burden is real, but it is the price of sovereignty. Choose SaaS if speed-to-value is what matters most: managed platforms handle browser pools, artifact storage, and scaling so your team ships features instead of maintaining infrastructure.
If you need full data residency without building and wiring the platform layers yourself, Autonoma deploys into your VPC with per-PR ephemeral environment namespaces and the agent layer for test generation and maintenance; LLM inference can be routed to a model endpoint you operate when on-prem AI is a requirement. For HIPAA environments where test fixtures may contain PHI, see the dedicated HIPAA-compliant E2E testing guide. For EU data-residency requirements under GDPR, the GDPR-compliant test automation guide covers the cross-border transfer analysis. For a broader view of the OSS test tooling landscape, the best open-source test automation tools in 2026 roundup puts the self-hosted options in context.
For teams exploring adjacent topics: per-PR preview environments with full-stack isolation are covered at per-PR preview environments with tests, and the ephemeral environment lifecycle at ephemeral environments per PR with testing.
FAQ
With SaaS test automation (Cypress Cloud, BrowserStack, Mabl, Sauce Labs), the vendor runs the browser pool, stores your artifacts, and manages the dashboard. Setup is fast and operational burden is low. The tradeoff is that test data, screenshots, DOM snapshots, and in some cases application traffic transit through vendor infrastructure. This matters when test fixtures contain PII, when a SOC 2 Type II audit requires you to document and control every data flow, or when GDPR data-residency rules prohibit cross-border transfers. With a self-hosted E2E testing platform, you run the runners, browser pool, and artifact store inside your own network boundary, and can point AI inference at a model endpoint you operate. You own the operational burden (image updates, scaling, observability) but test data stays on infrastructure you control. For regulated industries, defense contractors, and companies under Schrems II pressure, the self-hosted path is often not optional, just a question of which tool and architecture to use.
Playwright is a library, not a platform. When you run a Playwright test on your own CI runner, the test execution is self-hosted in the sense that it runs on your infrastructure. But that does not make your test infrastructure self-hosted at every layer. Artifacts (screenshots, traces, videos) go wherever your suite writes them. If you use Playwright Test's built-in reporter and write results to disk, they stay local. If you use a third-party dashboard service for analytics or parallelization coordination, results leave your boundary. AI features (if any) depend on where the underlying model runs. Self-hosting Playwright means self-hosting the entire surrounding platform, not just the library itself.
The Cypress test runner is open source and runs anywhere: your laptop, a self-hosted CI agent, a Kubernetes job. So yes, the execution layer is self-hostable. Cypress Cloud (test recording, analytics, parallelization orchestration, flakiness tracking) is SaaS. If you want Cypress's execution on self-hosted infrastructure with a self-hosted dashboard, Sorry Cypress is the open-source dashboard equivalent. It provides the recording and parallelization coordination without sending data to Cypress Inc.
Self-hosting is a precondition for HIPAA compliance when test data contains PHI, but it is not a complete answer. You still need a signed BAA with any vendor whose infrastructure touches PHI (including cloud storage providers if you use them for artifacts), audit logs on all data access, access controls limiting PHI exposure to authorized personnel, and a breach notification process. Self-hosting your E2E infrastructure removes the test runner and browser pool from the vendor-attestation problem. It does not remove other PHI-adjacent systems from scope.
The honest answer depends on what you want from the replacement. If you want zero infrastructure overhead and data residency is not a constraint: Cypress Cloud, BrowserStack, or Sauce Labs handle browser pool management and artifact storage for you. If you want a modern OSS Grid replacement for the browser pool specifically: Selenoid (minimal maintenance mode) or Moon (commercial license) both improve on Grid's node management with Docker-based session isolation. If you want the full self-hosted platform (runner, browser pool, per-PR ephemeral environments, AI test assist, artifact storage, observability) without assembling it from components yourself, Autonoma with PreviewKit is the answer.



