
Most teams shopping Sentry alternatives are not unhappy with Sentry. They are unhappy that bugs reach Sentry at all. This article groups alternatives by job-to-be-done: cheaper drop-in replacements (GlitchTip, Bugsink, Honeybadger), better DX tools (Rollbar, Bugsnag), comprehensive observability platforms (PostHog, BetterStack, SigNoz), and prevent-not-just-detect tools that stop bugs before deploy (Autonoma, Checkly, Playwright). Autonoma is in category 4. It is NOT a 1-to-1 Sentry swap.
If you run a Seed or Series A startup with a 3-to-8-person engineering team and no QA hire, you have probably said some version of "we hear about it real quick" when describing how you discover bugs in production. That is what Sentry is for. We built Autonoma so that same 3-engineer team without a QA hire can catch the bugs that would otherwise become Sentry alerts. Autonoma is NOT a Sentry replacement. Sentry catches errors in production; Autonoma catches them before deploy. Both belong in a complete safety net.
The rest of this article covers the full range of alternatives, with honest takes on each category.
Why are you shopping for a Sentry alternative?
The answer to that question changes which tool you actually need. Most people land on a listicle, scan the names, and pick the cheapest one without asking why they are shopping in the first place. There are four distinct jobs-to-be-done here, and conflating them is how you end up with the wrong tool.
The first job is "I like Sentry but the bill is too big." If you are sending tens of millions of events per month, Sentry's pricing tiers can get expensive fast. You are not unhappy with the product. You just want the same error capture for less money, or for free if you self-host. GlitchTip, Bugsink, and Honeybadger sit in this category. They are drop-in Sentry replacements designed to accept the same SDK calls with minimal migration friction.
The second job is "Sentry's interface is heavy and I can't triage fast enough." Sentry does a lot. For a small team triaging bugs between feature sprints, the cognitive load of Sentry's UI can slow you down. Rollbar and Bugsnag trade some depth for speed: faster grouping, cleaner dashboards, faster time-to-resolution.
The third job is "I want errors, logs, and APM in a single pane of glass." Sentry is first and foremost an error tracker. If you also want request tracing, infrastructure metrics, and log aggregation, you end up running multiple tools. PostHog, BetterStack, and SigNoz each try to consolidate more of the observability stack.
The fourth job is the one nobody talks about in listicles: "I want fewer bugs to reach Sentry in the first place." This is pre-deploy bug detection. Instead of catching errors after users hit them, you catch them before the deploy lands. This is where shift-left testing lives, and it is what Autonoma, Checkly Synthetic monitoring, and Playwright are designed to address. If this is your actual pain point, reading a Sentry-alternatives article is the wrong frame. You need a prevention layer alongside your error monitor.
Category 1: Cheaper drop-in Sentry alternatives
GlitchTip
GlitchTip is the closest thing to a fully open-source Sentry drop-in that exists. It is BSD-licensed, self-hostable on a $5 DigitalOcean droplet, and accepts the Sentry SDK without any code change on your end. You point your dsn at your GlitchTip instance and you are done.
The honest pros: it is genuinely free if you self-host, it supports the full Sentry SDK surface (JavaScript, Python, Go, Rails, and more), and it handles the basics well: error grouping, stack traces, release tracking, and performance monitoring for smaller event volumes.
The honest cons: GlitchTip's performance monitoring is noticeably less polished than Sentry's. At high event volumes (100M+ events per month), self-hosting at that scale requires real infrastructure work. The community is smaller, so if you hit a bug in the platform itself, you are on your own.
SDK compatibility: full Sentry SDK compatibility. Change only the DSN. No code change required.
Bugsink
Bugsink is newer and more opinionated than GlitchTip. It is designed to be a lean, fast, single-binary alternative that you can run on a cheap VPS with almost no ops overhead. The focus is on error grouping quality and a clean interface, not on matching every Sentry feature.
The honest pros: extremely easy to self-host, fast setup, very low resource usage, clean UI that does not get in the way. The error grouping algorithm is solid for Python and JavaScript workloads.
The honest cons: Bugsink's feature set is intentionally limited. No session replay, no profiling, limited performance monitoring. If you need the full Sentry feature surface, Bugsink is not that. SDK compatibility is good for the core SDKs but less comprehensive for niche platforms.
SDK compatibility: core Sentry SDK compatible. Verify your platform in Bugsink's docs before committing.
Honeybadger
Honeybadger is the one paid option in this category that undercuts Sentry on pricing while offering a more developer-friendly experience. It is not self-hostable, but it has been around since 2012 and has a strong track record with Rails, Node, and Python teams.
The honest pros: pricing starts at $29/month for small volumes and is predictable. The alerting and grouping are solid. Uptime monitoring is bundled in. The team is small and responsive.
The honest cons: no self-host option. Less ecosystem depth than Sentry for newer frameworks. If you are already deep in the Sentry ecosystem (source maps, releases, integrations), migrating to Honeybadger means some manual re-wiring.
SDK compatibility: Honeybadger uses its own SDK, not the Sentry SDK. Migration requires code changes, unlike GlitchTip or Bugsink.
Category 2: Sentry alternatives with better DX
Rollbar
Rollbar has been positioned as the faster-to-triage alternative to Sentry for years. The core proposition is "time-to-fix": from the moment an error lands to the moment it is assigned and acknowledged. Rollbar's deploy tracking, grouping, and assignment workflows are designed around that single metric.
The honest pros: faster error grouping out of the box, cleaner mobile for on-call engineers, solid deploy tracking tied to releases, and a Python/Rails ecosystem with deep integration history.
The honest cons: Rollbar's pricing has moved upmarket. The free tier is limited. For a startup at Seed stage, the cost-to-value calculation now sits closer to Sentry than it used to. The observability story beyond errors is thin.
SDK compatibility: Rollbar uses its own SDK. Migration requires code changes. The SDKs are well-maintained across JavaScript, Python, Ruby, Java, and Go.
Bugsnag
Bugsnag's strength is mobile. If you have a React Native, iOS, or Android app alongside your web frontend, Bugsnag gives you unified error tracking across all surfaces in one dashboard. That is genuinely hard to replicate with most Sentry alternatives.
The honest pros: best-in-class mobile error tracking, solid release health metrics, clean dashboard, and a feature called "stability score" that gives you a single health number per release. Good for teams shipping across web and mobile simultaneously.
The honest cons: pricing is enterprise-tilted. The self-serve tiers are functional but the pricing gets steep at scale. The observability story beyond errors and stability is limited. For pure web teams, the mobile differentiation does not justify the cost difference versus Sentry or GlitchTip.
SDK compatibility: Bugsnag uses its own SDK. Migration requires code changes. JavaScript, React Native, iOS, Android, Go, Java, Python, Ruby, and PHP are all covered.
Category 3: Comprehensive observability platforms (APM + logs + errors)
PostHog
PostHog is the most interesting tool in this category because it started as a product analytics platform and added error tracking later. That lineage shows. If you already use PostHog for analytics, enabling error monitoring costs nothing and lets you correlate errors with user journeys in a way that Sentry cannot.
The honest pros: the free tier is genuinely generous (1M events per month free). If you already use PostHog for funnels and session replay, adding error tracking is a no-brainer from a tooling consolidation standpoint. The error tracking UI is simpler than Sentry's, which is a feature for small teams.
The honest cons: PostHog's error monitoring depth is below Sentry's. Source maps work but the workflow is less polished. If error tracking is your primary use case (not analytics), PostHog is not the better choice.
SDK compatibility: PostHog uses its own SDK. The error capture is automatic via the PostHog JS SDK. No Sentry SDK compatibility.
BetterStack
BetterStack consolidates uptime monitoring, log management, and incident management under one roof. It is not primarily an error tracker. It is infrastructure observability that happens to include an error tracking layer.
The honest pros: if you want uptime checks, on-call scheduling, status pages, log aggregation, and error tracking in one tool, BetterStack is one of the cleaner options. Pricing is competitive and the onboarding is fast.
The honest cons: the error tracking is shallower than Sentry's. Stack traces are there, but grouping and root-cause analysis are weaker. For teams where error tracking is load-bearing (not just one of many signals), BetterStack is a compromise.
SDK compatibility: BetterStack uses its own SDK for logs and errors. No Sentry SDK compatibility.
SigNoz
SigNoz is the open-source observability platform that targets teams who want a self-hosted alternative to Datadog or New Relic, not just Sentry. It is OpenTelemetry-native, which means it works with the standard OTEL SDK rather than a vendor-specific one.
The honest pros: fully open-source (Apache 2.0), excellent distributed tracing, good log management, and the OpenTelemetry foundation means you are not locked in. Self-hostable on your own infrastructure.
The honest cons: SigNoz requires meaningful DevOps investment to run at scale. The setup is not as fast as a SaaS tool. Error tracking is part of the tracing story, not a standalone product. For teams without dedicated infra, the maintenance overhead can outweigh the cost savings.
SDK compatibility: OpenTelemetry SDK (not Sentry SDK). Migration requires meaningful code changes, but OTEL is the industry-standard direction.
Category 4: Prevent-not-just-detect tools (catch bugs before they reach Sentry)
When we talk to engineers at Seed to Series A startups, we hear about it real quick: they don't want a cheaper Sentry, they want fewer bugs to reach Sentry. The conversation almost always follows the same arc. They are paying for Sentry. They are also spending hours every sprint triaging errors that could have been caught before the deploy landed. They are not unhappy with Sentry. They are unhappy that so many bugs get through.
This is the prevention layer. None of the tools here are drop-in Sentry replacements. They sit upstream of Sentry, catching a different class of bug before it ever reaches production.
If you want to understand the full context for why small teams benefit from this approach, shift-left testing for small engineering teams covers the structural argument in more depth.
Autonoma
Autonoma is NOT a Sentry alternative. State that plainly: Autonoma does not capture runtime errors after they happen, does not do session replay of production sessions, and does not alert on prod stack traces. If you need those things, you need Sentry (or something from categories 1 through 3).
What Autonoma IS: a pre-deploy E2E testing platform built for engineering teams without a QA hire. Our Planner agent reads your codebase (routes, components, user flows) and generates test plans without you writing a single test. Our Diffs Agent runs on every PR, adding, deprecating, and maintaining test cases as your code changes, with zero manual test maintenance. Our Executor agent then runs those planned tests against per-PR preview environments before the PR merges, and our Reviewer agent classifies each result as a real bug, an agent error, or a test-plan mismatch.
The structural difference matters here. Sentry sees a bug after a user hit it. Autonoma runs before users ever see the deploy. Both tools see a different class of bug. A JavaScript runtime exception from a race condition in production? Sentry catches that. A checkout flow that breaks when a product has a discount code applied? Autonoma catches that before it lands in prod.
We built this because "we don't have any QA" is the sentence we hear most often from our users. A 3-person team shipping fast should not have to choose between coverage and speed. Our agents handle the testing layer so engineers can stay in the build loop.
One engineer we work with put it plainly: running Autonoma alongside Sentry is a no-brainer once you see how many bugs get caught before deploy that would have become Sentry alerts the next morning. That is the job Autonoma is designed to do.
For a deeper look at how our agent pipeline works, see the autonomous testing platform writeup.
Checkly Synthetic
Checkly runs scheduled checks against your live endpoints and UI flows on a recurring schedule. Think: "every 5 minutes, log in as a test user and verify that the checkout flow completes." If the check fails, you get an alert before users do.
The honest pros: Checkly is excellent for catching degraded service quality in production, especially for API endpoints and critical user journeys. It fills a gap that neither Sentry nor E2E CI tests cover: ongoing production health.
The honest cons: Checkly does not test your app before deploy, it monitors it after deploy. It is a complement to pre-deploy testing, not a replacement. Writing and maintaining Checkly checks requires ongoing work from engineers.
Playwright
Playwright is the open-source E2E testing framework from Microsoft. It is powerful, well-maintained, and the de facto standard for writing browser-based E2E tests. If you want to write and own your E2E tests, Playwright is the best starting point.
The honest cons (and they matter for small teams): Playwright requires you to write and maintain every test. For a 3-person team shipping 20 PRs a week, a Playwright suite that no one maintains becomes a liability rather than a safety net. Tests go flaky. Tests go stale. The team starts marking tests as skipped until the suite is useless.
If you have the time and discipline to maintain a Playwright suite, it is excellent. If you do not, Autonoma runs on top of Playwright under the hood and handles the writing and maintenance for you.
Sentry alternatives cost comparison (2026)
Pricing changes. These figures are approximate based on publicly listed plans as of mid-2026. Self-hosted tools (marked SH) have infrastructure costs that vary.
| Tool | 1M events/mo | 10M events/mo | 100M events/mo | Self-host | Sentry SDK compatible |
|---|---|---|---|---|---|
| Sentry | $26/mo | ~$89/mo | ~$500+/mo | Yes (self-hosted) | Native |
| GlitchTip | Free (SH) / $9 cloud | Free (SH) / ~$29 cloud | Free (SH, infra cost) | Yes (BSD) | Yes (full) |
| Bugsink | Free (SH) | Free (SH) | Free (SH, infra cost) | Yes (OSS) | Partial (core SDKs) |
| Honeybadger | $29/mo | ~$99/mo | Custom | No | No (own SDK) |
| Rollbar | Free tier (limited) | ~$99/mo | Custom | No | No (own SDK) |
| Bugsnag | ~$47/mo | ~$299/mo | Custom | No | No (own SDK) |
| PostHog | Free (1M incl.) | ~$50/mo | ~$400/mo | Yes (OSS) | No (own SDK) |
| BetterStack | $25/mo (Logs tier) | ~$80/mo | Custom | No | No (own SDK) |
| SigNoz | Free (SH) | Free (SH) | Free (SH, infra cost) | Yes (Apache 2.0) | No (OTEL SDK) |
| Checkly | N/A (per check) | N/A (per check) | N/A (per check) | No | No (different category) |
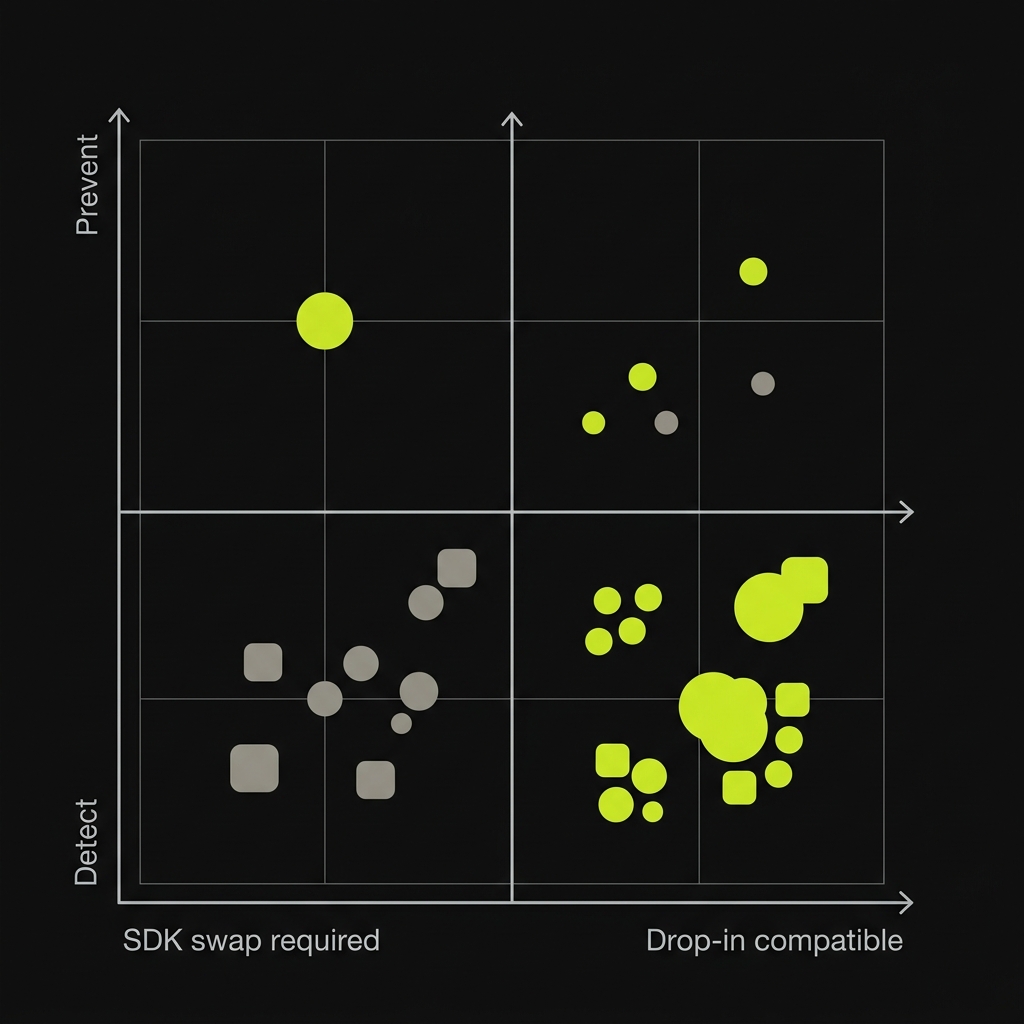
Drop-in compatibility matrix: which alternatives swap into Sentry.init
This is the most practical question for teams with an existing Sentry integration: can I change the DSN and move on, or do I need to rewrite my instrumentation?
| Tool | SDK swap (DSN only) | Code changes required | Source maps | Release tracking |
|---|---|---|---|---|
| GlitchTip | Yes | None (change DSN only) | Yes | Yes |
| Bugsink | Mostly | Minimal (verify platform) | Yes | Yes |
| Honeybadger | No | SDK swap required | Yes | Yes |
| Rollbar | No | SDK swap required | Yes | Yes |
| Bugsnag | No | SDK swap required | Yes | Yes |
| PostHog | No | SDK swap required | Yes | Limited |
| SigNoz | No | OTEL instrumentation | Via OTEL | Via OTEL |
The short version: if you want zero code changes, GlitchTip is the only fully Sentry-SDK-compatible option. Bugsink is close. Everyone else requires at least an SDK swap.
How Autonoma covers pre-deploy bug detection (the prevention layer)
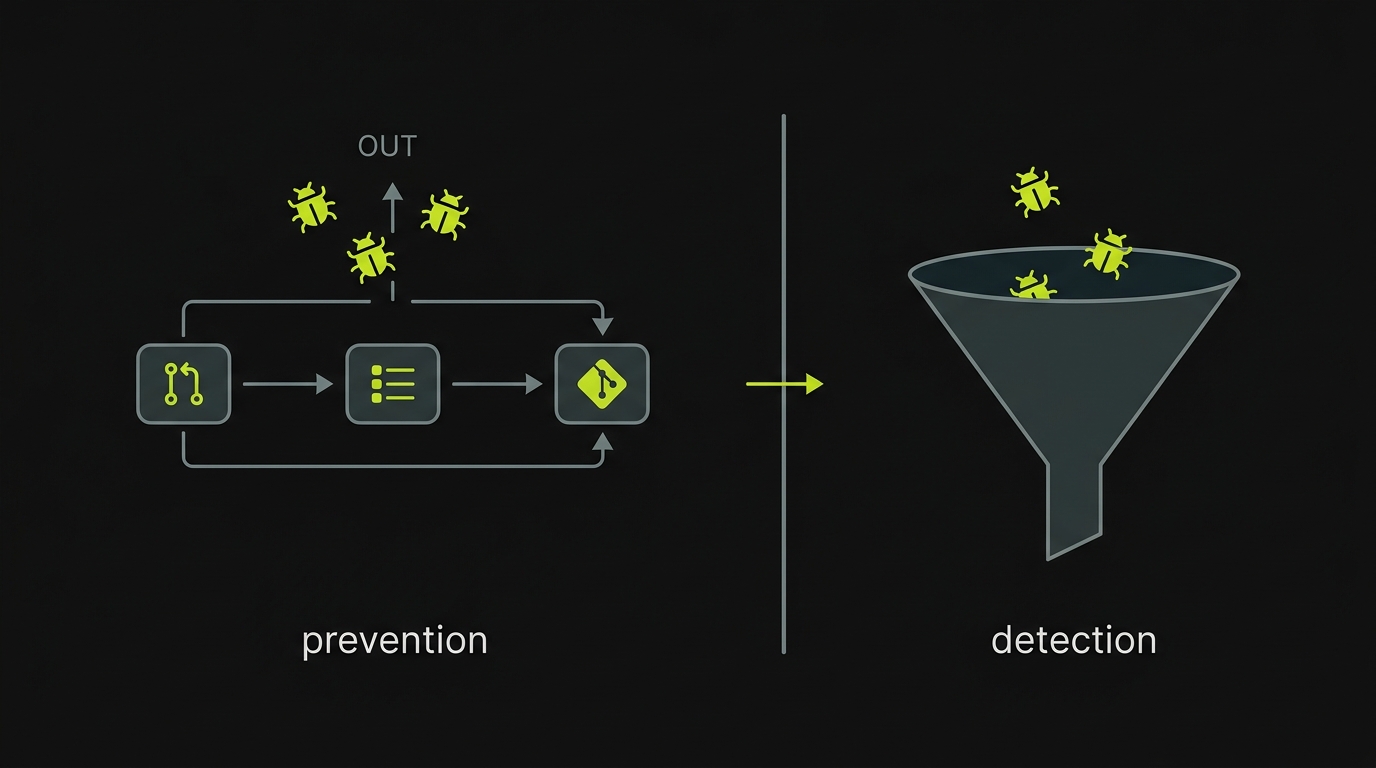
Error monitoring is a reactive safety net. Sentry catches bugs after they happen. That is valuable, and you should keep it. The problem we hear from small teams is not that Sentry fails at its job. The problem is that too many bugs reach Sentry in the first place, because "we don't have any QA" means nobody is systematically testing before deploy.
Autonoma is structurally different from every tool in categories 1 through 3. We are not a cheaper Sentry. We are the layer that runs before Sentry ever sees a bug.
Here is how our pipeline works. The Planner agent reads your codebase: routes, components, user flows, database models. It generates a test plan based on what your application actually does, not based on what you describe in plain language. The Diffs Agent runs on every PR, adding, deprecating, and maintaining test cases from the code diff, with no manual intervention. From there, the Executor agent runs the planned tests against a per-PR preview environment, and the Reviewer agent classifies each result as a real bug, an agent error, or a test-plan mismatch.
The coverage difference is structural. Sentry waits for a user to hit a broken flow. Autonoma runs the flow before the PR merges. A broken checkout that only appears when a discount code is applied, a form that submits twice under a specific race condition, a navigation guard that fails for users on a specific permission role: these are the bugs that reach Sentry because no automated test touched them. Our agents find them before deploy.
Autonoma is NOT a Sentry replacement. It does not capture runtime exceptions, does not replay production sessions, and does not alert on stack traces from live traffic. What it does is reduce the volume of bugs that reach production at all, which reduces the load on your error monitoring stack and reduces the number of incidents your team has to triage. Both tools belong in a complete safety net. They catch different classes of bug.
For more detail on how our agent architecture works, see how our agent pipeline catches bugs before deploy and the how Autonoma preview environments work explainer.
Sentry vs end-to-end testing: which one catches more bugs?
The honest answer is that they catch different classes of bug and the comparison is not useful. Sentry catches runtime errors that users encounter in production: unhandled exceptions, network failures, rendering errors from unexpected data shapes. E2E testing catches deterministic bugs that appear when a user follows a specific flow: broken forms, broken navigation, regressions in business logic.
A team that only has Sentry is blind to regressions until users hit them. A team that only has E2E testing is blind to runtime errors in production from edge cases no test covered. A complete safety net has both.
For a full treatment of when each tool type wins, search for "Sentry vs end-to-end testing" for third-party analysis, or check the Sentry docs on their recommended testing strategy.
How to pick a Sentry alternative in 2026
Start with the job-to-be-done. The four categories above are the decision tree, not the tool names.
- If your primary pain is cost and you want a drop-in: start with GlitchTip. Self-host it. Change the DSN. Done.
- If your primary pain is triage speed: Rollbar or Bugsnag. Budget for the migration effort (SDK swap required).
- If you want errors bundled with analytics and session replay: PostHog. Especially if you already use it.
- If you want full observability with self-hosting: SigNoz. Budget for the ops investment.
- If your primary pain is bugs reaching production at all: add a pre-deploy testing layer. This is the prevention layer that categories 1 through 3 do not address. Look at Autonoma for automated E2E, Checkly for synthetic production monitoring, and Playwright if you have the discipline to maintain a test suite yourself.
Most teams at Seed to Series A need Sentry (or a drop-in) AND at least one prevent-not-just-detect tool. The two categories are not competitors. The question is not "which one do I pick." The question is "which Sentry alternative fits my error monitoring budget, and what am I doing about the bugs that are reaching it in the first place."
Most teams shopping for Sentry alternatives are solving the wrong problem. If bugs are reaching Sentry frequently enough that the bill is painful or the triage is overwhelming, the root cause is often that too many bugs are reaching production at all. A cheaper Sentry does not fix that. It just makes the symptom cheaper.
The teams we work with at Autonoma who get the most leverage are the ones who treat error monitoring and pre-deploy bug detection as separate jobs with separate tools. Sentry stays in the stack because runtime error capture is non-negotiable. Autonoma runs before deploy to catch bugs before they reach Sentry. The prevention layer reduces the noise. The safety net stays complete.
If you are evaluating alternatives because the bill is too high: GlitchTip is the honest answer. If you are evaluating alternatives because too many bugs keep reaching production: the problem is not Sentry. The problem is coverage before deploy.
FAQ
Yes. Error monitoring is still load-bearing for any production application. Sentry's issue grouping, source map support, performance monitoring, and integrations (GitHub, Slack, PagerDuty) remain the benchmark. The open-source self-hosted version exists if the pricing is the concern. For most teams, the question is not whether to use error monitoring but whether Sentry specifically fits the budget and complexity trade-off.
GlitchTip is free if you self-host. It is fully Sentry-SDK-compatible (change only the DSN) and runs on a $5 VPS. If you want errors bundled with product analytics and do not want to self-host anything, PostHog's free tier covers 1 million events per month and includes error tracking alongside session replay and funnels.
Yes. Pre-deploy E2E testing on preview environments is the most systematic approach. When a test runs against every PR before it merges, a class of bugs (broken flows, regressions, form errors) never makes it to production. Autonoma automates this layer without requiring you to write or maintain tests. Playwright is the open-source option if you have the capacity to own the test suite yourself.
Yes. E2E tests catch deterministic bugs in tested flows before deploy. Sentry catches runtime errors that users hit in production from untested paths, unexpected data shapes, and edge cases that no test covered. They are not redundant. A complete safety net has both a prevention layer (E2E testing) and a detection layer (error monitoring). Removing either one leaves a gap.
No. Autonoma is pre-deploy E2E testing. Sentry is post-deploy error monitoring. Autonoma does not capture runtime exceptions, does not replay production sessions, and does not alert on stack traces from live traffic. What Autonoma does is reduce the number of bugs that reach production in the first place, which reduces the load on your Sentry queue. Both belong in a complete safety net. They catch different classes of bug.



