
An end to end testing strategy is the set of decisions governing which user flows get E2E coverage, when those tests run in your CI/CD pipeline, how fast they must complete, and how they stay accurate as your product changes. For teams shipping AI-generated code, the strategy must answer a harder version of these questions: AI writes features faster than humans can scope tests for them, so every decision about E2E scope, placement, and maintenance is magnified. A working e2e testing strategy for AI-augmented teams requires risk-based coverage prioritization, differentiated pipeline placement (pre-merge vs. post-merge vs. scheduled), test selection by changed surface area, and architecture that adapts without constant human intervention.
The teams shipping confidently at 40 or 50 PRs a week with AI coding tools aren't running faster test suites. They've changed what the suite is responsible for. They're not trying to cover every flow manually. They're not waiting for engineers to write E2E tests after the fact. They've rebuilt the strategy around the actual constraint: AI generates surface area faster than any human-driven testing process can track.
The result is a pipeline where E2E tests cover the flows that matter, run in time that doesn't block deployment, and stay current even when AI rewrites a feature from the front end down. It's not magic. It's a different set of architectural decisions about what E2E should own, how it should be triggered, and what generates the tests in the first place.
If you've already worked through the broader test automation strategy for AI-generated code, this goes deeper on the end to end testing layer specifically. Whether you're figuring out e2e testing for AI code for the first time or rebuilding a strategy that stopped working, this covers the full decision framework. E2E is the slowest, most expensive, and most fragile part of the pyramid. Fixing it is what unlocks the ability to actually ship at AI velocity without trading away confidence.
What Actually Belongs in E2E
The instinct when coverage is incomplete is to add more E2E tests. Usually that's wrong.
E2E tests are expensive -- in execution time, in maintenance, and in flakiness. Every test you add to this layer compounds those costs. The question is not "should this flow be tested" but "which layer should test it." The answer depends on what the test is actually verifying.
E2E belongs at the boundary where the system integrates with a real user's behavior. That means: multi-step flows that cross multiple services, authentication and authorization paths, checkout and payment completion, onboarding sequences, and any flow where the correctness of the result depends on the full stack being wired correctly. These flows cannot be adequately verified by unit or integration tests because the failure modes only emerge when all the pieces run together.
Integration tests, by contrast, are the right layer for API contract verification, service-to-service behavior, and component logic that doesn't depend on the browser DOM or real network conditions. They're faster, more isolated, and cheaper to maintain. This aligns with the principle behind Martin Fowler's test pyramid: push as much verification as possible to faster, cheaper layers, and reserve E2E for what only E2E can catch. If a test is failing because a query returns the wrong shape, that's integration territory, not E2E. For a detailed comparison of when to use each, see our integration vs E2E testing breakdown, and for the full testing pyramid decision framework.
The practical decision rule: if the test would pass even if the UI rendered incorrectly, it doesn't belong in E2E. If the test would pass even if a downstream API returned the wrong status, it doesn't belong in integration. Apply this filter aggressively to your existing suite and you'll often find 30-40% of tests in the wrong layer.
| Scenario | Right Layer | Reason |
|---|---|---|
| User completes checkout across 4 steps | E2E | Full stack must be wired correctly; correctness only visible end-to-end |
| API returns correct user object shape | Integration | No browser, no UI dependency; isolated service behavior |
| Auth token correctly scopes resource access | E2E or Integration | E2E if browser session state is critical; integration otherwise |
| Form validation shows correct error message | Component or Integration | UI logic doesn't require full stack; faster to test in isolation |
| Email confirmation sent after signup | E2E | Crosses multiple services; only end-to-end validates the full chain |
| Database query returns paginated results | Integration | No browser dependency; tests data layer behavior directly |
The E2E Scope Explosion in AI-Augmented Teams
Here is what happens to E2E scope when AI writes the code.
A human engineer shipping a new feature typically writes one new flow, maybe touches two or three existing ones. The E2E surface area per PR is bounded by how much one person can build in a sprint. You can reason about it manually.
An AI coding agent generating a feature from a spec can produce a complete checkout flow, the admin dashboard to manage it, the notification system that fires on completion, and the API endpoints that tie them together -- all in a single PR. Each of those pieces has user-facing flows. Each of those flows, if critical enough, belongs in E2E. The scope isn't one flow, it's five.
Multiply this by forty PRs per week and you have a combinatorial explosion. You cannot write E2E tests at the same velocity AI writes features. The traditional approach to e2e test automation, where humans write end to end tests after the feature is built, fails completely at this pace. By the time a manual test is written, two more features have shipped.
This is why risk-based prioritization is not a nice-to-have for AI-augmented teams; it's the only way to stay sane. You cannot cover everything. The question is whether you cover the right things.
When to Run E2E Tests in CI/CD
Placement is one of the highest-leverage decisions in your end to end testing strategy because it governs the feedback loop for every developer on the team. Put tests in the wrong place and you either slow everyone down or find bugs too late to fix cheaply.
There are three practical positions: pre-merge, post-merge, and scheduled.
Pre-Merge E2E Tests
Pre-merge means E2E runs as a required check before a PR can be merged. The benefit is immediate: developers get signal before their code reaches main. The cost is also immediate: every PR waits for the full E2E suite to complete. At 40 PRs/week, if your suite takes 15 minutes, you're consuming roughly 10 hours of CI time per week on E2E alone -- and blocking developers while they wait. Pre-merge E2E is only viable for a small, fast, high-confidence subset of tests, typically the golden path flows (more on that shortly).
Post-Merge E2E Tests
Post-merge means E2E runs after code lands on main, but before it reaches production. The feedback loop is delayed, which means a failure requires a rollback or a hotfix rather than a quick pre-merge fix. The trade-off is speed: developers aren't blocked waiting, and you can run a much larger test suite without gating throughput. Post-merge is the right position for the bulk of your E2E coverage.
Scheduled E2E Regression Runs
Scheduled runs, typically every four to eight hours against a staging environment, are where your comprehensive regression suite lives. These catch slow-drift failures: things that didn't break in any single PR but accumulated across several. They're also where you run the tests that are too slow or environment-dependent to fit in the merge pipeline at all. See our guide on running tests in a 40-PR-per-day pipeline for specific CI configuration patterns.
The decision framework comes down to two variables: how fast is the test, and how catastrophic is the failure. Fast tests covering catastrophic-failure scenarios belong pre-merge. Slow tests covering lower-risk scenarios belong scheduled. Everything else belongs post-merge.
| Placement | Feedback Latency | Best For | Risk If Skipped |
|---|---|---|---|
| Pre-merge | Minutes (blocks merge) | Golden path flows, auth, payments | Critical regressions ship to main |
| Post-merge | 15-30 min after merge | Broad feature coverage, secondary flows | Failures require rollback not revert |
| Scheduled | 4-8 hours | Full regression, slow tests, cross-flow state | Slow regressions accumulate undetected |
For teams shifting E2E earlier in the pipeline, the key constraint is not willingness but execution time. Shifting left only works if your pre-merge E2E budget stays under 5 minutes. That's a hard constraint, not a guideline.
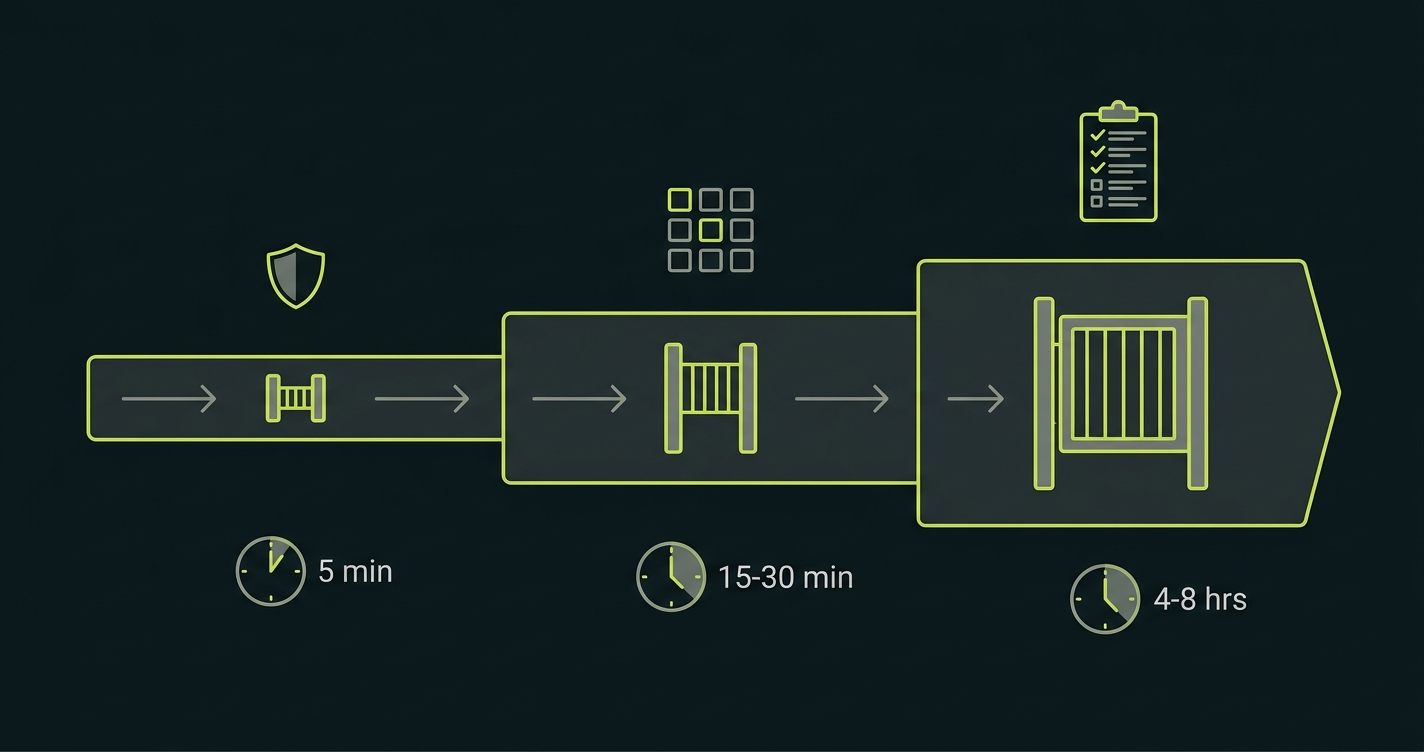
Keeping E2E Fast at Scale
Five minutes for pre-merge E2E at 40 PRs/week is an aggressive target. The challenge of e2e testing at scale comes down to one principle: run fewer tests per PR, faster.
"Fewer tests per PR" does not mean less coverage. It means smarter selection. The principle is simple: a PR that only changes the checkout flow should not trigger the full suite -- it should trigger the E2E tests that cover the checkout flow, and skip the tests for search, authentication, and admin that it didn't touch. Test selection by changed surface area is the single highest-leverage optimization available to teams at scale.
Implementing this well requires knowing the mapping between source files and the E2E tests that cover them. That's non-trivial to maintain manually when AI is generating code at volume. The mapping changes with every PR.
This is exactly the problem we built Autonoma to solve. Our Planner agent reads your codebase to understand which routes, components, and flows exist, then selects and runs only the E2E tests relevant to what changed in a given PR. When a PR touches the payment flow, Autonoma runs the payment tests. When it touches the admin dashboard, it runs those. The full suite runs on schedule. Pre-merge runs in minutes. No one has to maintain the mapping manually -- the agent re-derives it from the code on every run.
Parallelization
Parallelization is the other lever. A suite that takes 20 minutes serially can run in 4 minutes across five parallel workers. Most modern E2E frameworks support parallel execution natively, including Playwright's built-in sharding and Cypress's parallel mode. The constraint is usually infrastructure cost and test isolation: parallelized tests must not share state, or they'll flake unpredictably. If your tests share a database without cleanup between runs, parallelization will create race conditions that look like flakiness but are actually state corruption.
The Golden Path Pattern
The golden path pattern is a design principle, not a tool. The idea: identify the 5-10 user flows that must work for your product to function, and keep those tests fast, isolated, and always pre-merge. Everything else can be slower and lower-priority. The golden paths are your smoke tests. They don't prove the product is bug-free; they prove the product is alive. For a team shipping 40 PRs/week, a sub-5-minute golden path suite running on every PR is more valuable than a comprehensive 45-minute suite that everyone skips because it's too slow.
Risk-Based Coverage: What Actually Needs E2E
Comprehensive end to end testing coverage is a myth for teams at AI velocity. Not because coverage doesn't matter -- it does -- but because the maintenance burden of comprehensive coverage at this pace outweighs the benefit. The goal is not maximum coverage; it's maximum coverage of the flows that matter most.
Risk-based coverage prioritization works from two variables: business impact if the flow breaks, and probability of the flow breaking given recent change rate.
Business impact is usually straightforward to rank. A broken checkout flow is a revenue loss with a direct dollar value. A broken admin filter is an inconvenience. Broken onboarding stops new users from activating. Broken password reset locks users out. These flows are not equal, and your E2E coverage should reflect that inequality. The highest-impact flows get the most thorough, most frequently-run coverage. Lower-impact flows get lighter coverage or none at all.
Probability of breaking is trickier. The most useful proxy is recent churn rate: how often has this area of the codebase changed in the last 30 days? Stable code that nobody touches has low probability of breaking regardless of business impact. Code that's being actively rewritten by AI agents has high probability of breaking even if it was fine last week. Combine these two variables and you get a prioritization matrix that tells you where to invest E2E effort.
| Business Impact | Change Rate | Coverage Decision |
|---|---|---|
| High | High | Deep E2E coverage, pre-merge, scheduled regression |
| High | Low | Stable E2E coverage, post-merge, less frequent regression |
| Low | High | Lightweight E2E or integration coverage, post-merge |
| Low | Low | Skip E2E; cover at unit or integration level if at all |
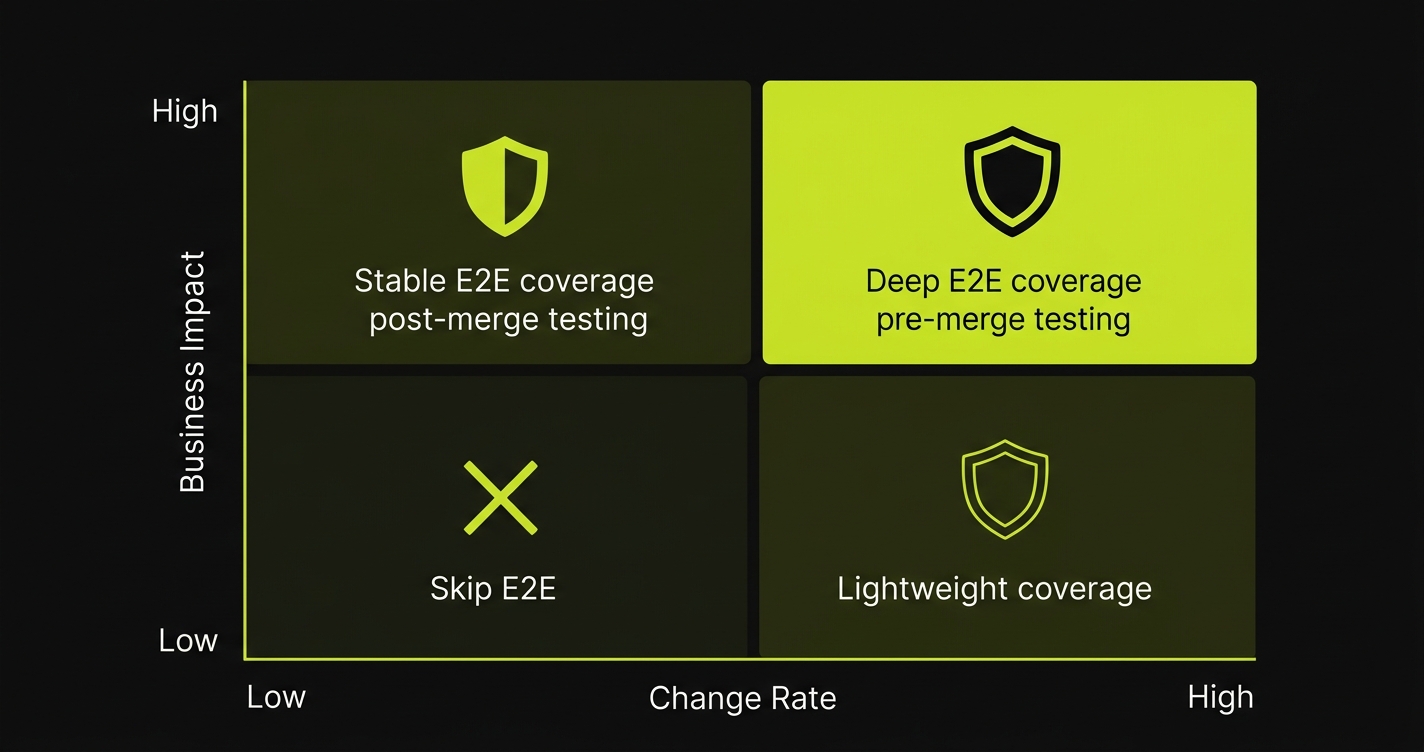
Apply this matrix to your existing suite. You'll find tests in the top row running only on schedule while tests in the bottom-right row run pre-merge. That's backwards. Rebalancing placement and depth based on this framework typically cuts E2E execution time by 30-50% while improving actual coverage of high-risk flows.
Autonoma implements risk-based selection automatically — the Planner agent maps coverage against your codebase's change rate, running only the tests relevant to what changed in a given PR.
E2E Test Data: The Hidden Failure Point
E2E tests fail on data more often than on code. This is the part of e2e testing best practices that gets the least attention and causes the most pain.
A multi-step E2E flow -- user signs up, verifies email, completes onboarding, adds payment method, makes purchase -- requires a specific database state at every step. The user must exist. The email must be verifiable. The onboarding state must be at the right point. The payment method must be addable. If any of that state is wrong, the test fails in a way that has nothing to do with whether the feature works.
The naive approach is to rely on the state left behind by a previous test: Test 1 creates the user, Test 2 assumes it. This creates invisible coupling between tests. When Test 1 is skipped or fails, Test 2 fails for unrelated reasons. Run the suite in parallel and the coupling creates race conditions. Run tests in a different order and half the suite breaks.
The correct approach is test-level state independence: every test sets up exactly the state it needs before running, and cleans it up after. This requires a reliable mechanism for seeding database state. For a deep dive on this specifically, see our guide on test data seeding for E2E flows.
In practice, there are three viable approaches. Direct database seeding is the fastest: insert the rows you need before the test, truncate them after. It works well for simple state but becomes unwieldy for complex interdependent objects (a user with an organization, with members, with billing history, with feature flags). Factory patterns help here: a createUserWithOrg() function that encapsulates the full creation chain. The third approach is API-driven setup: call your own application's APIs to create the state, the same way a real user would. This is slower but more realistic -- and it catches bugs in your setup flows that direct database access would hide.
The test data challenge is especially acute for AI-generated features because AI tends to generate happy-path implementations. It creates the flow assuming the happy-path database state exists. The edge cases -- expired sessions, partial completions, conflicting state -- are where real users break things and where your test data setup needs to be most disciplined.
E2E Architecture: Page Objects, Component-Based, and AI-Adaptive
The architecture of your E2E tests determines how brittle they are. This is the layer where teams make decisions early and then live with them for years.
Page Object Model (POM)
The page object model is the established pattern: create a class for each page that encapsulates selectors and interactions. Tests call page object methods instead of raw selectors. When the UI changes, you update the page object, not every test that touches that page. POM works well when pages are stable. It breaks down when AI generates UI at volume, because every generated component may have slightly different DOM structure, and maintaining page objects becomes a full-time job.
Component-Based Architecture
Component-based architecture adapts better to component-driven UIs. Instead of page-level objects, you create test helpers aligned with your component library. A LoginForm test helper knows how to interact with that component wherever it appears -- login page, checkout sidebar, modal. This is more maintainable when your UI is built from a consistent component library, which AI-generated code often is (since agents tend to reuse existing components rather than invent new ones).
AI-Adaptive Testing
AI-adaptive testing is where the architecture question gets interesting for teams at scale. The premise: instead of hardcoding selectors, tests describe intent -- "find the submit button in the payment form," "locate the error message for invalid email" -- and the test runner resolves those descriptions against the current DOM. When the DOM changes, the test doesn't break; the resolution adapts. This is the approach we take with Autonoma. Our Maintainer agent watches for UI changes in each PR and updates test targeting automatically, so tests don't require human intervention every time a class name changes or a component is restructured.
Regardless of which e2e testing tools your team uses, the architectural decisions above determine whether tests survive at scale. For teams evaluating specific frameworks, see our comparison of Playwright alternatives and the full e2e testing tools landscape for a complete picture of what's available.
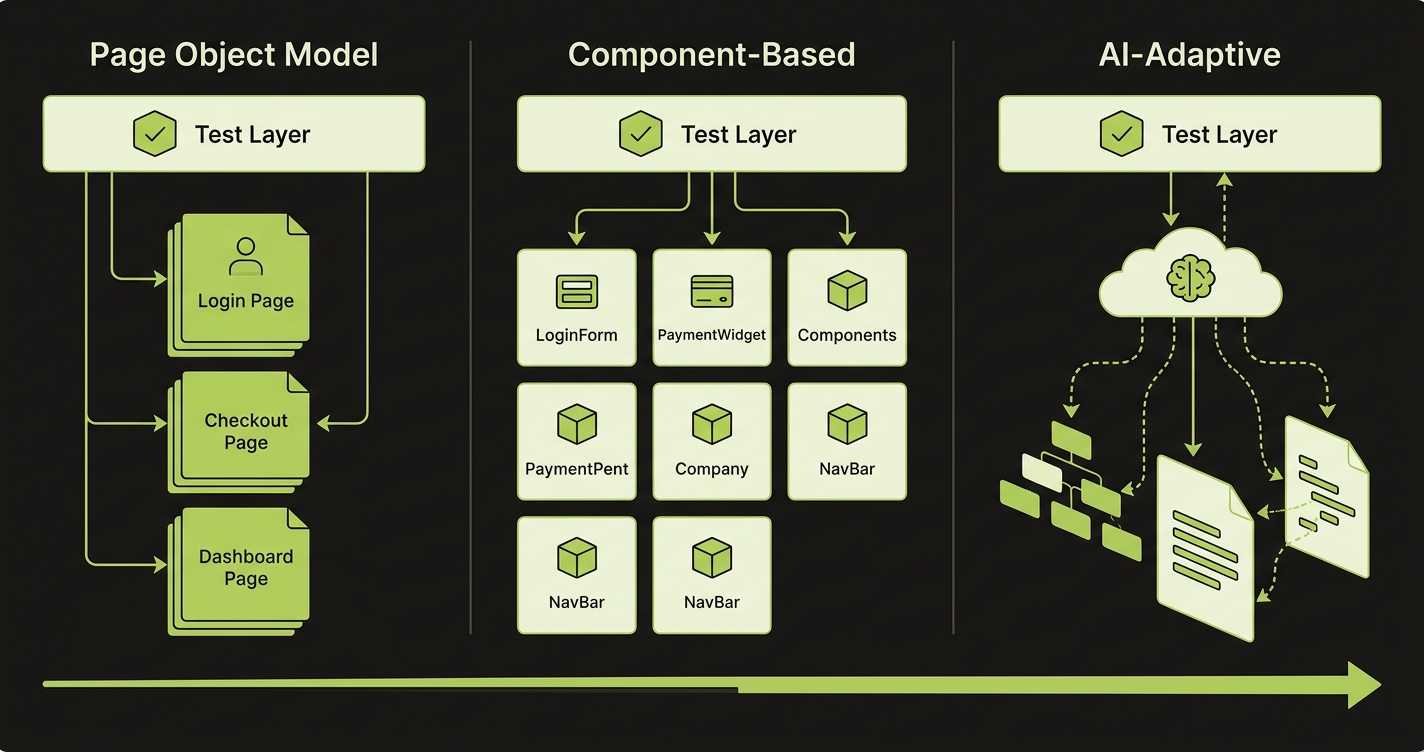
The practical recommendation: start with component-based architecture if you're building from scratch, use POM if you have a large existing suite and migration cost is prohibitive, and move toward AI-adaptive approaches as your team's E2E volume grows beyond what humans can maintain.
E2E Testing Metrics That Show Your Strategy Is Working
A strategy without measurement is guesswork. These are the metrics that actually tell you if your e2e testing approach is functioning.
Mean Time to Detection (MTTD)
Mean time to detection is how long after a bug is introduced before a failing test catches it. If your MTTD is 24 hours, bugs are reaching users before tests catch them. If it's 10 minutes, your placement is working. MTTD is calculated by comparing the timestamp of the first failing test run with the timestamp of the commit that introduced the bug. Track this over time. It should decrease as you shift more tests pre-merge.
False Positive Rate
False positive rate measures how often a test fails when the application is actually correct. Every false positive costs engineering time to investigate and erodes trust in the suite. A suite with a 20% false positive rate is functionally ignored -- engineers learn to re-run until it passes rather than investigating failures. Target below 2%. If you're above 5%, your suite has a flakiness problem that's costing more than the bugs it catches.
Coverage of Changed Surface Area
Coverage of changed surface area is the hardest to measure but most important. For each PR, what percentage of the changed user flows had E2E coverage at the time of merge? If AI is generating three new flows per PR and you're covering one, your coverage of new surface area is 33%. This metric forces the question of whether your test generation is keeping pace with feature generation.
Suite Execution Time Trend
Suite execution time trend is a leading indicator of scaling problems. If your pre-merge suite grew from 3 minutes to 8 minutes over the last quarter, you'll be at 20 minutes within six months. Catching this trend early -- and addressing it with selection, parallelization, or layer migration -- is much cheaper than fixing a broken pipeline under pressure.
Flake Rate by Test Age
Flake rate by test age reveals maintenance debt. Tests written more than six months ago tend to have higher flake rates than recent tests, because the UI has drifted from when they were written. High flake rates on old tests are a signal that your maintenance strategy isn't working -- either tests need to be updated, deleted, or moved to a different architectural approach.
A minimal measurement setup: log test results with timestamps and PR metadata, track flake rate per test file over rolling 30-day windows, and alert when any pre-merge test exceeds a 5% flake rate. This doesn't require expensive tooling -- a simple database table and a weekly review is enough to catch the patterns that matter.
FAQ
End to end testing (also called E2E testing) is a software testing method that validates complete user workflows from start to finish, across the full application stack. Unlike unit tests (which test individual functions) or integration tests (which test service interactions), E2E tests simulate real user behavior in a browser or device, verifying that the frontend, backend, APIs, and database all work together correctly. Common examples include testing a checkout flow, user signup, or authentication sequence.
The most impactful e2e testing best practices are: prioritize tests by business risk rather than code coverage percentage; keep pre-merge E2E suites under 5 minutes by using test selection based on changed surface area; ensure every test is state-independent (sets up and tears down its own data); use stable selectors like data-testid attributes rather than CSS classes; run comprehensive regression on a schedule rather than blocking every PR; and track five key metrics -- mean time to detection, false positive rate, coverage of changed surface area, suite execution time trend, and flake rate by test age.
Coverage percentage is a misleading metric for E2E. A team with 40% coverage of the right flows is in better shape than one with 80% coverage of low-impact flows. Focus on coverage of your critical business flows -- checkout, auth, onboarding, core user actions -- rather than raw percentage. Once those are covered with confidence, expand based on the risk matrix: high business impact and high change rate flows get prioritized next.
Only a small subset should block merges: your fastest, most critical golden path tests. Full E2E suites should not gate merges at 40 PRs/week -- the throughput cost is too high. The right model is a fast pre-merge smoke test (under 5 minutes), post-merge comprehensive coverage, and scheduled full regression. This lets you catch the most critical failures before they hit main while keeping developer velocity high.
Brittleness is almost always caused by over-reliance on specific DOM selectors (CSS classes, XPath, element positions) that change whenever UI is updated. The fix is designing tests around stable semantic selectors: aria-labels, data-testid attributes, and role-based queries. For teams generating UI at AI velocity, AI-adaptive test maintenance -- where the test runner automatically re-resolves intent to the current DOM -- is the only approach that scales without constant human intervention.
The golden path is the set of 5-10 user flows that must work for your product to function at all. Checkout, login, signup, core feature activation -- the flows a user must be able to complete for your product to have value. Golden path tests are kept fast (ideally under 5 minutes total), always run pre-merge, and are treated as blocking. They are not comprehensive; they are a smoke test that proves the product is alive. Everything beyond the golden path runs post-merge or on schedule.
AI-generated features tend to be happy-path complete but edge-case sparse. The features work when state is perfect; they often break when state is partial, expired, or conflicting. This means your test data setup needs to be more explicit, not less -- you can't assume the AI covered the edge cases in the implementation. Every E2E test should set up its own state independently rather than relying on state from other tests, and your seeding mechanisms need to handle complex object graphs, not just simple row inserts.
At 5 engineers, a shared E2E suite with manual maintenance is viable. At 50 engineers shipping AI-generated code, it's not. The scaling inflection points are: at 10-15 engineers, implement test ownership and split the suite by domain; at 20-30 engineers, require test selection by changed surface area so pre-merge runs stay fast; at 40+ engineers, the only sustainable approach is automated test generation and maintenance, since the human cost of keeping tests current exceeds the value of writing them manually.
Five metrics cover your end to end testing strategy: mean time to detection (how quickly a test catches a bug after introduction), false positive rate (flakiness), coverage of changed surface area per PR, suite execution time trend over time, and flake rate by test age. MTTD tells you if your placement is right. False positive rate tells you if your suite is trusted. Coverage of changed surface area tells you if you're keeping pace with AI-generated features. Execution time trend is a leading indicator of scaling problems. Flake rate by age surfaces maintenance debt.



